

1. 서 론
2. 관련 연구
3. 연구 방법 및 실험 설정
3.1 데이터셋 및 전처리
3.2 U-Net 기반 회귀 모델
3.3 DDIM 기반 확률 모델
3.4 자기회귀 롤아웃 설정
4. 예측 성능 비교 결과
4.1 정량적 예측 정확도 비교
4.2 난류 구조 및 통계 보존 특성 비교
4.3 추론 비용 및 활용상 고려사항
5. 논 의
6. 결 론
1. 서 론
고정밀 난류 유동장의 장기 시계열 예측은 공기역학, 해양 및 기상 예측, 에너지 시스템 등 다양한 분야의 핵심 과제이나, 난류 고유의 강한 비선형성과 다중 스케일 구조로 인해 직접 수치 모사(direct numerical simulation, DNS)나 큰 에디 모사(large eddy simulation, LES)와 같은 고해상도 해석에는 막대한 계산 비용이 소요된다. 이러한 한계를 극복하기 위해 데이터 기반 대리 모델 및 기계학습 예측기가 활발히 연구되어 왔으며[1,2], 특히 convolutional neural network(CNN) 및 U-Net 계열의 모델은 난류 유동장의 예측, 복원 및 초해상도 재구성 분야에서 널리 활용되고 있다[3,4,5,6].
장기 예측 수행 시에는 단일 스텝 예측기를 반복적으로 적용하는 자기회귀 방식의 시간 적분이 일반적으로 사용되는데[7,8,9,10,11], 이때 시간 간격 의 설정은 예측의 난이도와 누적 오차의 증가를 동시에 결정짓는 주요 인자이다. 가 작을 경우 목표 물리 시간 도달에 필요한 스텝 수가 증가하여 오차 누적의 위험이 커지는 반면, 가 클 경우 단일 스텝 내에서 요구되는 동역학적 변화량이 급증하여 미세 스케일의 소실이나 통계적 왜곡이 발생할 수 있다[12]. 따라서 의 변화에 따라 결정론적 회귀 모델과 확률적 생성 모델이 장기 예측 시 나타내는 오차의 양상(평활화 현상, 통계적 드리프트 등)과 그 상충 관계를 정량적으로 비교·분석할 필요가 있다.
한편, 확산 모델(diffusion models)은 데이터 분포를 학습하고 샘플링을 수행함으로써, 결정론적 회귀 모델에서 빈번히 발생하는 평활화 경향을 완화하고 미세 난류 구조의 통계적 특성을 보존할 가능성이 보고된 바 있다[13,14,15,16,17]. 그러나 다단계 샘플링에 따른 높은 계산 비용은 실용화의 걸림돌로 작용하고 있어, 실제 유동 예측 문제에서 설정에 따른 정확도, 안정성, 통계적 보존 성능 및 계산 비용 간의 균형을 동일한 조건 하에서 검증할 필요가 있다.
또한 실제 관측 및 데이터 저장 환경에서는 3차원 난류장 전체를 실시간으로 확보하기 어려우며, 제한된 단면이나 부분 관측 데이터만을 기반으로 차기 상태를 추정해야 하는 경우가 빈번하다. 이에 본 연구에서는 부분 관측 상황을 가정하여, Johns Hopkins Turbulence Databases(JHTDB)[18,19]의 강제 등방성 난류(forced isotropic turbulence) DNS 데이터에서 z-중앙 단면(x-y 평면)을 추출하고, 해당 단면 격자상의 3성분 속도 벡터를 입력으로 하는 잔차 기반 자기회귀 예측 문제를 구성하였다. 이는 면외 상호작용 정보가 누락된, 물리적으로 닫히지 않은 조건부 예측 문제에 해당한다. 본 연구는 완전한 3차원 예측기의 구현보다는, 이러한 불완전 정보 하에서 결정론적 모델과 확률적 모델이 불확실성을 처리하는 방식을 비교하고 분석하는 데 주안점을 둔다.
본 논문의 주요 기여는 다음과 같다. (i) 고정된 물리 시간 T를 기준으로 다양한 조건에서 U-Net과 확산모델의 장기 예측 성능을 동일 조건 하에 비교하여, 의 변화가 누적 오차 및 단일 스텝 예측 난이도에 미치는 영향을 체계적으로 규명한다. (ii) 단순 픽셀 기반 오차 지표(mean squared error(MSE), structural similarity measure(SSIM), peak signal-to-noise ratio(PSNR))뿐만 아니라 난류 에너지 스펙트럼 및 와도 probability density function(PDF)와 같은 물리적 통계량을 함께 분석하여, 두 모델의 미세구조 보존 능력과 통계적 타당성을 평가한다. (iii) 샘플링 기반 생성 모델의 계산 비용을 정량적으로 제시하고, 정확도-안정성-비용 측면에서의 실용적 상충 관계를 고찰한다.
2. 관련 연구
유동장 예측 및 대리 모델링 분야에서는 데이터 기반 접근법의 기술적 동향과 한계점에 대한 체계적인 고찰이 이루어져 왔으며[1,2], 난류 문제 해결을 위해 합성곱 신경망(CNN)을 활용한 유동 구조의 학습, 예측, 복원 및 초해상도 재구성 연구가 활발히 수행되었다[3,4,5,6]. 특히, 인코더-디코더 구조를 기반으로 하는 U-Net 아키텍처는 다중 스케일 유동 특징 추출에 탁월한 성능을 입증하며 다양한 난류 재구성 문제에서 표준적인 비교 기준으로 자리 잡았다[6]. 최근에는 거칠기 정보만으로 항력 관련 스칼라를 예측하고, 특징 맵을 통해 항력 유발 구조의 공간적 패턴을 도출하는 등, 물리적 해석 가능성을 강화한 합성곱 신경망 기반 접근도 보고되었다[20].
또한, 유동의 상태를 직접 예측하는 대신 잔차를 학습하는 방식은 모델의 학습 안정성과 일반화 성능을 향상시키는 유효한 대안으로 제시되었으며[21], 이는 장기 시간 적분 시 발생하는 누적 오차의 특성을 분석하는 데에도 중요한 통찰을 제공한다. 나아가 수치해석적 이산화 및 보존 법칙을 신경망 설계에 반영하여 시간 전진 예측을 수행하고, 이를 통해 비정상 computational fluid dynamics(CFD) 해석을 가속화하려는 연구도 제안되었다[22].
이 외에도 데이터 기반 전산유체 해석 및 기계학습 기법 적용을 종합적으로 정리한 리뷰가 보고된 바 있으며[23], 물리 기반 신경망 또는 데이터 기반 모델을 활용하여 전산유체 해석 결과를 보정·재구성하는 등 복잡한 비정상 유동 문제에 대한 적용 사례도 제시되어 있다[24]. 아울러 공기역학적 유동 예측에서 신경망의 해석 가능성과 신뢰성을 높이기 위해 어텐션 기반 설명가능 신경망을 적용한 연구가 보고되었고[25], 기계학습을 통해 기존 수치해석 절차를 보조하거나[26] 계산 결과를 신경망을 통해 효율적으로 재구성하는 방법론[27] 등 다양한 연구가 시도되고 있다.
장기 예측 안정성은 혼돈적 시스템에서 특히 중요한 이슈이며, 자기회귀 롤아웃에서는 작은 단일 스텝 오차가 장기적으로 증폭될 수 있음이 반복적으로 보고되어 왔다[7,8,9,10,11]. 이러한 문제를 완화하기 위해 학습 시 입력 분포를 점진적으로 롤아웃 분포에 맞추는 scheduled sampling이 제안되었고[28], 물리 모델과 학습 모델을 결합하는 하이브리드 예측 또한 혼돈계 예측에서 유효한 전략으로 제시되었다[10]. 더 나아가, 데이터로부터 혼돈계의 안정성을 분석하거나[8], 난류/연소 등 복잡 유동에서 장기 예측 프레임워크를 강화하려는 시도도 이루어지고 있다[7,11]. 특히 입력 데이터의 시공간 상관과 시간 간격이 신경망의 학습 용이성과 예측 성능을 좌우할 수 있으며, 자기상관 및 상관계수 분석을 통해 그 영향을 정량화하려는 연구가 보고되었다[29]. 이러한 연구들은 장기 롤아웃이 단순한 단일 스텝 정확도만으로 설명되지 않으며, 시간 간격 선택과 오차 증폭 특성을 함께 고려해야 함을 시사한다.
확산 모델은 점진적 노이즈 주입과 역과정을 통해 데이터 분포를 학습하는 생성 모델로, 다양한 영역에서 강력한 샘플 품질을 보여 왔다[13,14,15,16]. Denoising diffusion implicit models(DDIM)은 샘플링 과정을 결정론적으로 단순화하여 추론 단계 수를 줄이는 접근이며[16], 최근에는 지식 증류(distillation) 등을 통해 수 스텝 수준으로 가속하려는 연구도 진행되고 있다[17]. 유동/시공간 예측에서도 확산 기반 모델이 분포 수준의 재현 및 장기 롤아웃 오류 감소에 기여할 가능성이 논의되었고[9], 반복적 보정을 통해 장기 예측을 개선하려는 흐름도 제시되었다[30]. 다만 확산 모델은 샘플링 단계 수에 따라 비용이 크게 달라지므로, 변화와 결합될 때 정확도·안정성·비용의 트레이드오프를 동일 조건에서 비교하는 정량 분석이 필요하다.
마지막으로, 대규모 난류 DNS 데이터의 활용은 데이터베이스 인프라에 크게 의존하며, JHTDB는 난류 데이터 공유 및 분석을 위한 대표적 공개 플랫폼으로 활용되어 왔다[18,19]. 본 연구는 JHTDB 강제 등방성 난류 DNS 데이터를 기반으로, 고정 물리 시간 에서 변화에 따른 결정론적(U-Net) 모델과 확률적(DDIM) 모델의 거동 차이를 정량 지표와 물리 통계량을 함께 사용해 비교함으로써, 장기 롤아웃 관점의 모델 선택 기준을 보다 명확히 제시한다.
3. 연구 방법 및 실험 설정
3.1 데이터셋 및 전처리
본 연구 데이터 처리 및 자기회귀 예측 과정의 개요는 Fig. 1(a)에 도식화되어 있다. 데이터셋으로는 JHTDB의 강제 등방성 난류DNS 데이터셋 isotropic1024coarse(3D 10243 격자)를 사용하였다. 각 시간 스냅샷의 3D 속도장에서 추출한 x-y 단면(2D 격자) 위에 3성분 속도 를 채널로 쌓아, 형태의 단면 속도장을 구성하였다. 시간 간격 는 데이터 프레임의 추출 간격으로 정의하여 을 고려하였다. 학습 대상은 잔차 이며, 총 4000 프레임을 시간 순서대로 train/val/test=3200/400/400로 분할하였다. 3차원 난류를 2차원으로 절단하면 평면 밖 상호작용이 누락되어 물리 방정식이 닫히지 않는 한계가 있으므로, 본 설정은 불완전 정보 하에서의 불확실성 처리 및 통계량 보존 능력을 검증하기 위한 실험으로 정의한다.
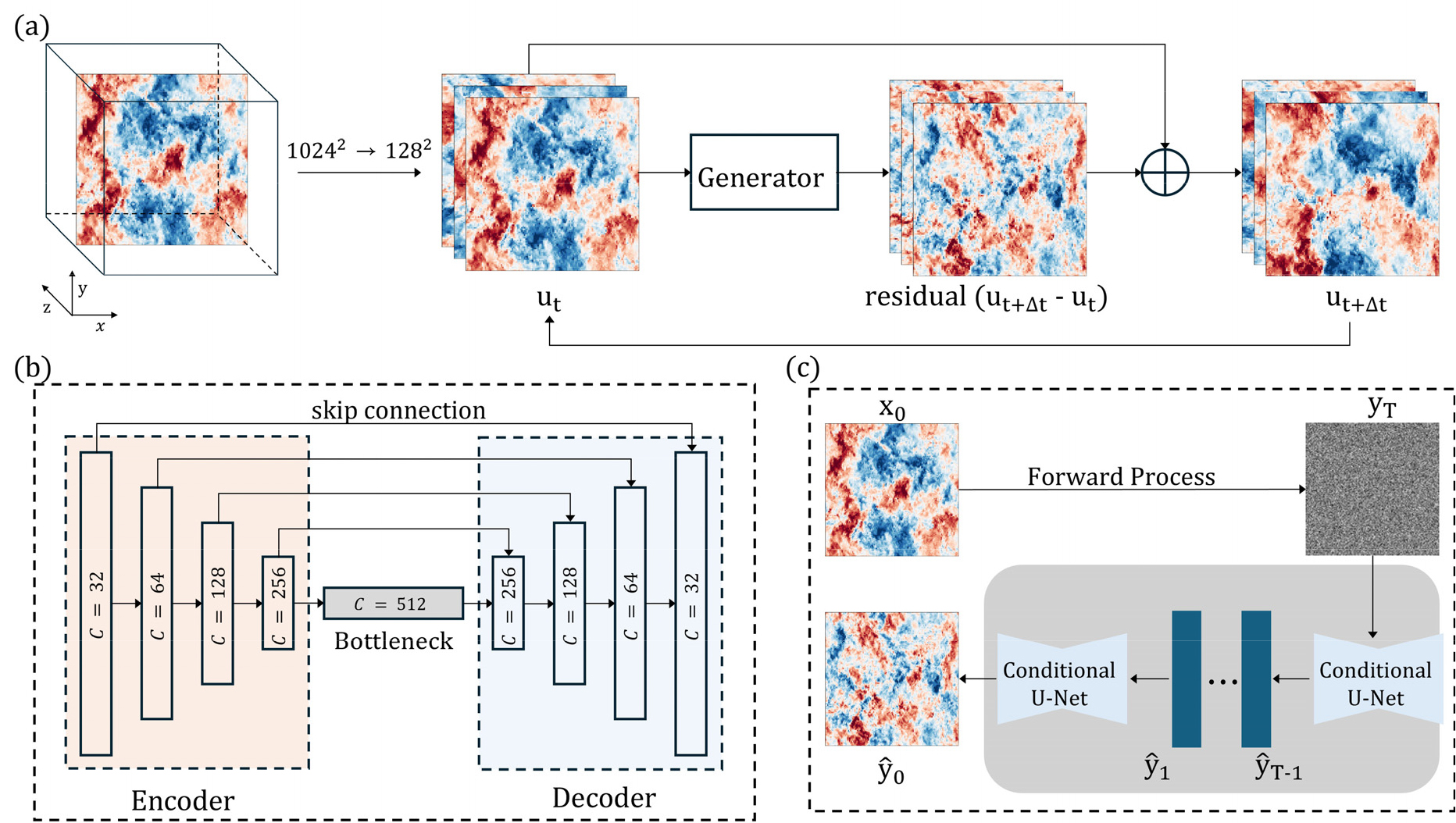
3.2 U-Net 기반 회귀 모델
결정론적 비교 모델로 사용된 U-Net의 상세 아키텍처는 Fig. 1(b)와 같다. U-Net은 4단계 인코더-디코더 구조(채널 32-512)를 갖춘 결정론적 회귀 모델로 설계되었다. 각 블록은 3×3 Convolution, GroupNorm, ReLU 연산을 포함하며, 2×2 Max-pooling과 Transposed Convolution을 이용해 피처 맵의 크기를 조절한다. 모델은 입력에 대한 잔차를 추정하여 롤아웃을 갱신하는 방식으로 학습된다. 최적화 알고리즘으로는 AdamW()를 채택하였고, 일반화 성능 향상을 위해 EMA(0.999) 및 Early Stopping(patience 50)을 도입하였다(Batch size=32).
3.3 DDIM 기반 확률 모델
본 연구에서는 확률적 생성 모델로 DDIM을 채택하였으며, 그 구체적인 학습 및 샘플링 메커니즘은 Fig. 1(c)에 도식화되어 있다. 이 모델은 조건부 분포 를 근사하여 잔차 를 샘플링한다. 구현은 조건부 U-Net(기본 채널 32)을 백본으로 사용하고, 시각 t를 시간 임베딩으로 주입하여 역확산 과정에서 단계별 노이즈를 제거한다. 최종 예측은 잔차의 샘플(또는 평균)로 얻으며, 롤아웃은 U-Net과 동일하게 로 수행된다. 본 연구에서는 샘플링 스텝 수를 고정하고(세부 설정은 구현과 동일), 동일한 초기조건에서 Δt에 따른 자기회귀 예측의 안정성과 통계량 보존을 비교하였다. 확산 과정은 denoising diffusion probabilistic models(DDPM) 학습 타임스텝 1000, DDIM 샘플링 스텝 100으로 설정하였다. 또한 예측 방식은 속도 예측(v-prediction)을 사용하고, p2-weighting(𝛾=0.5)을 적용하였다.
3.4 자기회귀 롤아웃 설정
자기회귀 롤아웃은 고정 물리 시간 기준으로 수행하였다. 기준 시간간격 =1에서의 롤아웃 길이를 라 할 때, 각 에 대해 를 동일하게 유지하도록 롤아웃 스텝 수 로 설정하였다.
두 모델 모두 자기회귀 방식으로 롤아웃을 수행하였다. 초기 조건 에서 시작하여, 각 스텝에서 예측된 잔차 를 더해 다음 상태를 로 생성하고 이를 다음 입력으로 사용한다. 정량 지표(MSE/SSIM/PSNR)는 (u,v,w) 3성분에 대해 계산하였다. SSIM/PSNR은 각 프레임별 DNS 결과의 동적 범위()를 기준으로 계산하였다. 또한 속도 성분을 채널 차원으로 지정하여 SSIM을 산출하였다. 물리적 일관성 평가는 (i) 운동에너지 의 상대 오차(Relative Energy Error), (ii) 2D FFT 후 방사 평균으로 계산한 에너지 스펙트럼 , (iii) 예측된 속도장으로부터 계산한 z-방향 와도 의 PDF를 사용하였다. 모든 지표는 롤아웃 프레임에 대해 평균하여 제시하였으며, 학습과 동일하게 채널별 정규화(평균/표준편차 기반) 된 변수 공간에서 역정규화 과정 없이 계산하였다. 따라서 본 지표들은 무차원 값이며, 물리 단위로의 변환은 동일한 정규화 계수로 복원 가능하다.
4. 예측 성능 비교 결과
4.1 정량적 예측 정확도 비교
본 연구는 JHTDB forced isotropic turbulence 데이터에서 U-Net(결정론적)과 DDIM(확산 기반 생성 모델)의 자기회귀 예측을 수행하고, 에서의 성능 변화를 비교하였다. 자기회귀 예측에서는 한 스텝의 오차가 다음 입력으로 누적되므로, 단일 프레임 정확도만으로 장기 안정성을 판단하기 어렵다. 고정 물리 시간 에서 를 증가시키면 단일 스텝 예측 난이도는 증가하지만, 동시에 롤아웃 길이 가 감소하여 누적 오차 축적은 완화된다. 따라서 Table 1의 픽셀 기반 지표는 에 대해 단조 경향을 보장하지 않으며, (i) 픽셀 지표와 (ii) 통계량 보존(에너지/스펙트럼/와도 PDF)을 함께 해석해야 한다.
필드 오차 지표는 예측장과 DNS 결과값 간의 공간적 차이를 정량화한다. Δt 증가에 따라 두 모델 모두 성능 저하가 나타나며, 그 경향은 지표별로 다르게 관측된다. 다만, 고정 물리 시간 T조건에서는 가 커질수록 롤아웃 스텝 수 가 감소하므로, Table 1의 픽셀 지표는 단일 스텝 난이도와 누적 오차 축적이 함께 반영된 값임에 유의해야 한다.
Table 1.
Rollout-averaged metrics by (autoregressive rollout).
Table 1에서 확산 모델의 상대 에너지 오차는 전반적으로 U-Net보다 낮게 유지되지만, =25에서 일시적으로 증가하는 비단조적 경향이 관찰된다. 이는 해당 간격에서 조건부 분포의 불확실성이 커지거나, 고정된 샘플링 스텝 수가 일부 구간에서 충분하지 않을 가능성을 시사하며, 특히 큰 에서는 조건부 정보가 부족해지므로, 생성적 복원 과정이 물리적 제약을 부분적으로 벗어나 에너지를 과대(또는 과소) 평가하는 왜곡된 유동 구조를 만들 가능성도 존재한다.
다만 난류 예측에서는 평균적으로 비슷해 보이는 결과라도, (a) 과도한 평활화로 미세 구조가 사라지거나, (b) 수치적 불안정으로 진폭이 비정상적으로 커지는 현상이 나타날 수 있어 물리적 안정성 검증이 필요하다. 이를 위해 에너지를 다음과 같이 정의한다.
여기서 는 단면 내 공간 평균된 운동에너지이다. 정의된 상대 오차 는 예측장이 DNS 결과값의 에너지 수준을 과도하게 증폭(수치적 불안정성)하거나 감쇠(과도한 소산)시키는지를 직접적으로 진단한다. 본 연구의 결과는 가 커질수록 U-Net에서 구조적 왜곡 및 에너지 편향이 커질 수 있는 반면, 확산 모델은 상대적으로 안정적인 경향을 보임을 시사한다.
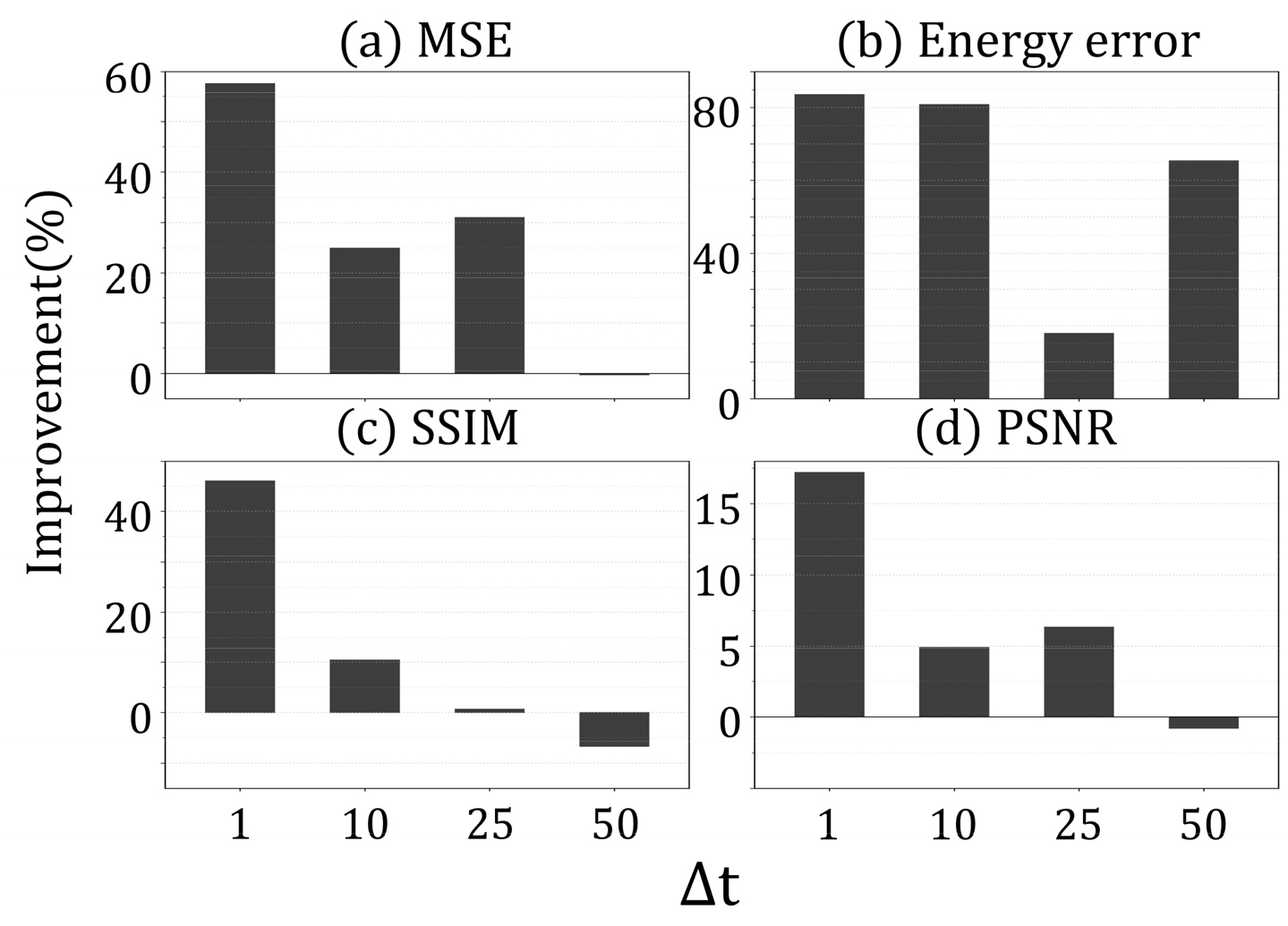
Table 1의 지표를 바탕으로 확산 모델의 U-Net 대비 상대 개선율을 Fig. 2에 정리하였다. 전반적으로 확산 모델이 모든 지표에서 우위를 보이며, 특히 상대 에너지 오차의 개선 폭이 가장 크게 나타난다. 정량 지표는 평균적 예측 성능을 요약하는 데 유효하나, 증가에 따라 오차가 공간적으로 어떤 형태로 누적되는지(공간적 위상 오차, 미세 구조 소실, 비물리적 패턴 발생)를 직접적으로 설명하기에는 한계가 있다. 이에 본 연구에서는 각 조건에서 롤아웃 마지막 프레임의 속도 성분 u,v,w 를 DNS 결과와 함께 비교하여, 시간 누적 오차가 유동 구조에 미치는 영향을 정성적으로 점검하였다(Fig. 3). DNS 결과값은 모든 에서 동일하므로, Fig. 3의 좌측 열에 한 번만 제시하고 우측에 별 U-Net과 확산 모델의 결과를 연속적으로 배치하였다.
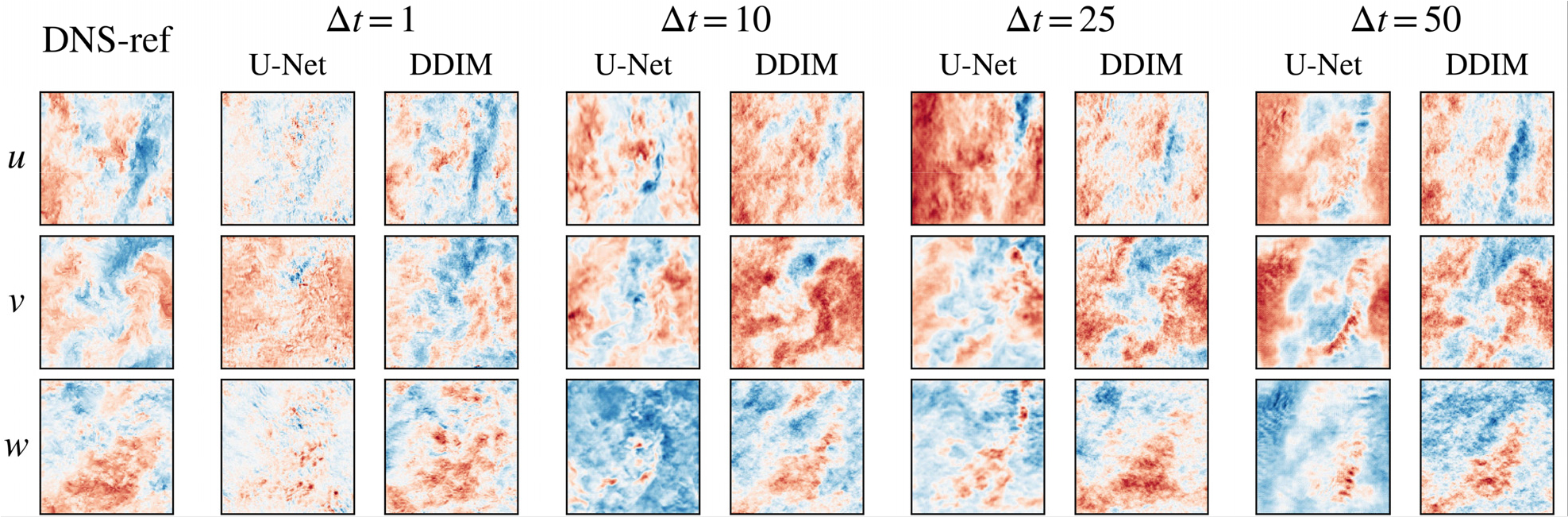
Fig. 3에서 가 커질수록 U-Net은 미세 구조가 빠르게 평활화(smoothing)되거나 공간적 위상 오차가 누적되는 경향이 뚜렷하며, 큰 에서는 국소적으로 인공적인 패턴이 나타나 DNS 결과와의 형태적 유사도가 저하된다. 반면 확산 모델은 큰 스케일 구조의 배치와 대비를 상대적으로 유지하고, 과도한 평활화가 완화되어 오차가 전역적으로 확산되는 양상이 감소한다. 이러한 정성적 차이는 스펙트럼 및 분포 기반 지표(에너지 스펙트럼, 와도 PDF)에서 확인되는 확산 모델의 물리 통계 보존 경향과도 일관된다.
4.2 난류 구조 및 통계 보존 특성 비교
필드 오차(MSE, PSNR, SSIM)는 공간적 패턴의 유사도를 정량화하지만, 난류 예측의 물리적 타당성을 검증하기 위해서는 스케일별 에너지 분포와 와도 구조가 올바르게 유지되는지를 확인해야 한다. 따라서 본 연구에서는 에너지 스펙트럼 와 와도 PDF를 통해 모델의 물리 통계 보존성을 평가하였다. 는 각 프레임의 속도장 (u,v,w)에 대해 2차원 고속 푸리에 변환(2D FFT)을 수행한 뒤, 파수 크기 에 따른 방사형 평균을 통해 등방성 스펙트럼으로 환산하고, 전체 자기회귀 전개 구간에 대해 평균하여 산출하였다(Fig. 4).
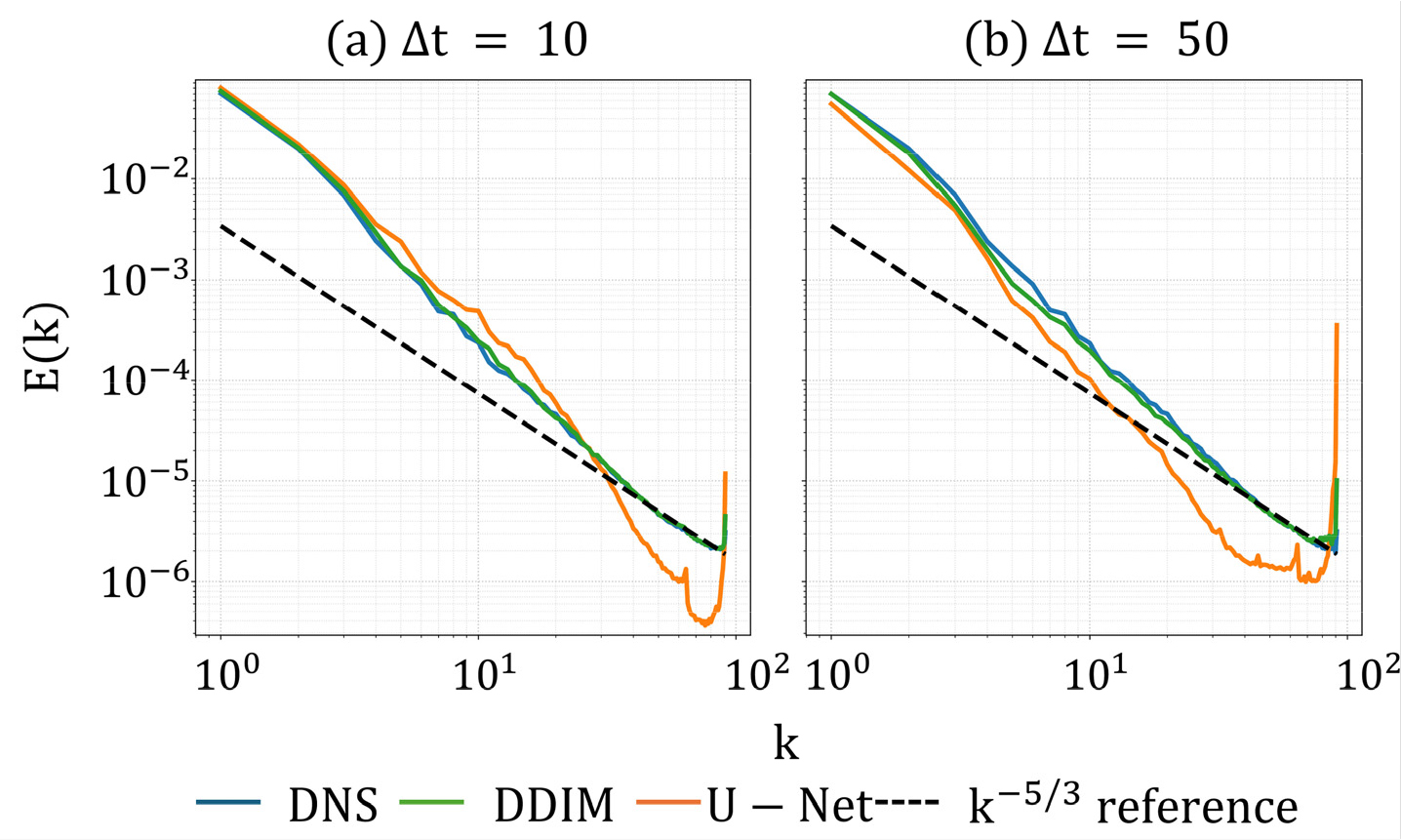
Fig. 4의 검은색 점선은 콜모고로프 가설에 따른 관성 영역에서의 에너지 케스케이드 기울기 을 나타낸다. DNS 결과(파란색 실선)는 이 이론적 기울기와 잘 일치하며 난류 에너지가 거대 스케일에서 미세 스케일로 올바르게 전이됨을 보여준다. 확산 모델(초록색 실선)은 가 증가하더라도(=50) 이 기울기를 고파수 대역까지 충실히 따르며 물리적 정합성을 유지하는 반면, U-Net(주황색 실선)은 중간 파수 대역 이후에서 에너지가 이론값보다 급격히 감소하는 과도한 소산 특성을 보인다. 이는 결정론적 모델의 평균화 경향이 미세 난류 구조를 억제하여 에너지 연쇄를 조기에 차단함을 시사한다. 다만, 고파수 영역(>80)에서 관측되는 에너지 상승은 에일리어싱 오차 또는 생성 모델의 확률적 샘플링 노이즈가 복합적으로 작용한 결과일 수 있다.
와도 PDF는 자기회귀 전개 구간의 모든 프레임을 누적하여 계산한 뒤 분포 형태를 비교하였다(Fig. 5). Fig. 5에서 가 증가할수록 두 모델 모두 DNS 결과와 비교해 분포의 중심부 피크 높이와 위치, 그리고 분포 폭에서 차이가 나타난다. 특히 U-Net은 가 큰 조건에서 피크가 과도하게 높아지거나 위치가 이동하는 경향이 관찰되는데, 이는 와도 변동의 분산이 과소평가되어 분포가 중심으로 과도하게 집중되는 현상(평활화 경향)과 일관된다. 반면 확산 모델은 가 증가하더라도 피크의 높이·위치 및 분포 폭이 DNS 결과와 상대적으로 더 유사하게 유지되는 경향을 보이며, 이는 공간 구조 비교에서 관찰된 과도한 평활화 완화와도 부합한다.
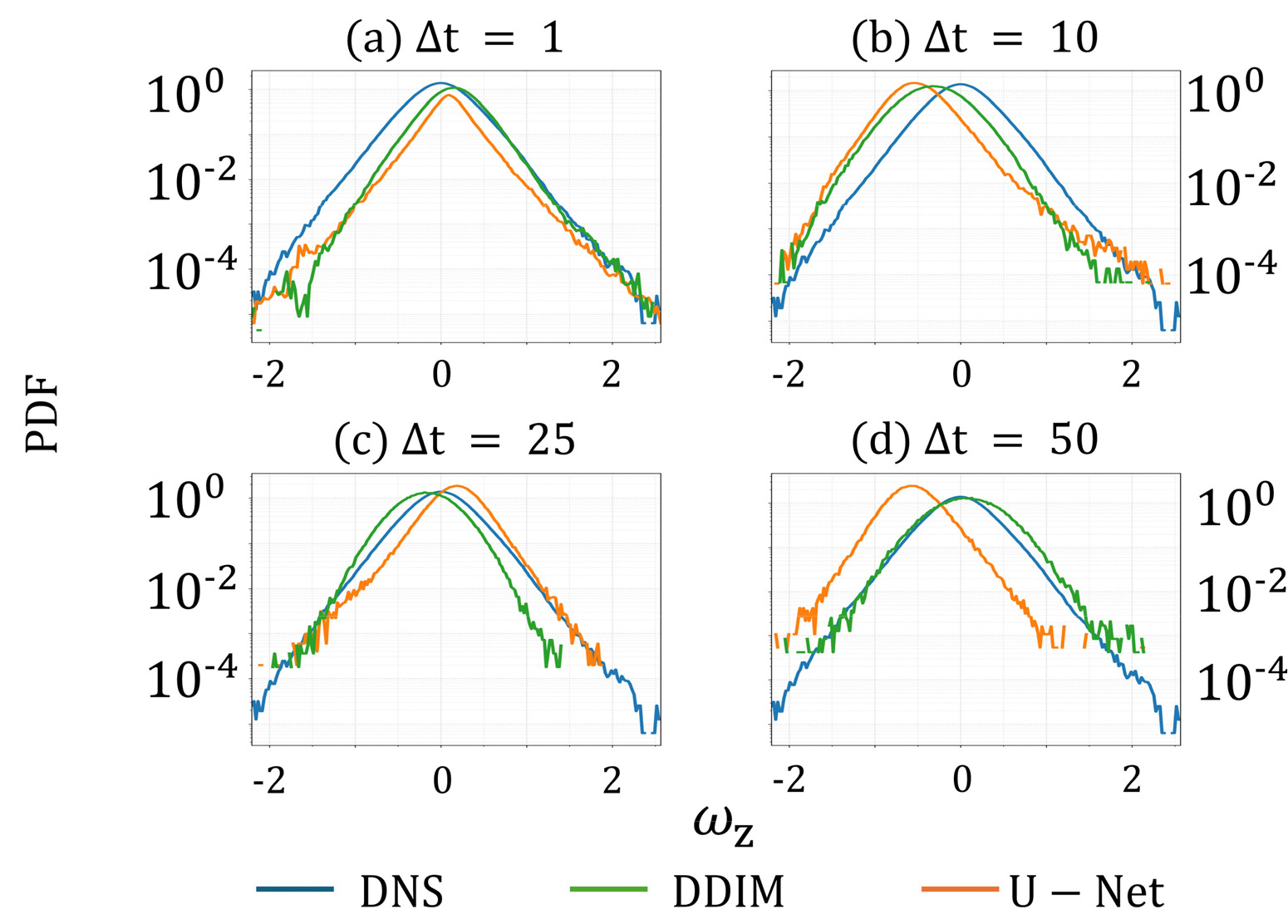
종합하면, 확산 모델은 필드 오차 지표뿐 아니라 에너지 스펙트럼과 와도 분포 비교에서도 U-Net보다 통계적 특성의 보존 정도가 전반적으로 높게 나타났다. 이는 가 큰 조건의 자기회귀 예측에서 확산 모델이 비교적 안정적인 대안이 될 수 있음을 보여준다.
4.3 추론 비용 및 활용상 고려사항
본 연구에서 사용하는 U-Net과 확산 모델은 기본 구조가 유사하나, 확산 모델은 1회 예측을 위해 역확산 과정을 여러 단계 반복하므로 추론 비용이 크게 증가한다. 추론 시간은 NVIDIA RTX 3090(24GB) 단일 GPU에서 배치 크기 1, FP32 조건으로 측정하였다. 1스텝 예측의 평균 추론 시간은 U-Net이 약 1.3-1.7 ms인 반면, 확산 모델은 100단계 샘플링 기준 약 140-150 ms로 측정되어 약 100배 느렸다. 따라서 확산 모델의 실용화를 위해서는 샘플링 단계 수를 줄이는 방법, 증류를 이용한 가속, 또는 다중 정밀도 전략(큰 스케일은 빠른 모델로 예측하고 미세 스케일은 확산 모델로 보정하는 방식)과 같은 계산 효율 개선이 필요하다.
5. 논 의
연구를 통해 자기회귀 난류 예측에서 시간 간격 의 영향과 모델 타입(결정론적 U-Net vs 확률적 확산 모델)에 따른 예측 특성 차이를 상세히 비교하였다. 주요 결과와 이에 대한 물리적, 실용적 고찰은 다음과 같다.
첫째, 본 연구에서 사용된 JHTDB 데이터가 3차원 등방성 난류의 2차원 슬라이스라는 점은 예측 문제의 본질적인 어려움을 시사한다. 3차원 난류의 단면은 질량 보존이나 운동량 보존 법칙이 해당 평면 내에서만 닫혀있지 않고, 평면 밖 유동과의 상호작용이 존재한다. 따라서 2차원 정보만으로 다음 스텝을 예측하는 것은 수학적으로 불완전한 문제이다. 그럼에도 불구하고 확산 모델이 U-Net보다 통계량 보존이 우수했던 이유는, 2D 단면만 주어진 조건에서 조건부 분포의 불확실성을 샘플링으로 모델링하는 생성모델 특성이 롤아웃 안정성에 유리하게 작용했기 때문일 수 있다. 조건부 분포의 불확실성이 클수록 결정론적 모델은 조건부 기댓값으로 수렴하여 미세 구조를 소실하는 반면, 생성 모델은 분포의 모드 부근에서 물리적으로 그럴듯한 샘플을 생성할 수 있기 때문이다. 따라서 본 연구에서 관측된 확산 모델의 우위 폭은 2차원 부분 관측이라는 높은 불확실성 조건에 기인한 바가 크며, 3차원 전체장과 같이 불확실성이 낮은 조건에서는 두 모델 간 격차가 축소될 가능성이 있다. 이는 3차원 전체장에서는 물리 방정식이 닫혀 조건부 분포의 불확실성이 감소하므로, 결정론적 모델의 과소산 문제가 완화될 수 있기 때문이다. 또한 본 연구는 강제 등방성 난류만을 대상으로 하였으므로, 비등방성이 강한 유동에서는 결론이 달라질 수 있으며 향후 검증이 필요하다.
둘째, Δt 구간별 성능 격차의 원인은 시간 상관 구조와 오차 누적의 비대칭성으로 설명된다. Δt가 작을수록 인접 프레임 간 상관이 높아 단일 스텝 예측은 용이하나, 롤아웃 스텝 수 N=T/Δt가 커져 오차 누적의 기회가 극대화된다. 이때 U-Net의 평활화 현상은 스텝 수에 비례하여 곱해지므로 Δt=1에서 에너지가 지수적으로 감쇠하여 상대 에너지 오차가 0.8878까지 증가하는 반면, 확산 모델은 역확산 과정의 단계별 노이즈 제거를 통해 예측 결과를 데이터 분포 방향으로 보정하여 동일 조건에서 0.1459를 유지한다(Table 1). 또한 Δt가 증가할수록 잔차 Δx의 분포의 분산이 커지고 꼬리가 두꺼워져 MSE 기반 회귀는 조건부 평균으로 붕괴하는 반면, DDIM은 조건부 분포 자체를 샘플링하므로 이러한 변화에 강건하다. 결과적으로 Δt가 작은 구간에서 두 모델 간 격차가 극대화되고, Δt 증가에 따라 누적 스텝 수 감소로 픽셀 기반 지표의 격차는 축소되지만, 에너지 스펙트럼 및 와도 분포에서는 전 Δt 구간에서 확산 모델의 우위가 유지된다(Fig. 4, 5). 이는 픽셀 기반 오차만으로는 난류의 통계적 성질 보존 여부를 충분히 판단하기 어려우며, 물리 통계량 기반 평가가 병행되어야 함을 시사한다.
셋째, 계산 효율 측면에서 본 연구의 확산 모델은 U-Net 대비 약 100배의 추론 시간이 소요된다는 한계가 확인되었다. 이는 U-Net이 단일 단계로 예측을 수행하는 반면, 확산 모델은 설정된 100회의 반복적인 노이즈 제거 과정을 거치기 때문이다. 실시간 제어와 같이 즉각적인 응답이 필요한 응용 분야에서는 이러한 비용이 제약이 될 수 있다. 그러나 단순한 정확도보다 물리적 통계량의 보존이 필수적인 고정밀 오프라인 해석이나, 앙상블 예보를 위한 데이터 증강 분야에서는 이 비용이 충분히 정당화될 수 있다. 향후 연구에서는 이러한 계산 비용 문제를 완화하기 위해 샘플링 스텝을 줄이는 기술이나 지식 증류 기법을 도입하여, 확산 모델의 물리적 정합성과 계산 효율성 사이의 균형을 맞추는 시도가 요구된다.
6. 결 론
본 연구에서는 자기회귀 난류 예측 과제에서 시간 간격 와 모델 종류(U-Net vs 확산 모델)에 따른 성능 및 예측 특성을 체계적으로 비교하였다. forced isotropic turbulence(JHTDB) 데이터를 사용한 실험 결과, Table 1의 롤아웃 평균 지표 기준으로, 확산 모델은 U-Net 대비 MSE를 평균 28.3% 감소시키고, 상대 에너지 오차를 평균 61.9% 감소시켰다. 확산 모델은 에 관계없이 난류장의 에너지 스펙트럼 형상을 실제에 가깝게 유지하며, 오차 누적에 따른 와도 분포 붕괴도 억제하였다. 이는 확산 모델이 가지는 노이즈 제거 및 다중스케일 재현 능력이 난류 예측에서 유용함을 입증하는 결과라 할 수 있다. 다만 이러한 정확도 향상은 큰 계산 비용을 동반하여, 실시간 난류 해석 등에는 추가적인 최적화가 필요하다. 향후 연구에서는 3차원 난류장에 대한 검증, 다양한 난류 모델(예: RANS/LES 데이터)로의 확장, 그리고 확산 모델의 효율화 기법 개발이 진행되어야 할 것이다. 그럼에도 불구하고, 본 비교 연구는 딥러닝 난류 예측 모델의 강점과 약점을 난류 물리 관점에서 고찰하였다는 점에서 의의가 있다. 확산 모델과 결정론적 모델의 상보적 장점을 활용한다면, 향후 안정성과 효율을 지닌 확산 모델이 불완전한 물리 정보를 다루는 차세대 난류 예측 솔루션으로서 중요한 잠재력을 가질 수 있다.
