

1. 서 론
2. 유동장 모델링 및 해법
3. 유동장 모델링 및 해법FDS의 병렬처리
3.1 MPI
3.2 OpenMP
4. 결 과
4.1 문제 설정
4.2 결과 비교
4.3 성능 비교
4.4 해석 결과 검증
5. 결 론
1. 서 론
Fire Dynamics Simulator(이하 FDS)는 화재로 구동되는 유체 유동 현상을 해석하기 위해 전산 유체역학 기법을 도입해 Fortran 프로그래밍 언어로 작성된 화재 모사 전용 프로그램이다. FDS는 화재로 인한 연기 및 열전달에 중점을 둔 저속의 열 구동 유동에 적합한 Navier-Stokes 방정식을 수치적으로 해석한다[1, 2, 3]. 따라서 FDS는 기본적인 화재 역학 및 연소를 연구할 수 있는 모델을 제공한다. FDS는 실제적인 화재 문제를 해석하는데 목표를 두고 미국 국립표준기술연구원에 의해 개발되어 왔다. 국내에서는 2011년부터 성능위주설계 (performance-based design)의 시행에 따라 화재모사 프로그램이 건축설계에 활용되고 있다.
컴퓨터 전산처리 속도가 점차 빨라짐에 따라 화재시뮬레이션 분석 결과를 이용한 소방대원의 가상훈련에 접목하고 있다. 일반적인 게임에 널리 사용되는 파티클 시스템의 경우 열방출 속도와 중력장, 생존주기 등이 고려되지만 다양한 압력차가 발생하는 실제 물리기반 시뮬레이션을 기반으로 하지 않고 있으며[4, 5], Navier-Stokes 방정식을 이용한 시뮬레이션 적용은 계산속도 문제로 실시간이 아닌 애니메이션 제작용으로 응용되고 있다[6, 7]. 이후 국내에서는 2009년 처음으로 전산수치 해석기반 화재훈련 VR 시뮬레이터 개발이 연구되어진 바 있다[8].
이와 같이 화재훈련 시뮬레이션등에 수치해석 모델등이 활용되면서 준실시간성 해석을 위한 병렬화 효율성이 중요한 부분으로 다루어지고 있다[1]. FDS의 병렬화에 관한 연구에는 병렬화 환경 설정에 따른 차이를 보여주는 연구 [9]와 MPI의 계산효율이 OpenMP에 비해 높은 효율을 보여주는 연구[10]가 존재한다. 민수경등은 FDS를 통해 병렬화 모드에 따른 최적의 스레드 할당 및 해석 영역 분할의 최적 조건이 존재함을 보였다[11].
사용자는 화학반응 모델, 복사 모델, 부격자 모델 등 FDS가 제공하는 다양한 모델을 사용하여 화재 문제를 해석할 수 있다. 그러나 매우 상세한 물리적 현상을 확인하기 위해서는 계산 비용이 증가하게 된다. 이를 극복하기 위해 FDS는 중앙처리장치(이하 CPU)의 멀티 스레딩 유무와 관계없이 순차 또는 병렬로 다양한 하드웨어 플랫폼과 운영체제에서 실행되도록 작성되어 있다.
FDS는 메시지 전달 인터페이스(Message Passing Interface, 이하 MPI)[12, 13]를 사용하여 컴퓨팅 클러스터에서 해석 문제를 나누어 실행할 수 있게 되어 있다. 주된 골자는 해석할 전체 영역을 여러 개의 메쉬로 나누고 각 메쉬는 개별 컴퓨터에서 개별 프로세서로 계산하게 하는 방법이다.
여기에서 MPI는 프로세서 간의 정보 전송을 처리하는 역할을 수행한다. 일반적으로 각각의 메쉬는 각자의 MPI 프로세서로 할당되지만, 단일 프로세서에 다중 메쉬를 할당할 수 있다. 이와 같은 방식으로 큰 메쉬는 특정 프로세서를 전용으로 하여 계산할 수 있고, 적은 메쉬는 묶어서 하나의 프로세서에서 계산할 수도 있다.
FDS는 병렬해석 수행 시 먼저 각 계산 영역을 분산 메모리의 메쉬로 분해한 다음 각 메쉬 내에서 멀티 스레딩을 적용하는 2단계 병렬화를 지원하고, 멀티 스레딩을 구현하기 위해 OpenMP(Open Multi Processing, 이하 OpenMP) 라이브러리[14]를 사용한다.
FDS는 운영체제로 Linux, Windows, OSX, AIX를 지원하고, 컴파일러로는 GNU Fortran, Intel fortran, PGI Fortran, XL Fortran을 지원하며, MPI 라이브러리로는 Open MPI 및 Intel MPI를 지원하고 있다. 본 논문에서는 워크스테이션에 많이 사용되는 다중 코어 프로세서와 Linux 운영체제를 대상으로 FDS 버전 6.7.4의 병렬 성능을 컴파일러와 MPI 라이브러리에 대해 비교 평가하고자 한다. 병렬 성능해석 평가에 주로 많이 이용되는 3차원 열전달 문제를 대상으로 상용프로그램과 공개 프로그램인 OpenFOAM과 FDS에 대해 나타내고자 한다.
2. 유동장 모델링 및 해법
FDS는 저속의 열 구동 유동에 대해 보존 방정식을 계산하는 프로그램이다. 화재로 인한 연기 및 열전달이 FDS의 주요 관심사이며 열복사, 열분해, 연소, 화염 확산 및 스프링클러의 화재 억제에 대한 모델을 포함하고 있다. 질량, 화학종, 운동량 및 에너지 보존 방정식을 Table 1에 정리하였다.
여기서 는 액적 또는 입자의 증발에 의한 화학종의 생성률이고, 𝜌는 밀도이고, 는 속도 벡터이고, , , 는 각각 질량분율, 확산계수, 단위 체적당 𝛼 번째 화학종의 질량 생성률을 나타낸다. 는 압력이고, 는 외력 벡터이고, 𝜏는 점성 응력 텐서 그리고 는 현 엔탈피를 나타낸다. 은 화학반응으로 생성된 단위 체적당 열 방출률을 나타내고, 는 액적 증발에 전달되는 에너지를 포함하는 항이다.
3차원에 대해서 보존 방정식은 𝜌 밀도, 세 개의 속도 성분, 온도, 압력을 포함한 총 6개의 미지수를 가진다. 따라서 보존 방정식을 풀기 위해 추가적인 방정식이 필요하게 되고, 해석에 사용되는 기체가 열량적 완전기체일 경우 이상기체 상태 방정식을 적용할 수 있고 다음과 같이 나타낸다.
여기서 는 혼합기체의 몰 질량을 나타낸다. 보존 방정식을 풀기 위해 FDS는 수치적 기법으로 공간 및 시간에 대해 2차 정확도를 가지는 외재적 예측-수정자법(predict-corrector method)을 사용한다. 이 기법은 유동 변수를 외재적 2차 정확도 Runge-Kutta 기법을 사용하여 갱신한다.
저속의 경우 밀도변화를 무시할 수 있다. 따라서 운동량 방정식을 간략히 수정하여 나타내면 다음과 같다.
여기서 와 는 각각 이류항, 경압항 그리고 는 전압을 나타낸다. 속도에 대해 시간 전진 전에 압력항에 대해 Poisson 방정식을 반드시 풀어야 한다. 간략히 수정된 운동량 방정식에 발산을 취해 나타내면 압력에 대한 Poisson 방정식은 다음과 같다.
FDS는 CRAYFISHPAK 라이브러리[15]의 부분인 FFT 기반 직접 행렬 솔버를 사용하여 Poisson 방정식을 계산한다. 계산된 압력은 시뮬레이션 해석 결과에 영향을 끼치기 때문에 압력 해석에 높은 정밀성을 요구한다.
3. 유동장 모델링 및 해법FDS의 병렬처리
분산 메모리 시스템은 네트워크로 서로 연결된 여러 개의 노드로 구성된다. 이와 달리 공유 메모리 시스템은 대규모 병렬 작업을 실행할 수 있도록 많은 수의 코어가 포함된 워크스테이션과 같은 컴퓨터를 말한다. Fig. 1에 개략도를 간략히 나타내었다.
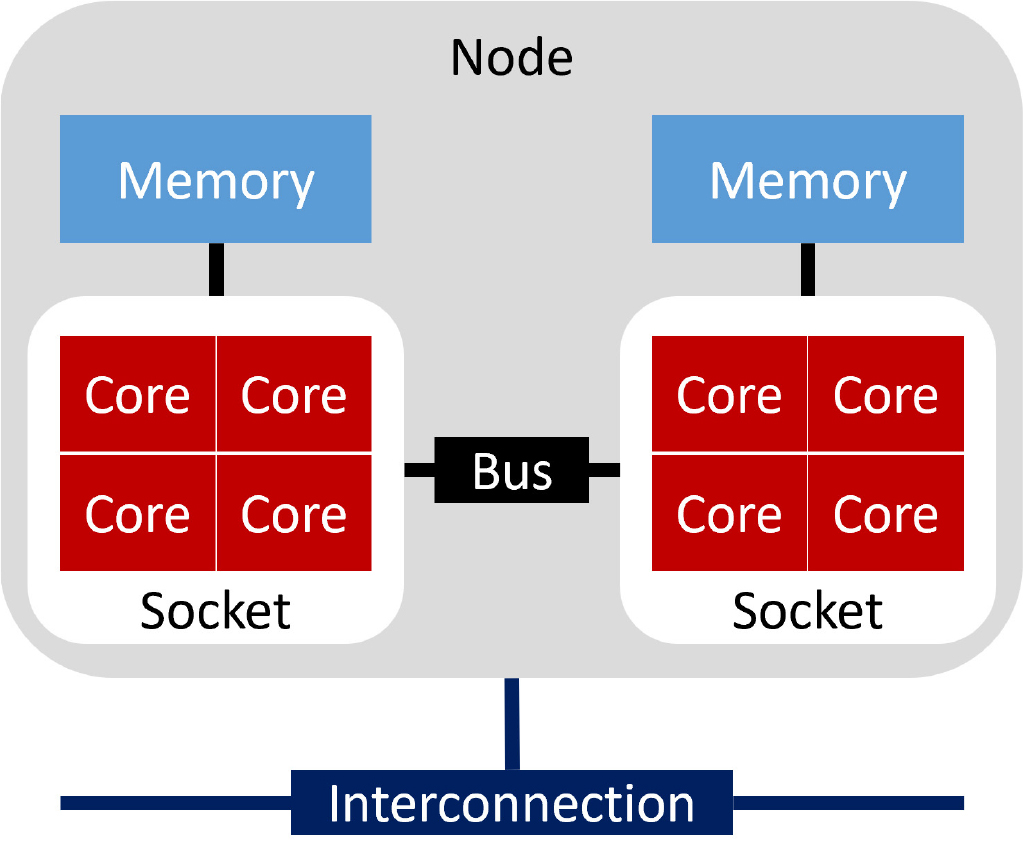
Fig. 1은 하나의 CPU가 4개의 코어로 구성된 2개의 소켓으로 이루어진 계산 노드이다. 이 경우 노드당 MPI 및 OpenMP를 사용할 수 있는 하드웨어 구조이다.
분산 메모리 시스템과 공유 메모리 시스템 환경에서 병렬 계산을 수행하기 위한 표준 방법이 MPI와 OpenMP이다. MPI는 동시에 실행 중인 여러 프로세스가 서로 메시지를 주고받음으로써 서로 통신 할 수 있도록 개발된 기술이고, 또한 공유 메모리 시스템에서도 적용할 수 있다. 이와 달리 OpenMP는 공유 메모리 시스템 환경에서만 사용할 수 있다. FDS 버전 5.4부터 병렬 계산이 지원되고 있고, OpenMP와 MPI 두 가지 병렬처리 방법을 제공한다. 이 두 가지 방법은 하드웨어 구성에 따라 FDS에 동시에 적용 할 수 있다.
FDS 사용자 안내서[1]의 3.1.2 절에서 OpenMP의 최대 속도 향상이 약 2배가 된다고 알렸고, MPI와 OpenMP를 함께 사용하는 경우 대부분의 해석 시간 단축은 MPI에 의해 이루어진다고 알렸다[1, 10].
3.1 MPI
MPI는 분산 및 병렬처리에서 정보교환에 관해 기술하는 표준이다. 메시지 패싱(message passing) 방식은 프로세서 간에 교환할 데이터를 메시지 전달함수를 사용해 주고받는 연산 모델로서 이런 함수들의 집합체인 메시지 패싱 라이브러리(message passing library)의 표준을 정의한 것이 MPI이며 이에 맞추어 여러 MPI 라이브러리가 개발되어 있다.
FDS 코드의 병렬화는 기본적으로 순차 코드를 기반으로 한다. 순차 코드에 병렬화가 필요한 서브루틴을 적절한 병렬화 기법을 통하여 병렬 코드를 구축하게 된다. Fig. 2는 순차 코드를 기반으로 한 일반적인 병렬화 알고리즘이며, FDS 병렬화 코드도 비슷한 알고리즘으로 구성되어 있으므로 여기서는 생략하기로 한다.
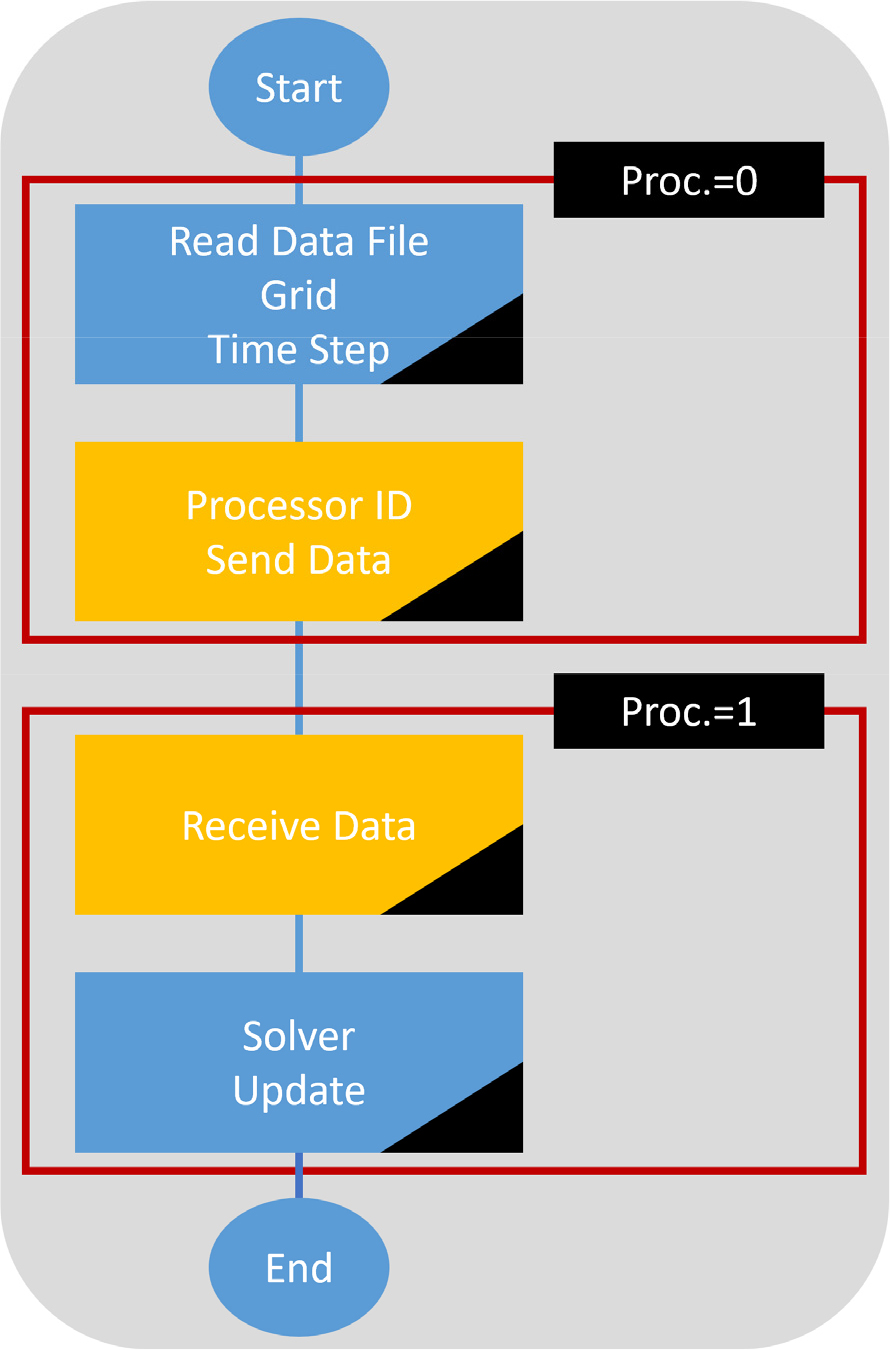
Fig. 2에서 볼 수 있듯이, 0번 노드 또는 프로세서가 연산을 담당하는 부분과 모든 노드 또는 모든 프로세서가 연산하는 부분으로 크게 나누어 생각해 볼 수 있다. 병렬화가 필요한 서브루틴의 경우 주로 MPI_Send와 MPI_Recv 명령을 기본으로 데이터 전송이 이루어진다. 병렬화가 이루어진 서브루틴은 각각의 프로세서가 계산하는 시간 이외에 다른 프로세서와의 통신 시간이 걸리기 때문에 네트워크의 성능 또한 병렬 성능을 좌우하는 요인으로 작용한다.
3.2 OpenMP
OpenMP는 다양한 컴퓨터 플랫폼에 C, C++, Fortran과 같은 프로그래밍 언어로 구성된 프로그램을 공유 메모리 다중 프로세스(shared memory multi processing)를 지원하는 응용프로그램 인터페이스(application programming interface)이다[14, 16]. OpenMP는 데스크탑에서 슈퍼컴퓨터에 이르기까지 다양한 병렬 응용프로그램 개발을 위한 간단하고 유연한 인터페이스를 사용자에게 제공하며, 휴대 및 확장이 용이하다. 그리고 OpenMP 및 MPI를 이용하여 응용프로그램을 Hybrid OpenMP/MPI 모델로도 구축할 수 있다[17]. OpenMP의 대표적인 fork-join 모델에 대한 개념도는 Fig. 3에 나타나 있다. OMP_NUM_THREADS 환경변수를 통해 사용할 스레드 수를 정의하고, Fig. 3과 같이 반복 루틴 이전에 환경변수에서 정의된 스레드 수 이하의 스레드를 OMP_SET_NUM_THREADS()을 통해 가변적으로 조절할 수 있어 사용자 편이성이 높다.
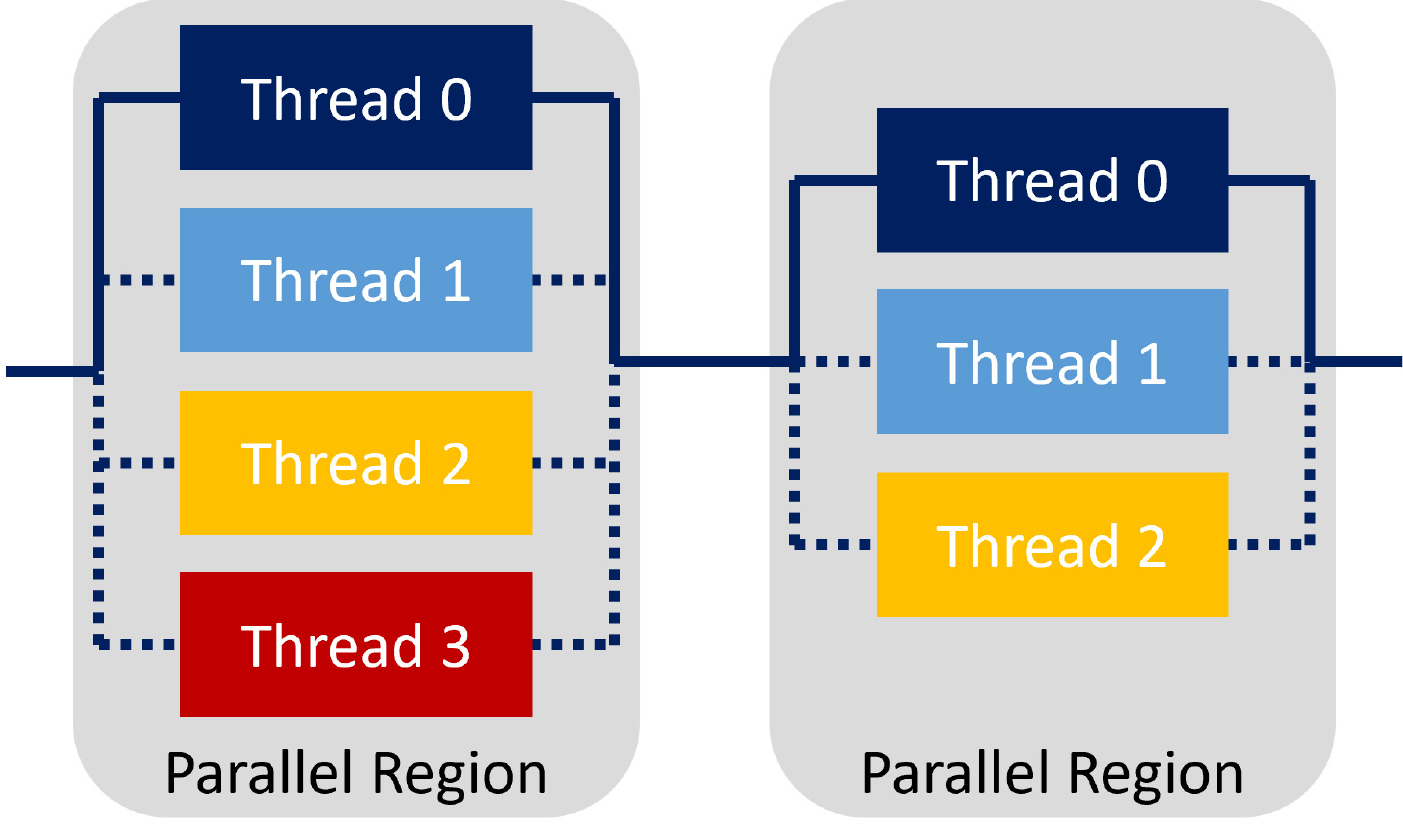
OpenMP의 장점으로는 MPI를 사용하지 않고 공유 메모리 다중 프로세서에서 직접 병렬화를 할 수 있고, 또한 MPI처럼 많은 시간을 들여 병렬화하는 것에 반해, OpenMP를 지원하는 컴파일러를 통해 순차 코드에 OpenMP 지시어를 사용해 자동으로 데이터를 분리할 수 있어 시간적 면에서 이점이 있다. 그러나 컴파일러가 OpenMP를 지원해야 하며, 플랫폼의 메모리 확장에 제한이 있어 대규모 계산에는 OpenMP보다 MPI가 유리하다.
4. 결 과
4.1 문제 설정
병렬 성능을 측정하기 위해 본 연구에서는 FDS 검증 케이스[3]의 11.8.4절에 있는 3차원 열확산 문제를 선정하였다. Fig. 4는 병렬 성능 비교를 위한 3차원 강철 I-빔의 형상과 결과 비교를 위한 프로브 위치를 보여준다. 상·하단 플랜지는 가로와 세로의 길이가 0.4 m이며 플랜지의 두께는 0.06 m이다. 웨브의 두께는 0.04 m이고 길이는 0.28 m이다. 전체 계산 도메인은 0.02 m의 주변 영역을 포함하여 0.44 × 0.44 × 0.44 m3 의 크기를 갖는다.
Fig. 4에 제시된 바와 같이 우측 하단의 고정된 값의 Heat wall 영역(800℃)외에는 단열 경계조건을 설정하였다. 해석 영역의 초기 조건은 20℃로 설정하고 3600초의 물리적 시간만큼 해석을 수행하였다. 물리적 해석 시간 간격은 해석 안정적인 계산은 위해 약 1.7초(△t≈1.7s)로 설정하였다.
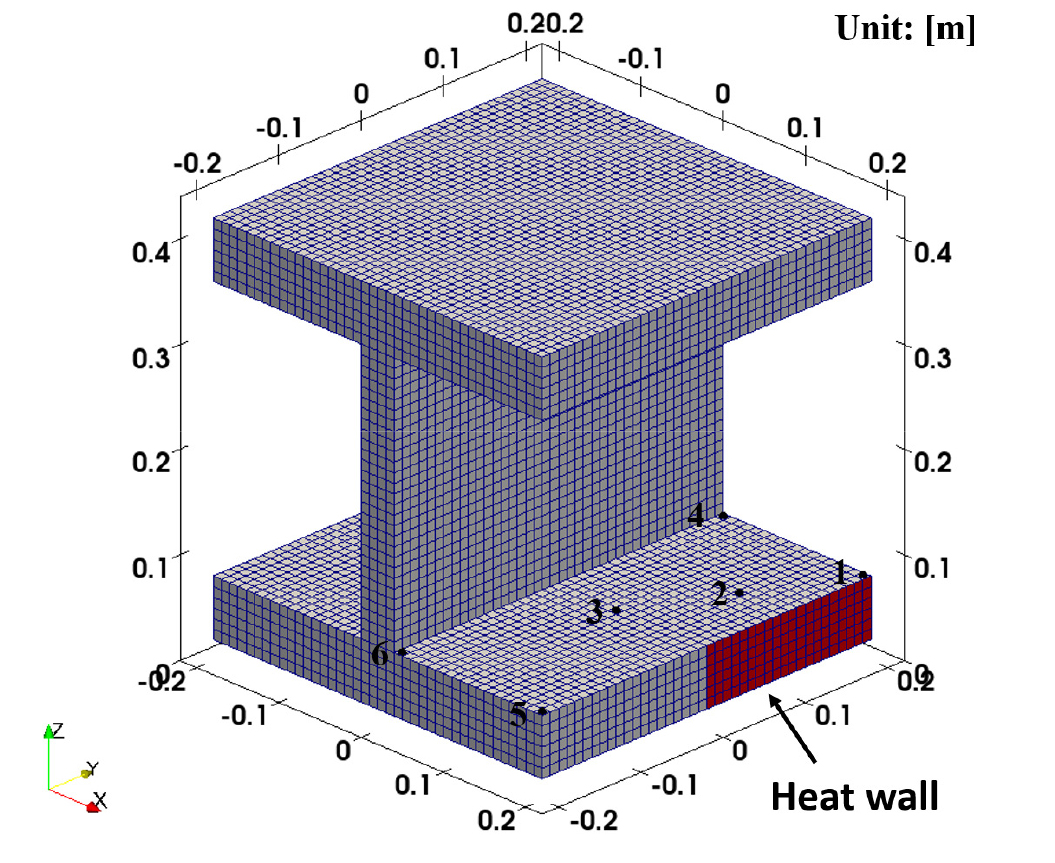
Fig. 5는 병렬 연산을 위해 프로세서 수에 따른 영역 분할을 나타낸다. FDS는 Z-Y-X축 순으로 각 축의 전체 영역을 2 분할하여 전체 영역을 나누는 방식을 사용한다. 따라서 각 영역에 1개의 프로세서를 할당하여 최대 16개의 프로세서를 사용하였다. 본 연구에서 사용된 프로세서는 AMD사의 라이젠 스레드리퍼 3960X 프로세서를 사용하였고 CPU 코어 수는 24 개, 스레드 수 48 개이며 운영체제는 Ubuntu 16.04.6이다.
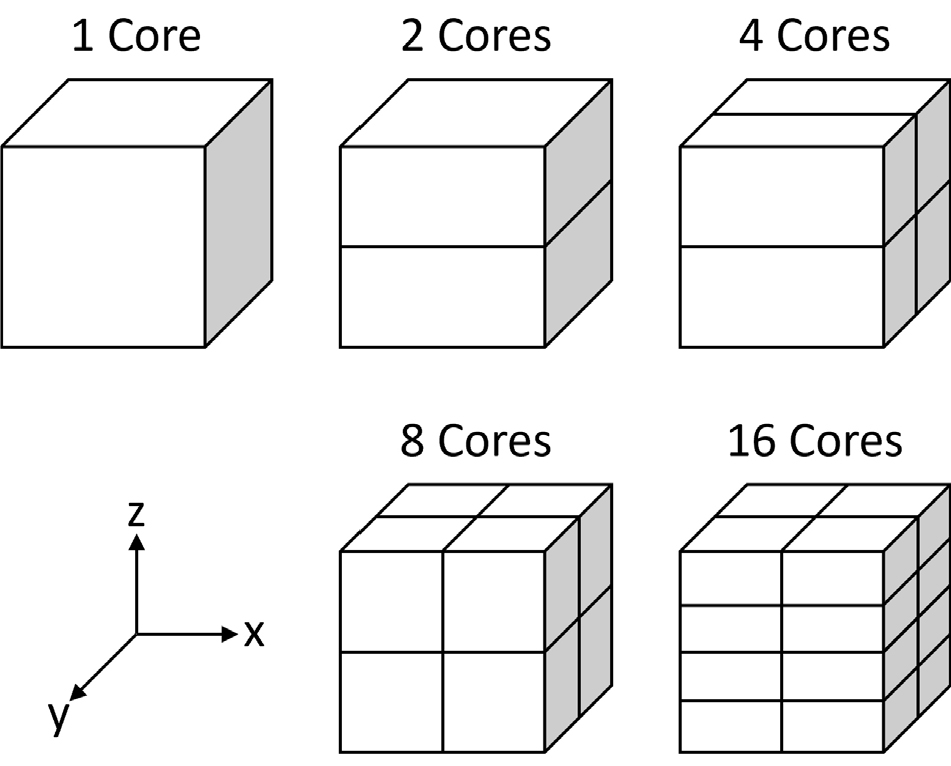
Table 2는 격자 조밀도에 따라 coarse, medium, fine으로 제작된 3가지의 격자 정보를 보여준다. coarse는 한 셀의 크기가 0.01 m, medium은 0.005 m, fine은 0.002 m인 정렬 격자이다. 따라서 전체 격자의 셀 수는 각각 85,184 개, 681,472 개, 10,648,000 개이며, 열확산이 계산되는 I-빔을 구성하는 격자는 23,680 개, 370,000 개, 2,960,000 개의 셀이다.
MPI는 Intel MPI와 Open MPI를 사용하였으며 Intel MPI는 FDS-SMV 6.7.4 번들에 탑재된 Intel 컴파일러 스크립터를 사용하여 Intel(R) MPI 라이브러리 2019 Update 4 버전을 사용하였다. Open MPI는 GNU Fortran 9.3.0 버전을 사용하여 FDS를 컴파일하였고 Open MPI 라이브러리 4.0.3 버전을 사용하였다.
Table 2.
Mesh configurations
| Mesh | Coarse | Medium | Fine |
| Cell size [m] | 0.01 | 0.005 | 0.002 |
| Number of cells (in I-beam) | 85,184 (23,680) | 681,472 (370,000) | 10,648,000 (2,960,000) |
| Boundary mesh | 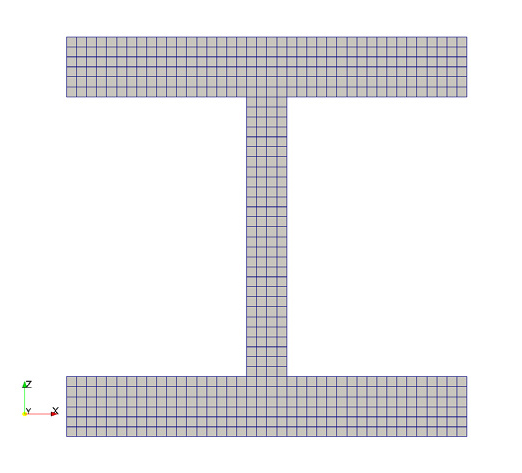 | 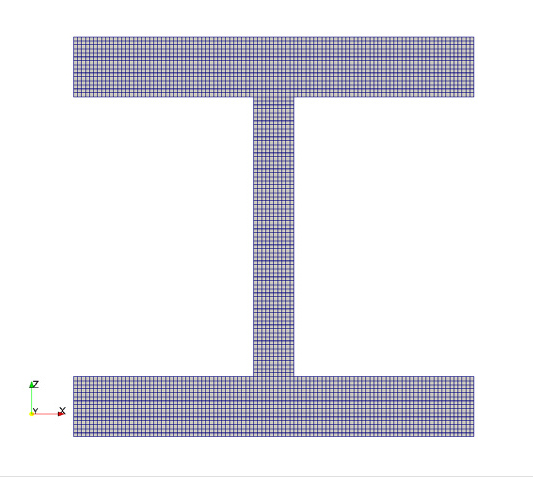 |  |
4.2 결과 비교
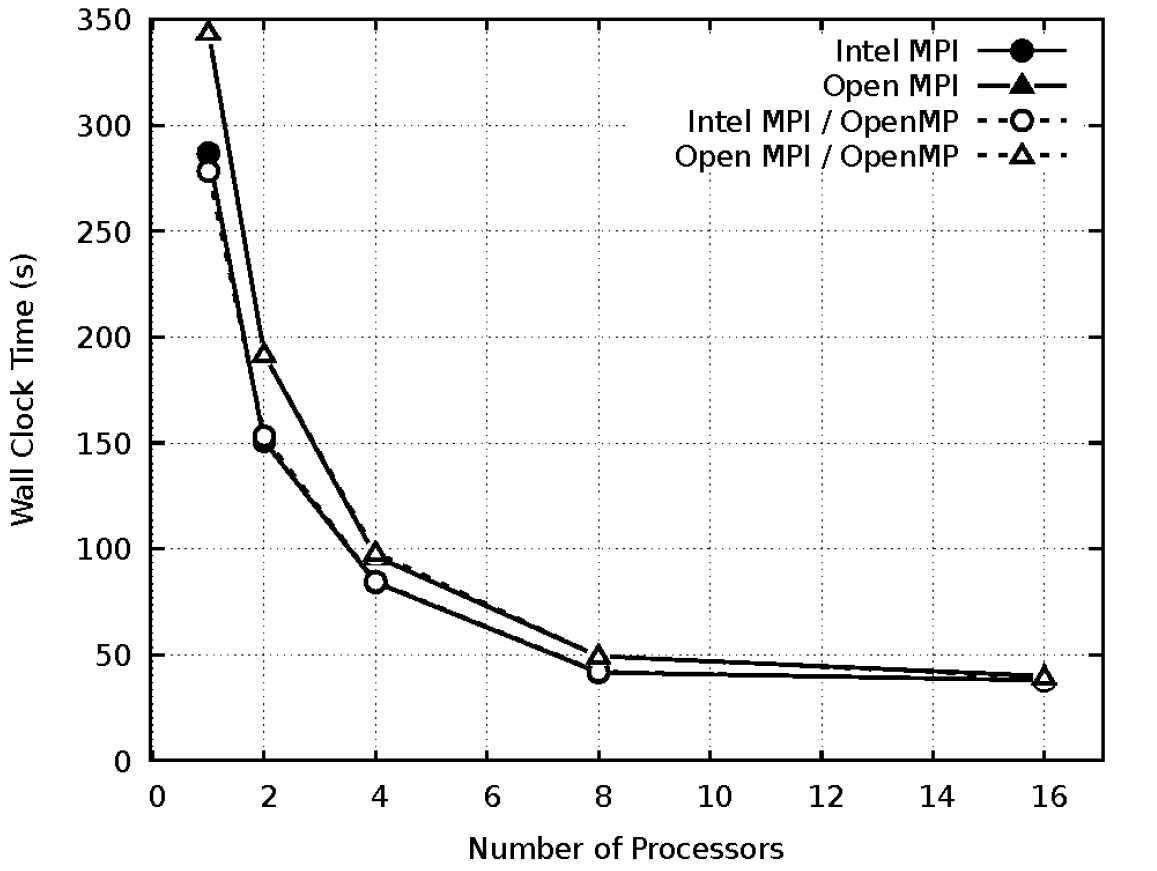
Fig. 6는 coarse 격자에서 프로세서 수에 따른 MPI와 OpenMP를 사용한 계산 시간을 비교하였다. Coarse 격자에서 Intel MPI가 Open MPI에 비해 평균 38%의 성능 향상이 나타났다. OpenMP 테스트는 스레드 2개를 사용하여 테스트를 진행 하였으며, OpenMP는 Intel MPI와 Open MPI에서 성능에 영향을 미치지 못하였다.
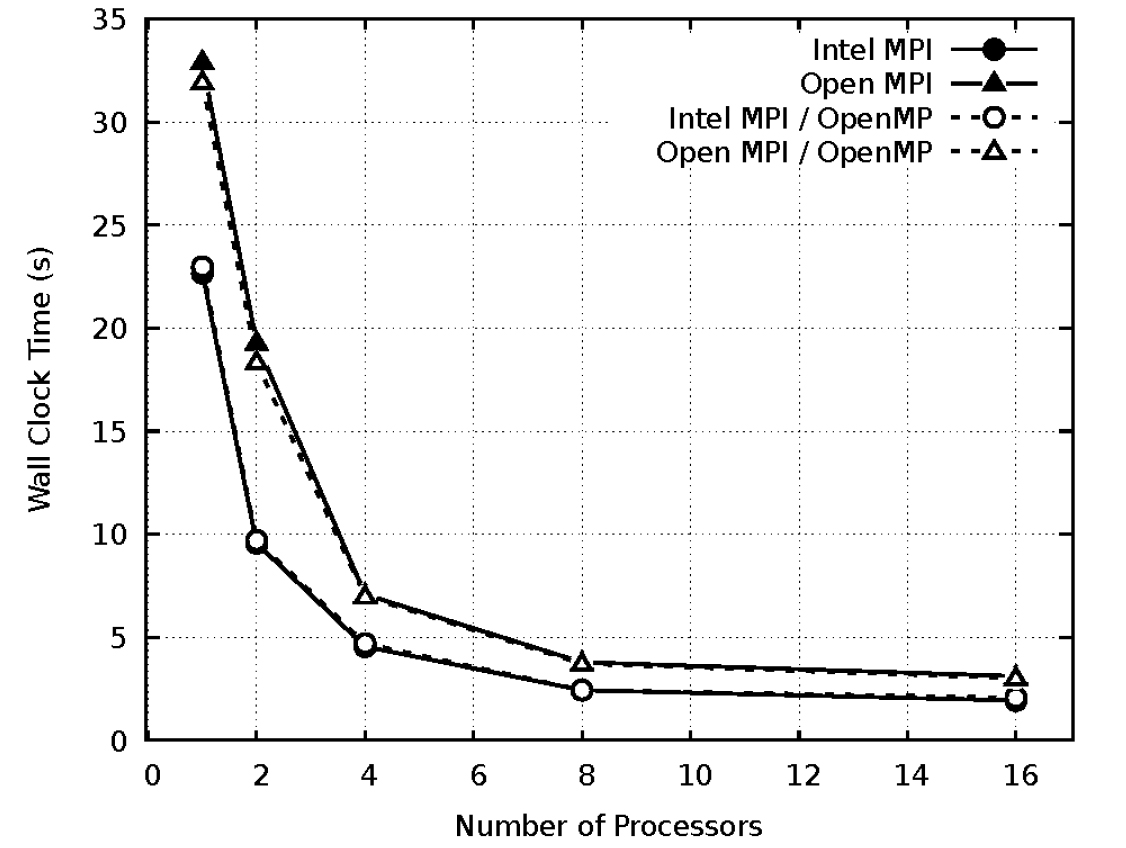
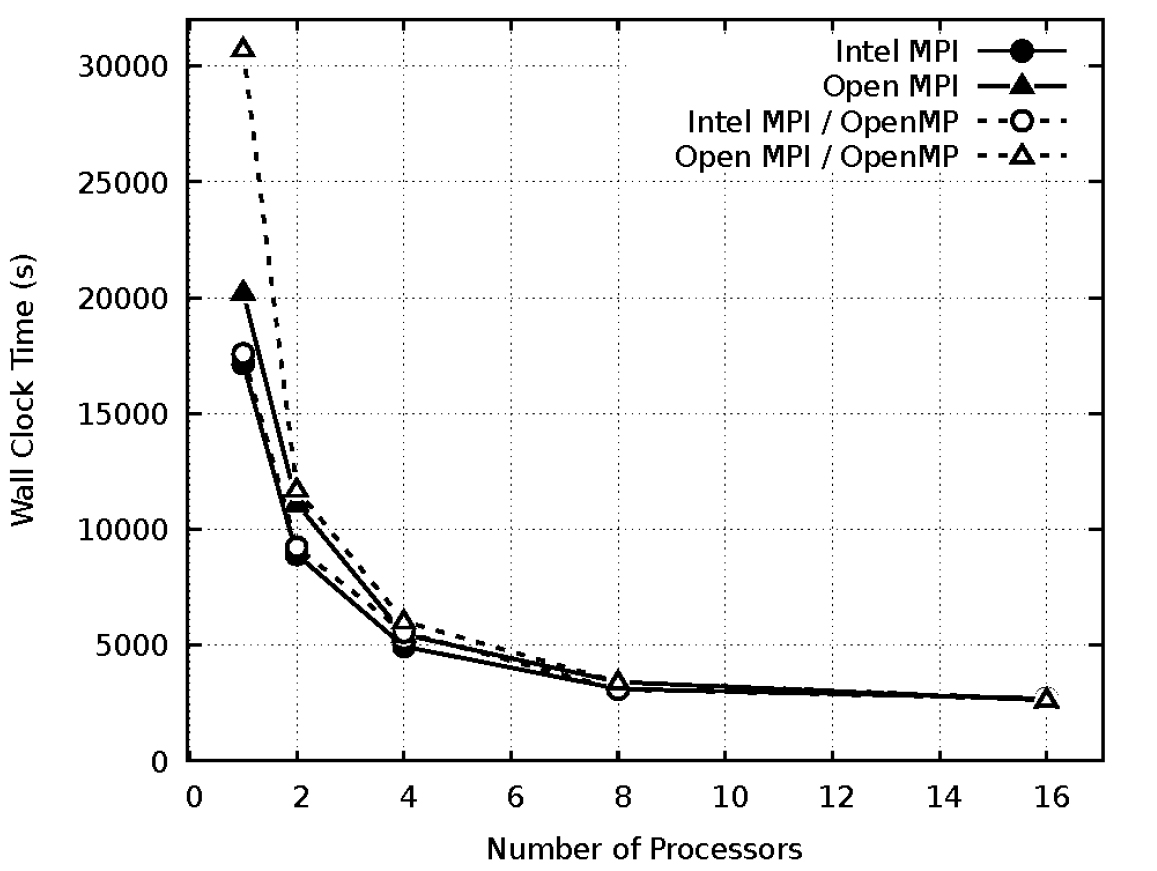
Fig. 7는 medium 격자에서 프로세서 수에 따른 MPI와 OpenMP를 사용한 계산 시간을 비교하였다. Medium 격자에서 Intel MPI가 Open MPI에 비해 평균 14%의 성능 향상을 확인하였다. Fig. 8은 fine 격자에서 프로세서 수에 따른 MPI와 OpenMP를 사용한 계산 시간을 비교하였다. Fine 격자에서 Intel MPI가 Open MPI에 비해 평균 10%의 성능 향상을 확인하였다. 조밀한 격자에서 OpenMP를 사용 시 단일 프로세서의 계산 시간이 급격히 증가하는 현상이 나타났다. 프로세서의 수가 증가할수록 MPI간의 계산 시간의 차이는 감소하였다. 본 연구에서는 Intel MPI이 Open MPI에 비해 우수한 성능을 나타내는 것을 확인하였다. 격자수가 증가하면 병렬 성능이 감소하였다. 본 연구에서 사용된 I-빔 열확산 케이스는 모든 격자 및 MPI에서 OpenMP의 병렬 효과가 나타나지 않았다.
4.3 성능 비교
병렬 계산은 주로 속도 향상과 병렬 효율 그리고 확장성에 대해 초점이 맞춰져 있으며, 속도 향상은 병렬 계산으로 전체 계산 프로세스의 실행 시간과 단일 노드 실행 시간의 비율을 표현하고, 병렬 효율성은 각 프로세서의 평균 활용도를 의미하며 다음과 같이 나타낸다.
speed-up:
parallel efficiency:
여기서 n은 프로세서의 수를 의미하며, 은 단일 프로세서에서 소요된 시간, 은 n개의 프로세서에서 병렬 계산 소요된 시간을 나타내고, 은 속도 향상, 은 병렬 효율을 나타낸다.
Fig. 9, 10 및 11은 각 격자 coarse, medium, fine에서 프로세서 수에 따른 MPI와 OpenMP를 사용하였을 때 속도 향상(speed-up)을 비교하였으며 이를 바탕으로 병렬 효율을 Table 3에 정리하였다.
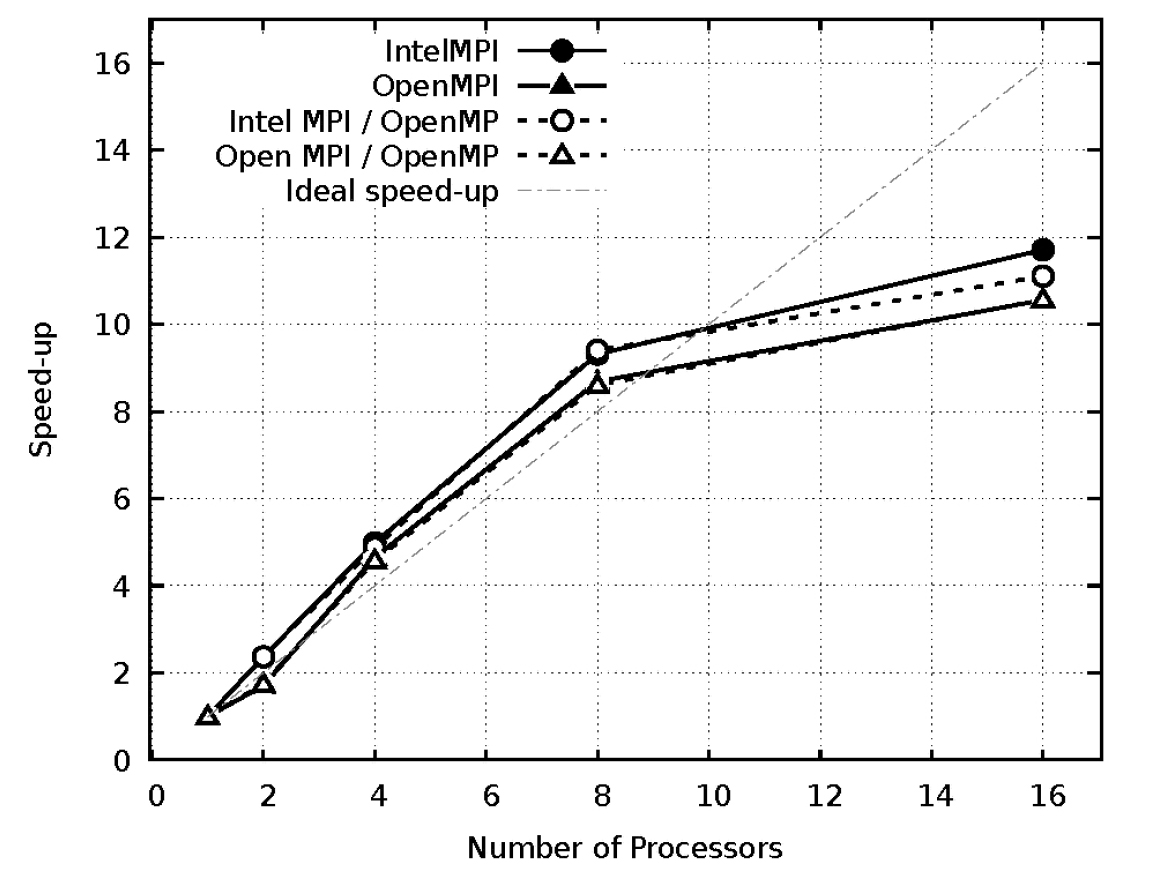
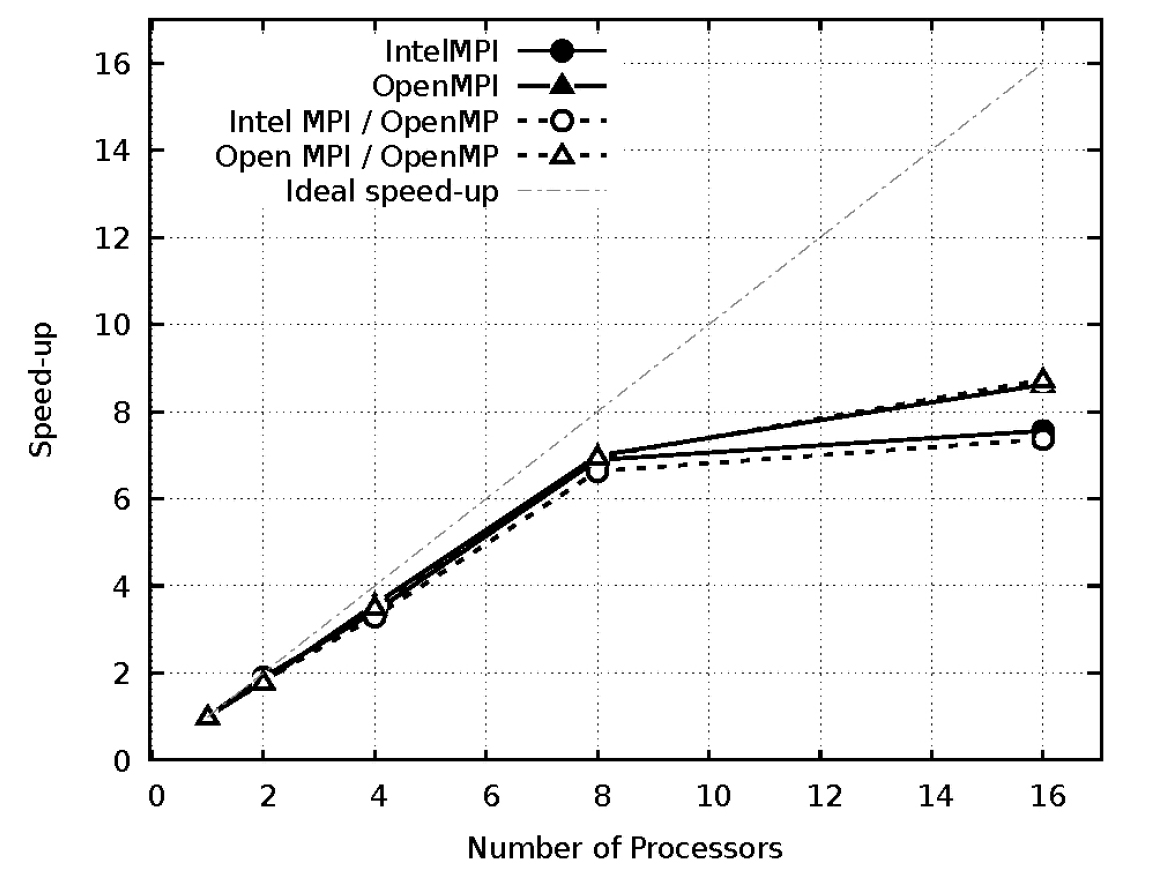
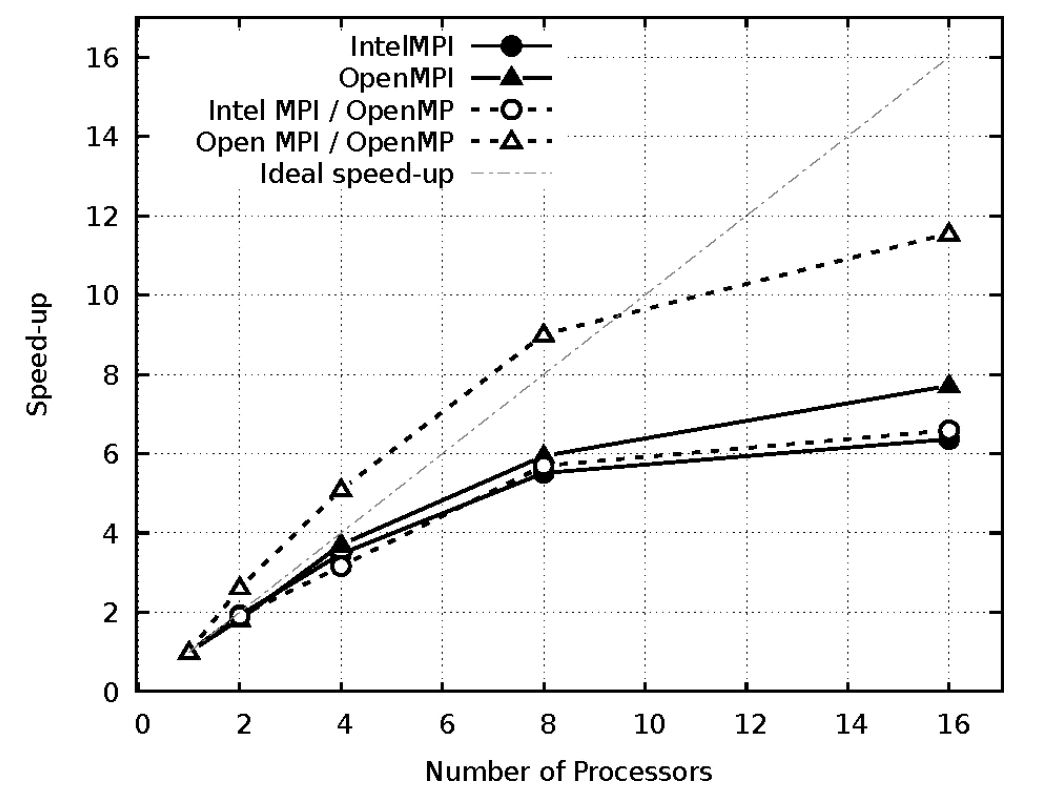
Table 3.
Results of parallel efficiency
| MPI | Intel MPI | Open MPI | △MPI* | |||
| OpenMP | w/o | with | w/o | with | w/o | |
| Coarse | ||||||
| Processors | 2 | 118.5 | 118.4 | 85.4 | 87.0 | 33.1 |
| 4 | 124.6 | 122.1 | 116.3 | 114.4 | 8.3 | |
| 8 | 116.5 | 117.5 | 108.6 | 107.5 | 7.9 | |
| 16 | 73.2 | 69.4 | 66.0 | 66.0 | 7.2 | |
| Medium | ||||||
| Processors | 2 | 95.1 | 89.8 | 90.88 | 89.6 | 4.22 |
| 4 | 85.2 | 89.3 | 82.35 | 87.6 | 2.85 | |
| 8 | 86.2 | 87.4 | 82.9 | 87.0 | 3.3 | |
| 16 | 47.2 | 53.9 | 46.04 | 54.57 | 1.16 | |
| Fine | ||||||
| Processors | 2 | 96.2 | 95.3 | 91.1 | 133.1 | 5.1 |
| 4 | 86.8 | 79.1 | 92.7 | 129.4 | -5.9 | |
| 8 | 68.9 | 71.2 | 74.3 | 114.3 | -5.4 | |
| 16 | 39.8 | 41.2 | 48.2 | 73.3 | -8.4 | |
Coarse 격자에서는 8개의 프로세서 사용까지는 100% 이상의 병렬 효율을 나타내었지만 16개의 프로세서 사용에서 효율이 감소하였다. 속도 향상 면에서도 Intel MPI가 Open MPI보다 높은 효율을 나타내었다.
Medium 격자에서는 8개의 프로세서 사용까지는 90% 수준의 병렬 효율을 나타내었지만 16개의 프로세서 사용에서 효율이 급격히 감소하였다. Fine 격자에서는 Open MPI에 OpenMP 사용 시, Fig. 8에서 보았듯이 단일 프로세서에서 성능 저하로 인해 병렬 효율이 높게 나타남을 확인할 수 있다. 16개의 프로세서를 사용할 경우, medium 격자와 fine 격자에서는 Open MPI가 Intel MPI보다 프로세서 1개 수준의 병렬 성능 향상을 보였다. 전체적으로 병렬 효율은 격자가 조밀해질수록 감소하는 것을 확인할 수 있다. 격자가 엉성한 경우 Intel MPI의 사용이 단일 프로세서 성능뿐 아니라 병렬 효율에서도 우수하였지만, 격자가 조밀하고 여러 개의 프로세서를 사용할 경우 Open MPI가 Intel MPI보다 높은 병렬 성능을 나타내어 결과적으로 비슷한 계산 시간을 나타내었다.
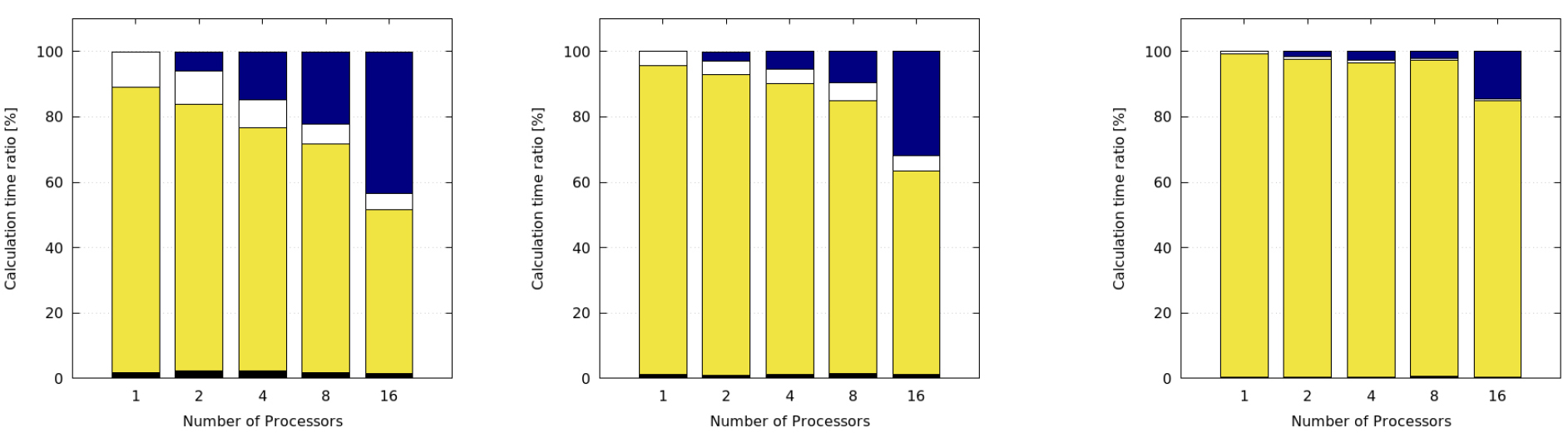
Fig. 12은 계산에 소요된 소스 코드의 시간 비율을 확인하였다. OpenMP를 사용하지 않은 Intel MPI 케이스를 나타내었으며, 왼쪽부터 순서대로 coarse, medium, fine 격자의 결과이다. 가장 하단에 MAIN은 메인 소스코드에 사용된 계산 시간 비율이며, 대부분의 계산 시간을 차지하는 WALL은 열전달에 관한 소스코드이고, DUMP는 출력에 관련된 소스코드에 사용된 시간이다. 간단한 열전달 문제로 병렬 연산을 하지 않을 경우 이 3가지의 소스코드만 사용된 것을 알 수 있고, 병렬 연산을 수행하면 상단에 프로세서 간의 MPI 통신에 사용되는 시간에 해당하는 COMM이 나타난다. 프로세서가 증가할수록 MPI 통신에 사용되는 시간 비율이 증가하는 것을 알 수 있으며, 격자가 조밀해질수록 전체 계산 시간 대비 열전달 해석 시간의 비율이 증가하는 것을 알 수 있다. Fig. 9, 10, 11에서 프로세서 수가 8개에서 16개로 증가할 때 성능향상이 급격히 감소하였는데, 이때 전체 계산 시간 대비 MPI 통신에 사용하는 시간비율이 급격히 증가한 것을 확인할 수 있다. 따라서, MPI 통신에 사용되는 시간비율의 급격한 증가는 병렬 성능에 큰 영향을 미치는 것을 확인하였다.
4.4 해석 결과 검증
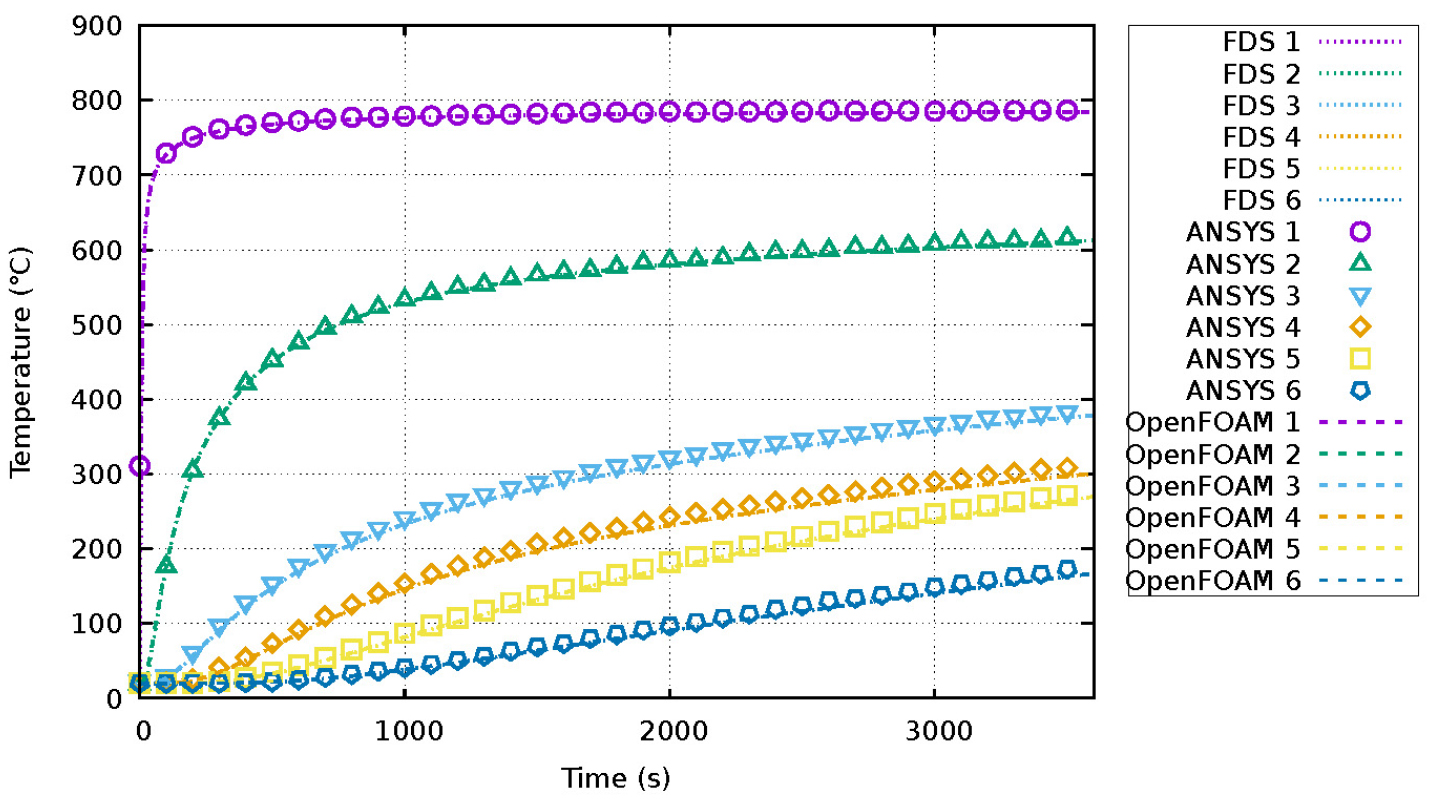
FDS의 해석 결과가 상용 및 공개 솔버의 결과와 유사한지를 검증을 위해 I-빔 열확산 케이스의 해석 결과를 비교하였다. 상용 솔버는 FDS 검증 가이드에 언급된 ANSYS의 유한요소모델(finite element model) 결과를 인용하였으며[1], 공개 솔버는 OpenFOAM[18]의 laplacianFoam을 사용하여 해석을 수행하였다.
Fig. 13은 Fig. 4에 나타낸 온도 측정을 위한 6개 지점에서 시간에 따라 FDS와 상용 및 공개 솔버의 해석 결과를 나타내었다. 시간에 따른 온도 분포도에서 FDS의 해석 결과가 상용 및 공개 솔버의 해석결과와도 잘 일치함을 확인할 수 있다.
5. 결 론
화재 모사 프로그램인 FDS의 병렬화 성능을 MPI와 OpenMP에 대해 조사하였다. 본 연구에서 MPI는 Intel MPI와 Open MPI를 사용하였으며, I-빔 열확산 문제를 대상으로 병렬 성능을 확인하였다. Coarse 격자에서 Intel MPI가 Open MPI 대비 평균 38 % 성능 향상을 보였으며, medium 격자에서 평균 14%, fine 격자에서 평균 10% 성능 향상을 나타내었다. 격자가 조밀해지고 프로세스의 수가 많아지면 Open MPI의 병렬 효율이 증가하여 계산 성능 차이가 감소하였다. OpenMP의 효과는 크게 나타나지 않았다. 계산에 사용된 시간 비율 분석을 통해 MPI 통신에 사용되는 시간 비율의 급격한 증가는 병렬성능에 큰 영향을 미치는 것을 확인하였다.
본 연구는 FDS 병렬화 연구의 중요한 기초자료로써 의미가 있으며 후속 연구로 FDS의 연산시간 최소화를 위해 CPU, GPU, MIC의 이종 하드웨어 아키텍처를 사용하는 병렬 가속화 연구를 수행할 예정이다.
