

1. Introduction
2. Background theory
2.1 Long-short term memory(LSTM)
2.2 어텐션 메커니즘(attention mechanism)
2.3 멀티 헤드 어텐션(Multi-head attention)
3. 데이터 취득 및 전처리
3.1 문제 정의 및 데이터 생성
3.2 유동 해석
4. 모델, 학습 방법 및 평가 방법
4.1 모델링 및 학습방법 선정
4.2 평가 지표
5. Result
5.1 예측 성능 평가
5.2 설명성 평가
6. Conclusion
1. Introduction
인공지능(AI) 기술이 대중화되면서 공기역학 분야에서도 시간이 많이 걸리는 시뮬레이션과 값비싼 실험에 의존하지 않고 물체의 공기역학적 특성을 빠르게 예측하는 새로운 방법으로 AI를 활용하려는 관심이 높아지고 있다. 생성형 인공지능 기술(Generative AI)을 활용하여 실시간으로 유체 시뮬레이션을 생성하고[1], 낮은 레이놀즈 수의 익형 설계를 효율적으로 수행하기 위해 딥러닝 기법을 사용하여 원하는 설계 공간을 합리적으로 정의하는 익형 모달 매개변수화 방법을 제시하는 연구가 수행됐다[2]. 또한, 물리 정보 신경망(physics-informed neural network)을 사용하여 Navier-Stokes(NS) 방정식을 차분화하여 해를 구하던 기존의 전산유체역학(computational fluid dynamics) 해석자를 신경망(neural network)으로 대체하여 계산 속도를 향상시킨 연구들이 이루어졌다[3,4].
그러나 기존의 머신러닝과 달리 딥러닝 기반 방법론은 내부 메커니즘을 해석하기 어렵다는 설명가능성의 한계가 있다. 이를 극복하기 위해, 설명 가능한 인공지능(explainable AI, XAI) 기법을 활용해 AI 모델을 해석하려는 시도가 늘어나고 있다. XAI는 AI모델에 들어가는 입력과 출력의 상관관계를 다양한 기술을 통해 밝히고자 시도하며 그 결과는 주로 출력(예측결과)과 관련이 깊은 입력 데이터의 특징(feature)에 대한 가중치로서 표현된다. 대표적인 기법으로는 LIME(Local Interpretable Model-agnostic Explanation)[5], SHAP(Shapley Additive exPlanations)[6], 그리고 본 논문에서 다루고자 하는 어텐션 메커니즘(attention mechanism)이 있다. XAI를 적용한 연구로는 Schlegel 등은 자동차 엔진 소음을 측정한 시계열 데이터에 대해 다양한 XAI 방법을 적용하여, 딥러닝 기법이 시간적 측면을 고려하는 것을 입증하는 연구를 수행한 바가 있다[7]. 또한, Yoo 등은 3차원 CAD모델의 제조원가 예측 프로세스에 XAI를 적용하여 딥러닝 기법이 CNC 가공 특징을 감지할 수 있을 뿐만 아니라 동일한 특징에 대한 가공 난이도를 차별화할 수 있음을 증명하는 연구를 수행하였다[8].
공학분야에서 XAI연구가 증가하는 추세이지만 공기역학 분야에서는 증가하는 인공지능 연구 대비 XAI적용 연구는 부족한 실정이다. 따라서 본 연구는 공기역학 분야에서 딥러닝 모델에 XAI 기법을 적용하기 위한 XAI모델의 신뢰성에 대한 연구를 비교적 단순한 공기역학 문제에 적용, 수행하고자 하였다. 이를 위해 XAI기법 중 어텐션 메커니즘을 long-short term memory(LSTM) 기반 모델에 적용하여 익형의 충격파를 예측했고, 어텐션 메커니즘에서 얻어지는 입력의 상대적 중요성을 통해 모델의 설명가능성을 확보했다. 하지만 어텐션은 안정성 측면에서 XAI로서의 한계가 있기 때문에 이러한 한계점을 개선하기 위해 다수의 어텐션을 병렬로 사용하는 멀티 헤드 어텐션(multi-head attention)을 적용하였고, 해당 기법의 개선 정도를 확인하기 위해 어텐션의 설명성을 정량적으로 평가할 수 있는 평가 지표를 제시하였다.
2. Background theory
2.1 Long-short term memory(LSTM)
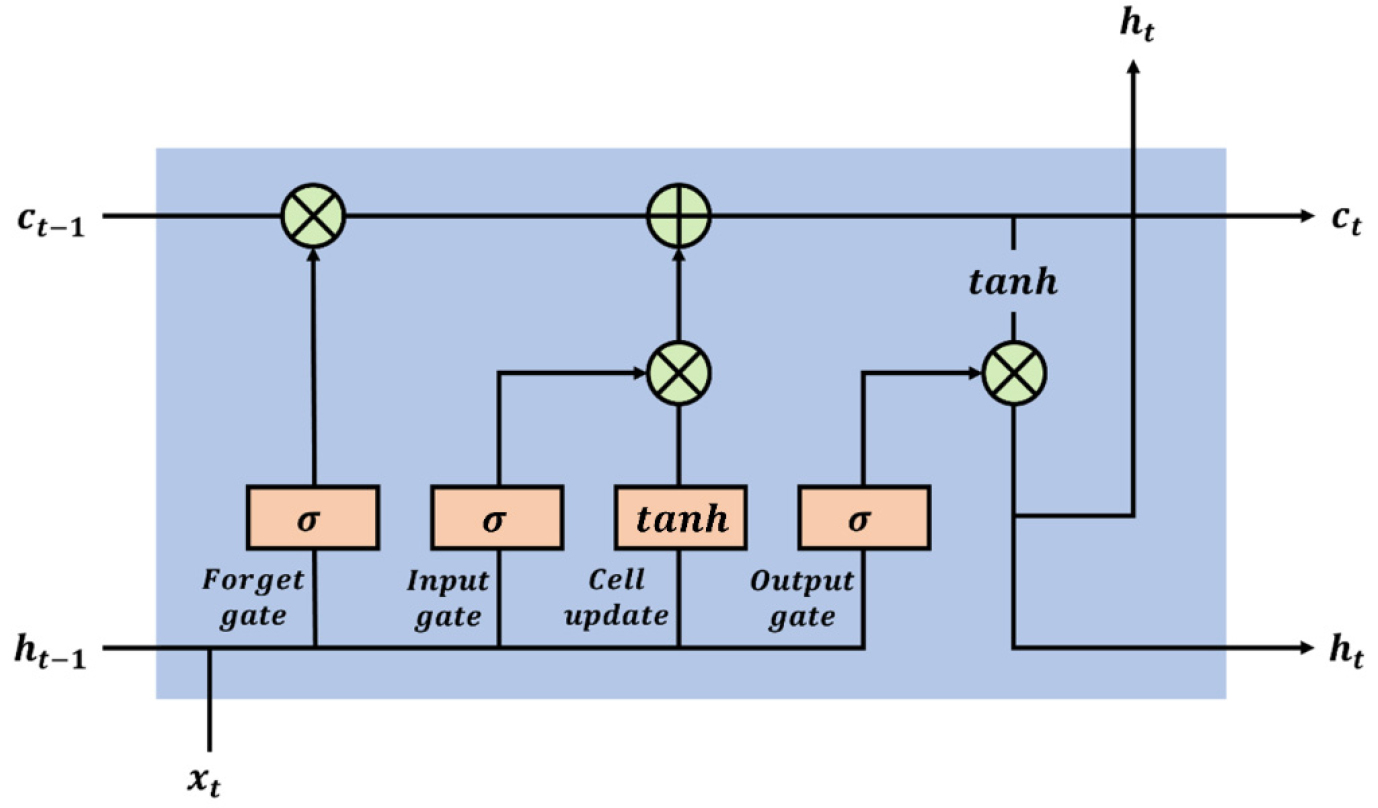
본 연구에서는 익형의 형상에서부터 충격파의 형태를 예측하는 모델을 학습한다. 이때 익형의 형상을 순차적인 데이터 포인트의 집합으로 보고 이에 적합한 딥러닝 아키텍처로 LSTM을 선정하였다. LSTM은 순환 구조로 학습하는 신경망인 recurrent neural network(RNN)에서 발생하는 장기적인 종속성을 학습할 수 없게 만드는 기울기 소실 문제를 해결하기 위해 Hochreiter 및 Schmidhuber에 의해 개발되었다[9]. LSTM은 장기간에 걸쳐 반복되는 관계(장기 종속성)는 학습하기 위해 반복적으로 전파되는 셀 상태에서 정보를 추가 및 삭제하여 프로세스를 제어하는 게이팅 메커니즘을 도입했다. Fig. 1과 같이 LSTM은 입력 x(t)와 이전 출력 h(t-1)으로 출력을 구성하는 기존 RNN과 달리 셀 상태 c(t)를 기반으로 구성된다. 각 게이트에는 시그모이드(σ) 함수가 사용되어 출력은 0과 1 사이의 값을 가지며, 이는 해당 게이트가 정보를 얼마나 통과시킬지를 결정한다. 새로운 정보를 얼마나 셀 상태에 추가할지를 결정하는 입력(input) 게이트와 이전 셀 상태에서 어떤 정보를 버릴지를 결정하는 망각(forget) 게이트를 통해 셀 상태를 반복적으로 조정하여 메모리 상태를 제어한다. 최종적으로 갱신된 셀 상태를 기반으로 출력(output) 게이트는 현재의 출력 h(t)를 결정한다.
2.2 어텐션 메커니즘(attention mechanism)
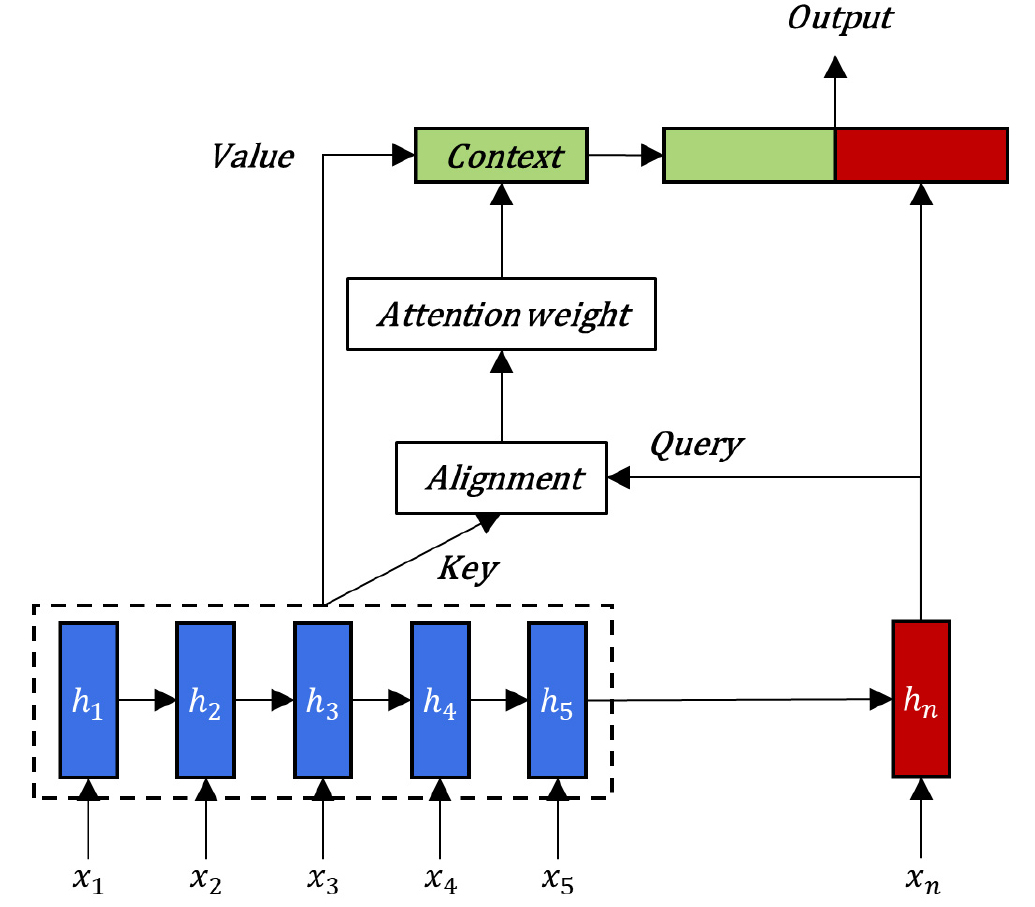
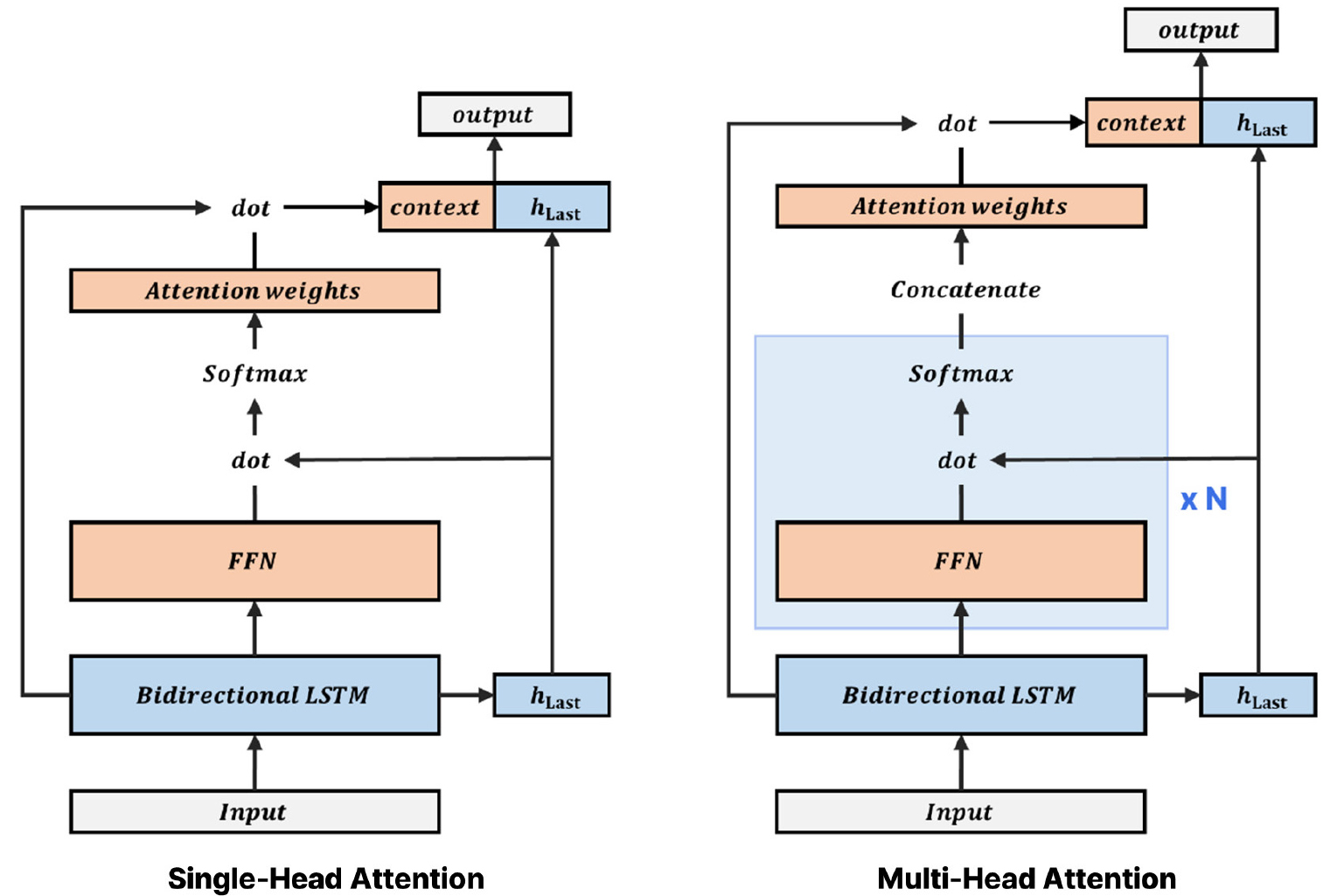
어텐션 메커니즘은 서로 연관된 두 개의 데이터 시퀀스 간의 관계를 모델링하는 시퀀스-투-시퀀스(sequence- to-sequence) 네트워크[10]의 성능을 개선하기 위해 Bahdanau에 의해 자연어 처리 분야에 처음 적용되었다[11]. 시퀀스-투-시퀀스 네트워크의 인코더는 입력 데이터를 고정 길이 벡터로 압축하는 과정에서 정보가 손실될 수 있어, 디코더가 긴 문장의 의미를 정확하게 표현하기 어려울 수 있다. 어텐션 메커니즘은 디코더가 인코딩된 전체 입력 시퀀스를 참조하여 입력에 대한 상대적 가중치를 유도함으로써 이러한 문제를 완화한다. 어텐션 메커니즘은 쿼리(query, 이하 q)와 키(key, 이하 k)-값(value, 이하 v) 쌍 집합을 출력에 매핑하는 것으로 설명할 수 있다. 일반적인 어텐션 메커니즘은 Fig. 2와 같이 설명할 수 있으며 요약하면 LSTM의 출력 벡터 집합을 입력으로 받아 어텐션 스코어와 어텐션 가중치를 구하고 그다음 컨텍스트 벡터로 변환하여 입력데이터 마지막 포인트의 은닉층 값과 합해 예측을 수행하게 된다. 각 단계에 대한 자세한 설명은 다음과 같다.
2.2.1 어텐션 스코어(Attention score)
어텐션 스코어는 쿼리(q)와 키(k)의 유사도를 측정한 값이다. 식 (1)과 같이 alignment 함수를 통해 쿼리(q)와 키(k) 간의 상관관계를 계산하여 키의 중요성을 반영하는 어텐션 스코어를 얻는다. Alignment 함수는 키(k)와 쿼리(q)가 일치하거나 결합되는 방식을 정의한다. Table 1은 몇 가지의 alignment 함수를 나열한 것이다. 일반적으로 계산 비용이 적은 내적이 주로 사용된다. 본 연구에서는 복잡한 패턴을 학습할 수 있도록 가중치를 도입하고, 이에 따라 변경되는 벡터 스페이스의 범위를 조정하기 위해 hypertangent를 활용한 alignment 함수를 사용했다.
Table 1.
Alignment function
| Definition | Function | Reference |
| Similarity | Graves et al. 2014[12] | |
| Dot product | Luong et al. 2015[13] | |
| General | Luong et al. 2015[13] | |
| Scaled dot product | Vaswani et al. 2017[14] | |
| This study |
2.2.2 어텐션 가중치 분포(Attention weight distribution)
어텐션 가중치 분포는 식 (2)와 같이 어텐션 스코어를 softmax 함수를 사용하여 확률 분포로 정규화한 값이다. 입력에 대한 상대적인 중요성으로 표현할 수 있다.
2.2.3 컨텍스트 벡터(Context vector)
컨텍스트 벡터는 식 (3)과 같이 어텐션 가중치 분포와 값(v)의 가중합을 통해 계산한 입력의 중요한 패턴을 요약한 정보 벡터다. 값(v)은 대부분의 아키텍처에서 키와 동일한 정보를 사용한다. 즉, 키(k)와 값(v)은 어텐션 메커니즘에서 동일한 정보 값을 다르게 표현한 것이다.
2.3 멀티 헤드 어텐션(Multi-head attention)
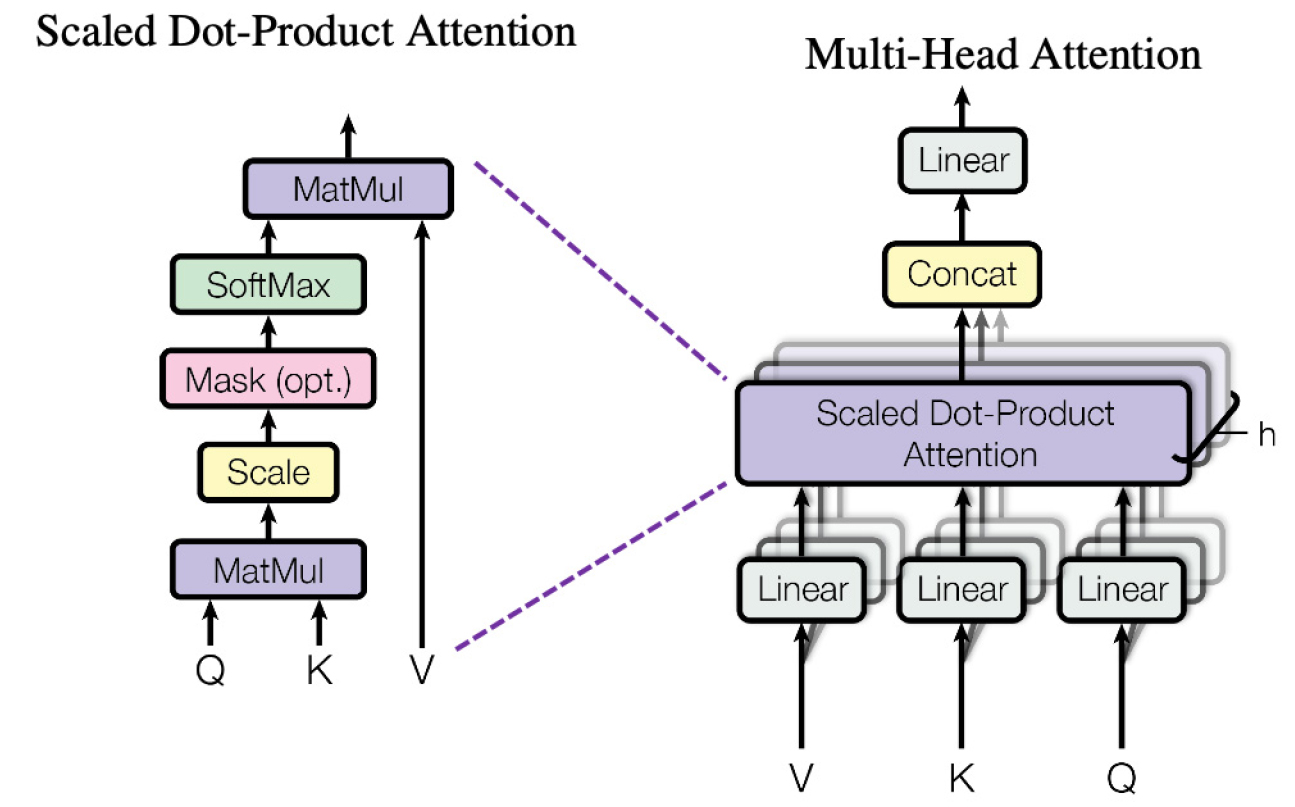
멀티 헤드 어텐션은 단일 어텐션을 수행하는 싱글 헤드 어텐션의 성능을 개선하기 위해 Vaswani에 의해 개발되었다[14]. 멀티 헤드 어텐션은 어텐션을 병렬로 배치함으로써 다양한 공간에 동시에 주의를 기울일 수 있다. 멀티 헤드 어텐션의 계산 과정은 식 (4)와 Fig. 3과 같이 순방향 신경망을 통해 변형된 쿼리(q), 키(k) 및 값(v)에 대해 어텐션을 병렬로 수행하고, 이후 어텐션 헤드들은 연결한 후 순방향 신경망에 통과시켜 최종값을 구한다. 멀티 헤드 어텐션을 사용하면 모델이 서로 다르게 표현되는 모든 하위 공간에 주의를 기울일 수 있다. 즉, 입력에 대해 독립적으로 계산된 어텐션들을 합치면서 모델의 표현력과 성능을 향상시킬 수 있다.
3. 데이터 취득 및 전처리
3.1 문제 정의 및 데이터 생성
본 논문에서는 익형의 형상에 따라 충격파의 형태가 어떻게 달라지는지를 예측하기 위한 모델을 학습했다. RAE2822는 충격파가 쉽게 형성되는 천음속 영역에서 운용되는 supercritical 익형으로, 형상 변화가 충격파 발생 특성에 민감한 영향을 미친다. 본 연구는 이러한 점을 고려하여 RAE2822를 기준 익형으로 설정하고, 기준 익형의 형상을 CST(Class/ Shape-function Transformation) parametrization method[15]를 통해 변형함으로써 형상 변화와 충격파 형성 유무간의 상관관계를 분석하였다. CST는 잘 알려진 에어포일 매개변수화 방법의 하나로써, 다음과 같은 class function과 shape function을 통해 에어포일을 표현한다.
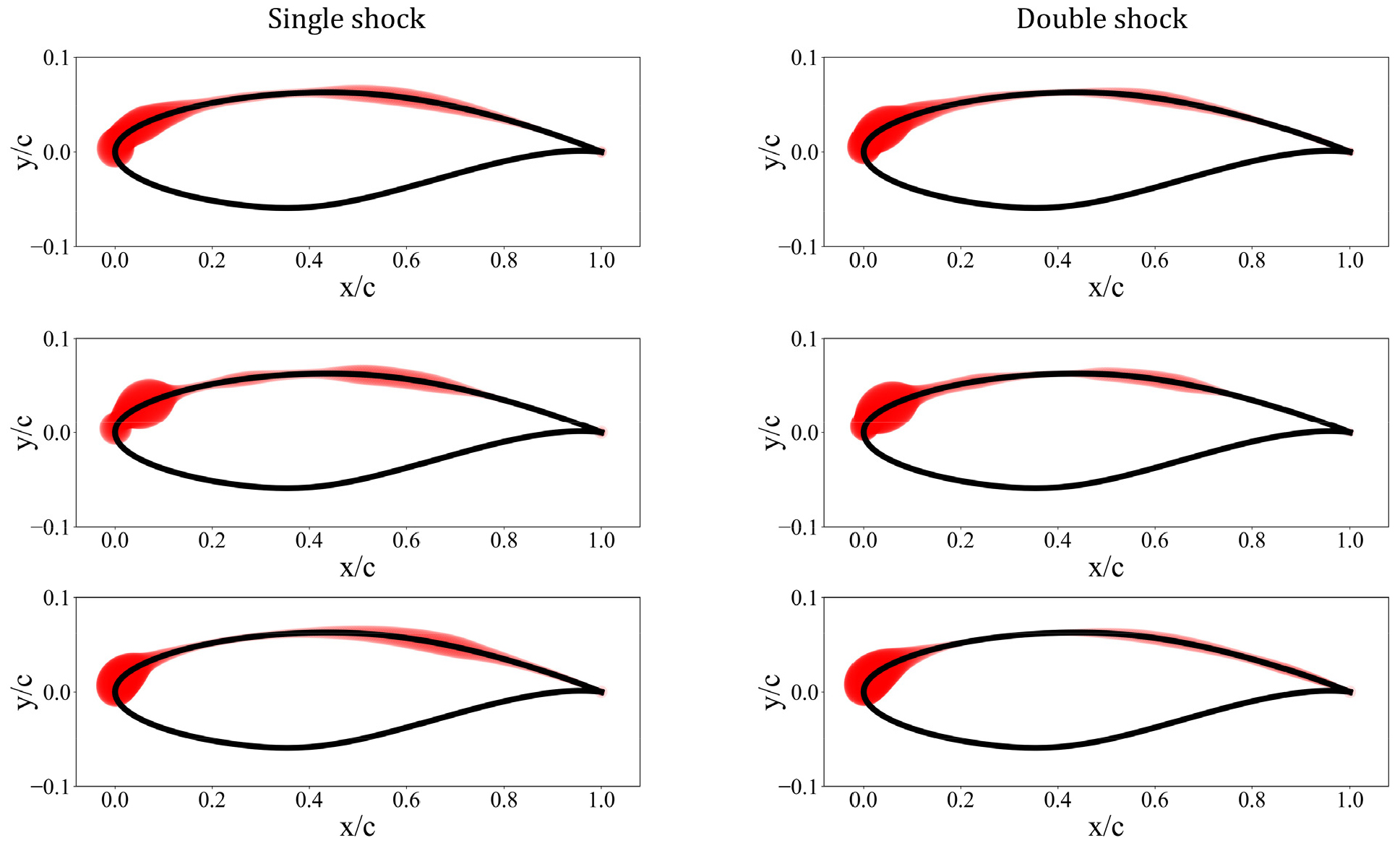
식 (5)에서 class function은 기준 형상을 설정하는 역할을 하며, 익형의 경우 N1=0.5, N2=1 로 설정된다. Shape function은 기준 형상을 변형하는 scaling function의 역할을 하며, Bernstein polynomial로 정의된다. 따라서 Bernstein polynomial basis의 각 계수의 조절을 통해 형상을 변형할 수 있고, Bernstein polynomial의 차수를 통해 익형 매개변수의 자유도를 조절할 수 있다. 본 연구에서는 익형 상단부와 하단부 모두 3차 Bernstein polynomial을 사용하였으며, 이에 따른 형상 변수는 각각 4개씩 총 8개이다. 각 형상 변수의 범위는 RAE2822 기준 익형으로부터 ±0.05로 설정하였고, 해당 범위에서 Latin hypercube sampling을 통해 총 500개의 익형 sample을 획득하였다. Fig. 4는 이렇게 얻어진 익형 데이터셋을 시각화 하여 나타낸 것으로, 점섬으로 표시된 형상이 기준 익형은 RAE2822에 해당한다.

3.2 유동 해석
익형들의 공력 데이터를 계산하기 위해서, 유한체적법 기반의 RANS(Reynolds-averaged Navier-Stokes) 해석자인 KFLOW 를 이용했다[16,17]. KFLOW는 정렬 격자 기반의 압축성, 점성 해석자로서, 다수의 천음속 및 초음속 유동 해석에 그 정확성과 강건성이 검증된 해석자다. 본 연구에서는 천음속 영역의 에어포일 공력 해석을 위해 충격파 포착에 적합한 풍상 차분 기반의 AUSMPW+ 기법을 유량 함수로 사용했으며, 높은 공간 정확도를 위해 5-6차 정확도의 eMLP- VC[16]를 제한자로 사용했다. 정상 상태를 가정한 해석을 진행하기 위해 시간 적분 방법으로는 1차 후방차분법을 이용하였으며, DADI[18] 기법을 이용 하여 효율적인 자코비안 역행렬 해석을 진행하였다. 또한 국부 시간 전진 기법을 이용하여 수렴 속도를 높였으며, 이때 적용한 CFL 수는 4이고, 총 50,000번의 계산을 수행하여 수렴된 결과를 얻었다. 에어포일 유동은 완전 난류로 가정했으며, 이를 위해 Spalart-Allmaras noft2 방정식[19]을 추가로 사용하여 난류를 모사했다. 해석에 사용된 격자는 코드 방향과 수직 방향으로 각각 601개, 115개 사용되었으며, O-grid 형태로 구성했다. 경계층 내부의 속도 분포를 제대로 모사하기 위해 첫 번째 격자 간격은 1.0 × 10-6으로 하였으며, 성장률은 1.15로 두었다.
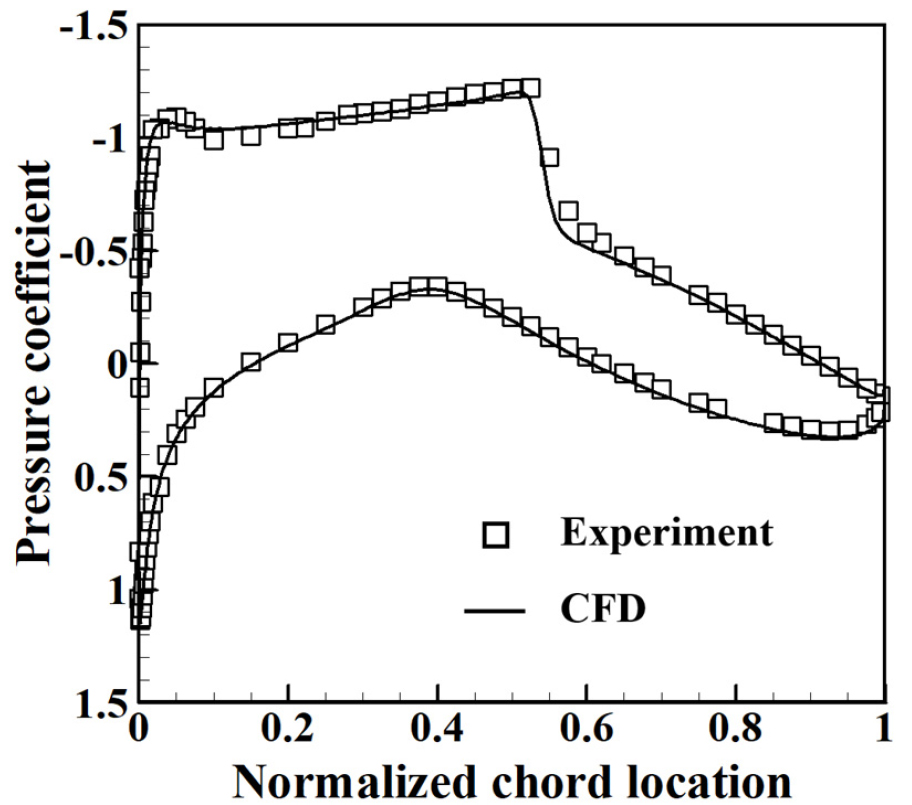
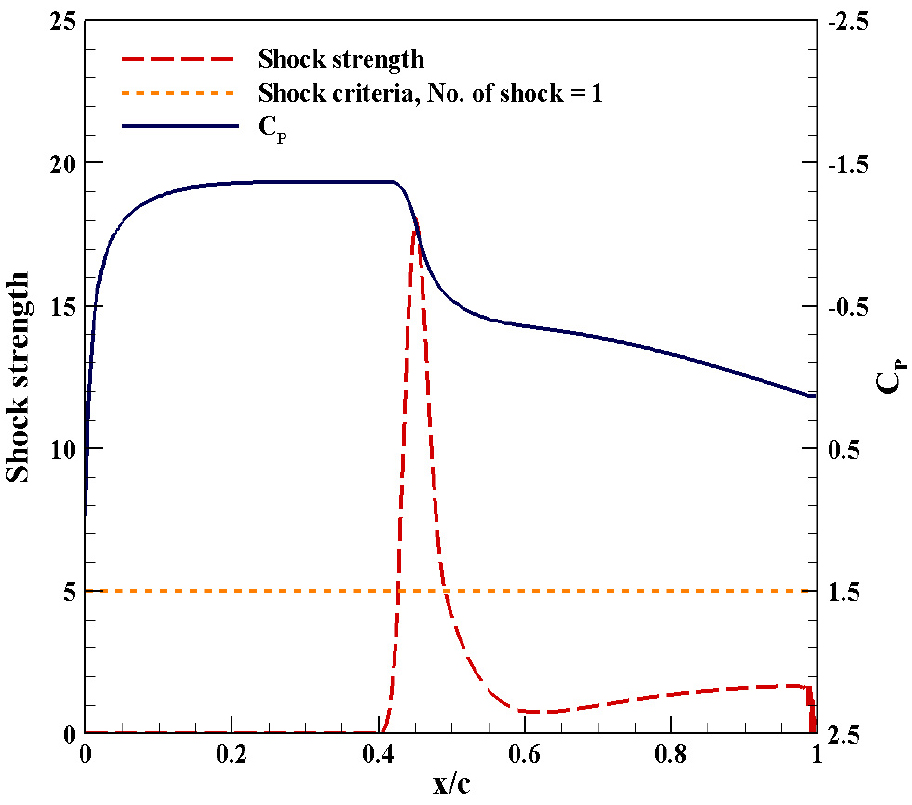
본 연구에서 사용된 천음속 익형은 자유류 마하수 0.729, 레이놀즈 수 6.2 × 106, 받음각 2.31° 조건 하에 유동 해석이 이루어졌다. 해당 유동 조건에서 RAE2822 익형에 대한 실험과 KFLOW 유동 해석 결과는 Fig. 5에 제시되어 있다. KFLOW 결과가 충격파의 위치 및 강도를 정확하게 예측하는 것을 확인할 수 있다.
충격파 강도는 식 (6)과 같이 정의하였다[20]. 이는 표면 압력 분포의 1차 미분 값이며, 유동이 충격파 통과 시 압력의 변화가 크다는 물리적인 특징을 활용하여 충격파 강도를 정의하였다. 이와 같은 원리로 충격파 포착을 위해 압력 분포의 2차 미분 값을 사용한 공기역학자[21]도 있으나, 본 연구에서는 충격파 강도를 정의하기 위해 1차 미분 값을 사용하였다. 또한, 끝이 뭉툭한 익형을 해석하는 경우, 익형 끝단에서 충격파가 아님에도 압력이 크게 증가하는 현상이 일어나는데, 이를 오인하여 충격파로 인지하는 문제를 피하기 위해 충격파는 0 ≤ x/c ≤ 0.99 에서만 생긴다고 가정하였다. 식 (6)으로 정의된 충격파 강도가 특정한 강도보다 증가 시, 해당 영역에 충격파가 생긴 것으로 간주하였으며, 이때 기준으로 사용된 값은 5이다. 충격파로 인해 압력을 포함한 밀도, 속도 등의 원시 변수에 불연속이 생기며, 강도가 강할수록 불연속 구배가 더욱 커진다. 그러나 강도가 약한 충격파의 경우, 구배가 상대적으로 작아서 유동 변화가 충격파로 인한 변화인지 구분하기 어렵다. 따라서 본 연구에서 사용된 충격파 정의와 기준은 임의성이 강하며, 이를 정확하게 정의하는 작업은 추후 연구로 남겨두고자 한다. 총 500개의 익형 중 356개의 익형이 이중 충격파를, 143개의 익형이 단일 충격파를 가지고 있었으며, 1개의 익형이 충격파를 포함하지 않았다. 이중 충격파 데이터에 대한 압력 계수 분포는 Fig. 6과 같다.
4. 모델, 학습 방법 및 평가 방법
4.1 모델링 및 학습방법 선정
본 연구에서는 순방향 및 역방향으로 학습이 가능한 양방향 LSTM(bi-directional LSTM)을 기반으로 네트워크를 구축했다. 멀티 헤드 어텐션의 설명성 개선 정도를 확인하기 위해, 싱글 헤드 어텐션 모델과 4개, 16개의 어텐션 헤드를 가진 두 개의 멀티 헤드 어텐션 모델을 구축했다. Table 2과 같이 모든 모델은 어텐션 헤드 수를 제외한 모든 파라미터를 동일하게 설정했다. LSTM 층의 입력 차원은 (batch size, 600, 1)로 (600, 1)은 익형의 x방향으로 순차적인 y좌표의 포인트 수에 해당한다. LSTM layer의 출력 차원은 (batch size, 600, 64)로 (600, 64)는 각 y좌표 포인트의 LSTM 층의 은닉 상태를 나타낸다. 이후 Fig. 7과 같이 LSTM 층의 은닉 상태를 사용하여 어텐션을 수행한다.
Table 2.
Model hyperparameter setting
본 연구에서는 LSTM 층의 정보를 담고 있는 마지막 포인트의 은닉 상태를 어텐션의 쿼리로 사용했다. 키와 값으로는 LSTM 층의 모든 은닉 상태를 사용했다. 키와 값은 학습 가능한 가중치가 있는 순방향 신경망을 통해 변환하고, 쿼리와 키의 벡터 공간을 맞춰주기 위해 활성화 함수로는 tanh를 사용했다. 이후 변환된 정보를 통해 어텐션 스코어를 계산한다. Table 1의 alignment 함수 중 내적을 기반으로 하는 함수를 사용했다. 이후 어텐션 스코어는 softmax 함수를 통해 확률 분포인 어텐션 가중치 분포로 정규화하고, 어텐션 분포와 값(v)의 가중합을 통해 컨텍스트 벡터를 구한다.
멀티 헤드 어텐션은 싱글 헤드 어텐션과 같이 마지막 포인트의 은닉 상태를 쿼리로, LSTM 층의 모든 은닉 상태를 키와 값으로 사용했다. 멀티 헤드 수가 N이라면, 키인 LSTM 층의 모든 은닉 상태는 N개의 순방향 신경망을 통해 변환된 후, 모든 헤드에 대해 N개의 어텐션 스코어를 계산하여 그 평균을 구한다. 기존의 멀티 헤드 어텐션과 다르게 컨텍스트 벡터에서 연결되는 것이 아닌 어텐션 분포를 구하는 과정에서 헤드 간의 연결을 진행했다.
어텐션을 통해 계산된 컨텍스트 벡터는 쿼리인 LSTM 층의 마지막 포인트의 은닉 상태와 결합하고 순방향 신경망을 통과 후 최종 예측을 수행한다. 충격파의 개수 ∈{1,2}로 정의되므로, 최종 예측 층의 활성화 함수로 sigmoid를 사용했다. 모든 모델의 학습은 어텐션 분포에 대한 정량적 평가를 위해 10번 반복하여 학습했다.
4.2 평가 지표
XAI 기법은 이해관계자와 의사결정자에게 기본 모델에 대한 설명의 신뢰성을 보장하는 것이 중요하다. 그러나 어텐션은 신경망 내부의 가중치를 기반으로 계산되기 때문에, 동일한 신경망이라도 매 학습마다 어텐션의 결과가 달라진다는 한계가 있다. 일관되지 않은 결과는 어떤 영역이 중요한지 확인할 수 없어 모델에 대한 설명성이 낮아진다. 이러한 이유로, 어텐션의 일관성을 개선하기 위해 본 연구에서는 멀티 헤드 어텐션 기법을 사용했다. XAI의 설명성을 정량적으로 평가하는 기존 연구[22,23,24]의 경우, 어텐션과 다르게 입력의 섭동을 기반으로 계산되는 기법들에 초점이 맞춰져 있었기에, 본 연구에서는 어텐션의 정량적 평가를 위해 충실도(fidelity)와 안정성(stability) 지표를 제시했다. 확률 분포인 어텐션 가중치를 평가하기 위해 정보 이론에서 정보량의 기댓값을 나타내는 엔트로피(entropy)를 기반으로 충실도와 안정성 지표를 제안했다. 각 지표의 세부적인 내용은 아래와 같다.
4.2.1 충실도(Fidelity)
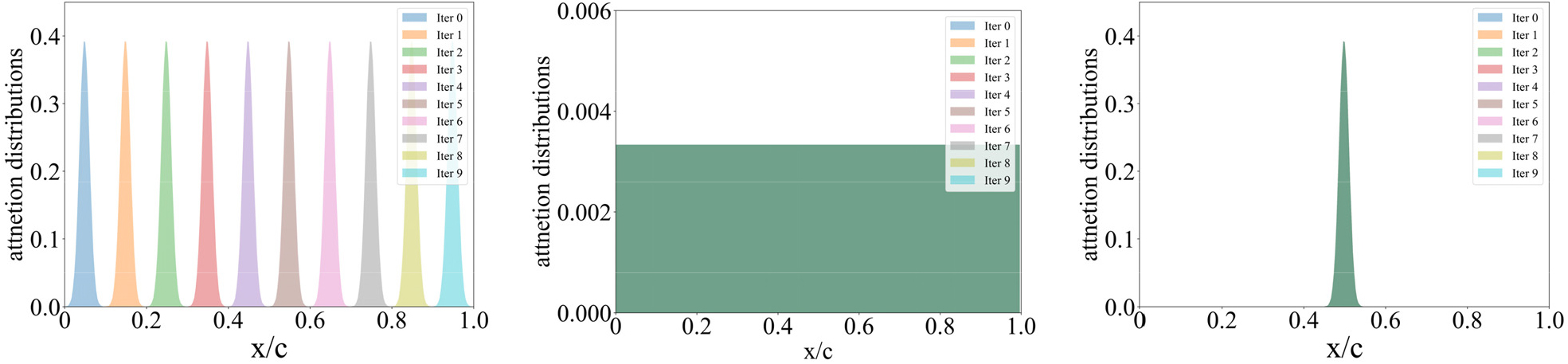
충실도는 반복적인 학습 과정에서 계속해서 어텐션 가중치가 중요한 위치에 집중되는 정도를 나타내는 지표다. 충실도의 지표는 섀넌 엔트로피(Shannon entropy)를 사용하였다. 섀넌 엔트로피란 이산 데이터에 대해 엔트로피를 일반식으로 표현한 것으로 모든 사건 정보량의 기댓값을 의미한다. 엔트로피는 [0, 무한대]의 범위로 정의되며 사건의 분포가 결정적(deterministic)이라면 값이 낮아지고 반대로 분포가 균등적(uniform)일수록 값이 높아진다. 충실도는 식 (7)과같이 n번의 학습에 대한 엔트로피의 평균으로 정의했다. 따라서 충실도의 값이 0에 가까울수록 어텐션 분포가 중요한 영역에만 집중하는 분포를 갖는다. Fig. 8에서 충실도가 높을 경우와 낮을 경우 각각의 어텐션 분포를 확인할 수 있다.
4.2.2 안정성(Stability)
안정성은 반복되는 학습 과정에서 계속해서 어텐션 가중치가 동일한 위치에 분포하는 정도를 나타내는 지표다. 본 연구에서 안정성의 지표는 KLD(Kullback–Leibler Divergence)를 사용하여 제안하였다. KLD는 두 확률 분포의 엔트로피를 비교하여 얼마나 유사한지를 평가하는 상대적 엔트로피 지표다. KLD는 [0, 무한대]의 범위를 가지며 두 확률 분포가 동일할수록 0으로 수렴한다. 안정성은 n번의 학습에서 만들 수 있는 모든 쌍에 대한 KLD의 평균으로 정의했다. 따라서 안정성의 값이 0에 가까울수록 어텐션 분포가 매 학습마다 동일한 분포를 나타낸다. Fig. 8에서 충실도가 높을 경우와 낮을 경우 각각의 어텐션 분포를 확인할 수 있다.
5. Result
5.1 예측 성능 평가
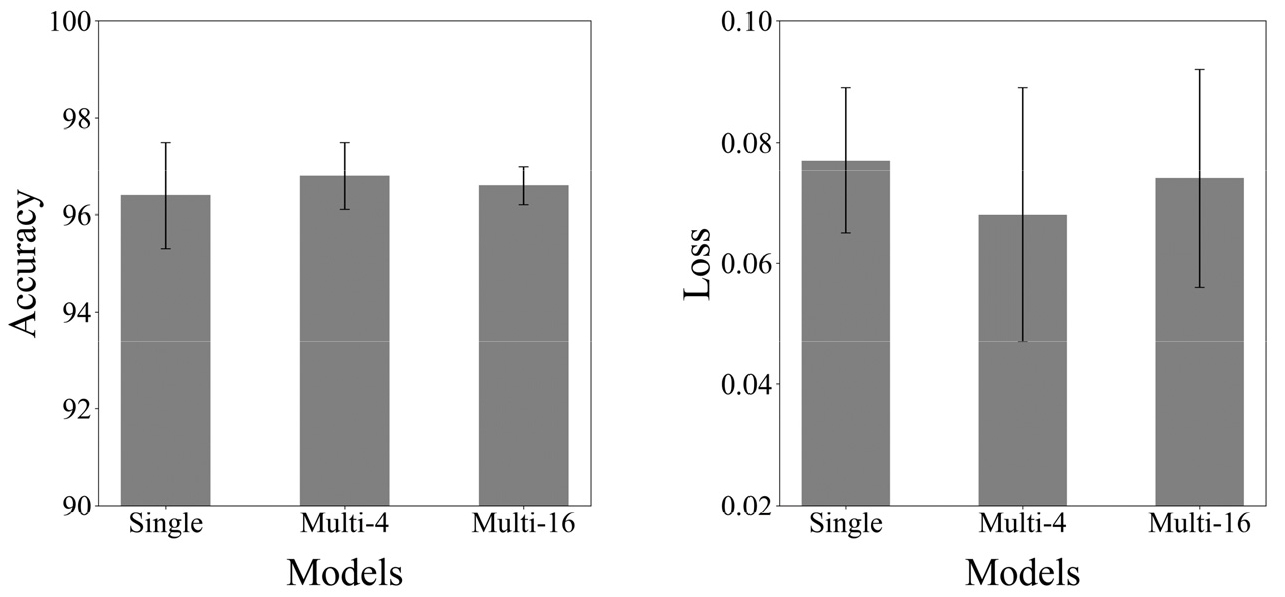
예측 성능은 각 모델의 정확도와 수렴된 손실 값에 대해 평가했고, 학습에 사용하지 않은 500개의 테스트 데이터로 성능을 검증했다. Table 3은 전체 학습에 대한 예측 결과를 나타낸 것이다. 각 구조에 대해 10번씩 반복한 학습의 정확도, 손실값, 평균값을 나타냈다. Fig. 9는 각 구조에 대한 정확도와 손실 값의 평균 및 표준편차를 나타낸 것이다. 평균값으로 볼 때, Multi-4, Multi-16, Single 순으로 성능이 좋았다. 가장 성능이 좋은 Multi-4의 10번째 학습은 0.047의 손실 값과 98.1%의 정확도를 보였다. Single은 일반적으로 0.06 ~ 0.08의 손실 값을 보였다. Multi-4는 손실 값이 다소 큰 7번째 학습을 제외하고, 0.07 이상의 손실 값이 없었다. Multi-16은 손실 값의 범위가 Single과 Multi-4의 범위를 포함한 것과 같이 큰 모습이다.
Table 3.
Performance according to model structure
5.2 설명성 평가
어텐션 분포의 설명성은 본 연구에서 제시한 충실도와 안정성 지표를 통해 평가했다. 500개의 테스트 데이터는 단일 충격파 366개, 이중 충격파 134로 이루어졌다. 각 클래스를 동일한 개수로 평가하기 위해, 예측 성능 평가와 다르게 각 클래스에 대해 100개의 데이터만 사용하여 설명성을 평가했다. 모든 평가는 각 구조마다 10번씩 반복한 학습 결과의 평균으로 계산했다.
5.2.1어텐션 분포
Fig. 10에서 확인할 수 있듯이 모든 모델에서 어텐션 분포는 비슷하게 단일 충격파, 이중 충격파 형상 모두 주로 익형 상단 전반부와 중반부에 생성되었다. 다만, 이중 충격파 형상의 경우, 단일 충격파 형상보다 전반부 영역에 가중치가 더 크게 분포했다. 공기역학적인 관점에서 이러한 분포를 살펴보면, 다음과 같이 요약할 수 있다: 1) 우선, 익형 상단 전반부는 가장 굴곡이 심한 곳으로 유동의 가속화가 급격하게 이루어지는 곳이다. 즉, 다시 말해 전반부에서 유동의 가속화가 얼마나 빠른 속도로 이루어졌느냐에 따라 충격파의 개수, 그리고 그 강도가 정해지게 된다. 그 이후 유동이 익형을 따라 흐르며 상단 중반부의 형상에 따라 충격파의 위치가 정해진다. 2) 두 번째로, 전반부 영역에 가중치가 더 크게 분포되는 익형의 경우 이중 충격파를 갖는다는 특징이 있는데, 이는 익형 상단 전반부가 이중 충격파의 여부에 훨씬 더 크게 영향을 미친다는 것으로 해석할 수 있다.
5.2.2충실도(Fidelity)
충실도는 Table 3과 같이 멀티 헤드 어텐션 모델들이 싱글 헤드 어텐션 모델보다 더 좋은 결과를 보였다. 특히, 4개의 헤드를 사용한 모델(Multi-4)이 6.69로 가장 우수한 충실도를 나타냈다. Fig. 11, 12에서 볼 수 있듯이, 멀티 헤드 어텐션 모델들은 싱글 헤드 어텐션 모델보다 분포의 첨도가 증가하고 분산도는 감소하는 형태로 형성되었다. 이와 같이 멀티 헤드 어텐션에서는 중요한 영역에 대한 확실성이 높아짐으로써, 더욱 높은 충실도의 결과를 나타냈다. 또한 예측 성능이 좋을수록, 충실도 역시 더 좋은 결과를 보였다. 충실도가 높을수록 모델이 중요한 영역을 잘 표현하고 이를 학습에 사용했기 때문에 더 높은 예측 성능을 보였다고 할 수 있다.
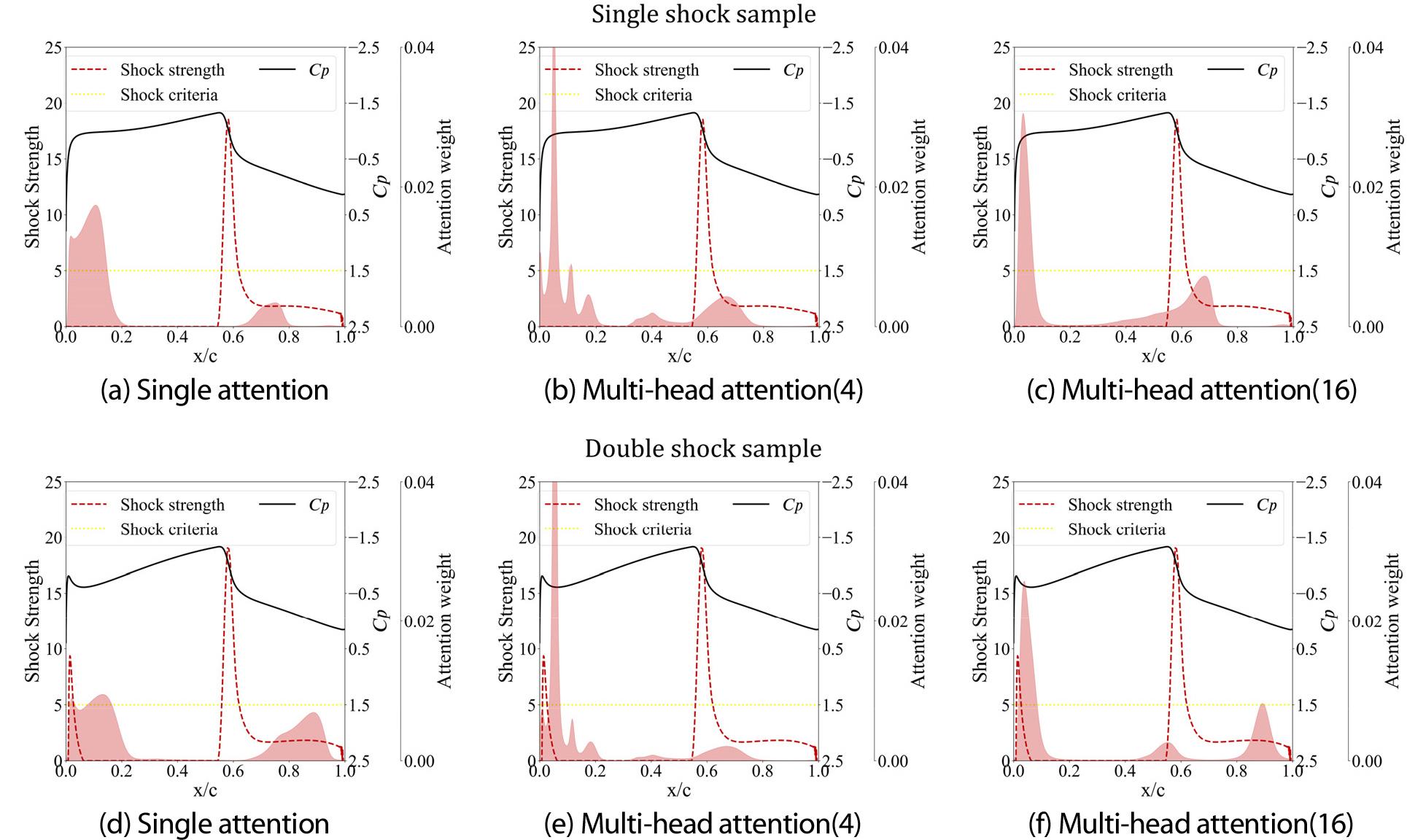
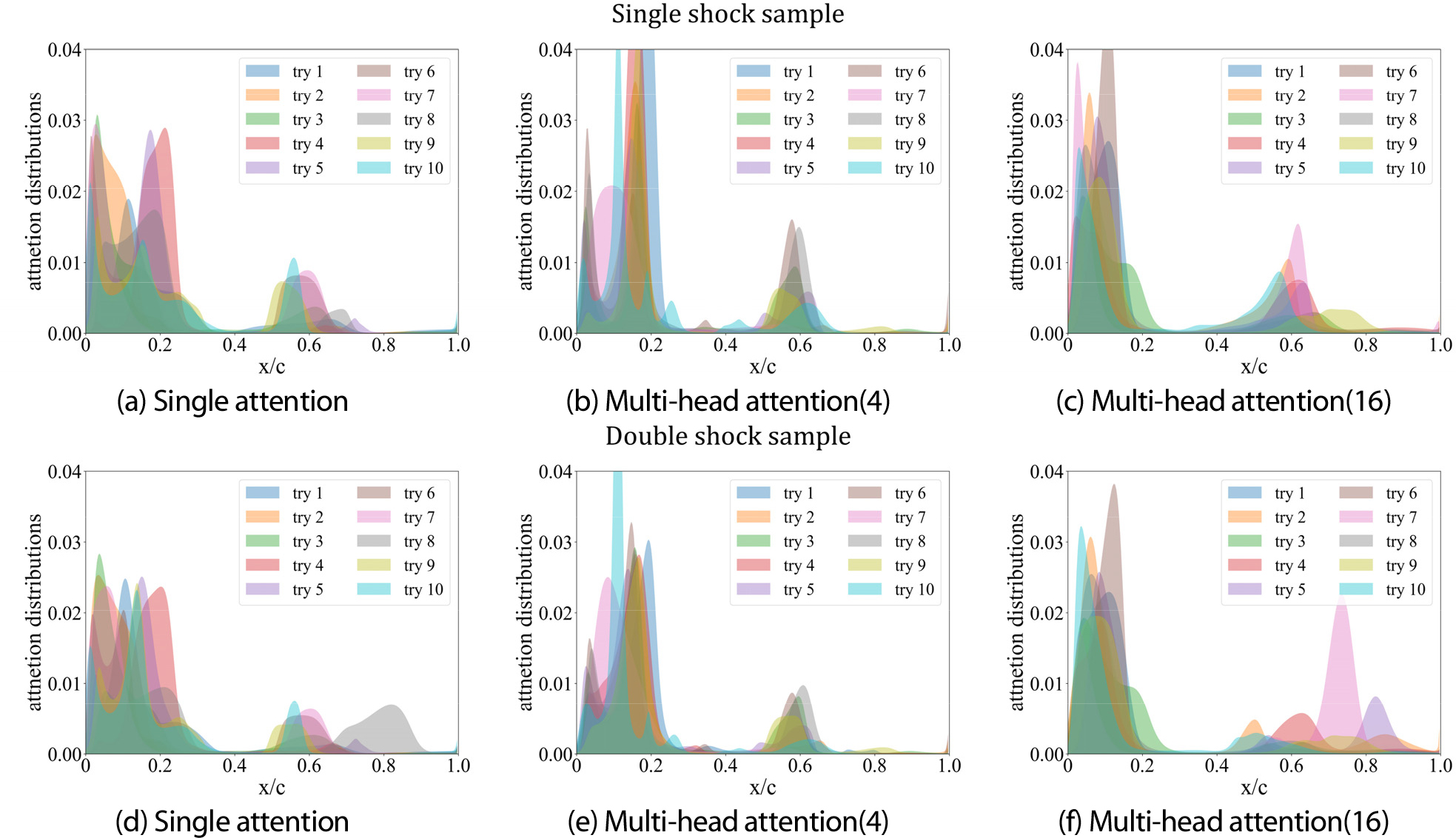
또한 Table 4에서 이중 충격파보다 단일 충격파에서 충실도가 비슷하거나 더 높은 것을 확인할 수 있다. Fig. 10, 11과 같이 이중 충격파의 경우, 상단 전반부에 가중치가 주로 분포되는 반면, 단일 충격파는 이중 충격파에 비해 상단 중반부에 가중치가 더 할당된다. 따라서 단일 충격파는 이중 충격파에 비해 분산도가 증가하기 때문에 충실도가 비슷하거나 더 높은 결과를 보였다.
Table 4.
Evaluation according to model structure
5.2.3 안정성(Stability)
안정성 역시 멀티 헤드 어텐션 모델들이 싱글 헤드 어텐션 모델보다 더 좋은 결과를 보였다. 특히, 16개의 헤드를 사용한 모델(Multi-16)이 4.93으로 가장 우수한 안정성을 보였다. Fig. 11에서 볼 수 있듯이, 멀티 헤드 어텐션 모델들은 싱글 헤드 어텐션 모델보다 분포가 생성되는 위치뿐만 아니라, 크기까지 유사해지는 것을 통해 더욱 높은 안정성을 보였다. 안정성이 충실도와 다르게 Multi-16에서 가장 좋은 결과를 보인 이유는 예측 성능보다는 일반화와 더 큰 관계가 있는 것으로 판단된다. 멀티 헤드 어텐션이 다수의 어텐션 헤드를 합치는 과정에서 최적의 결과를 위한 일반화가 이루어졌기 때문에 많은 헤드를 사용할수록 안정성이 높아졌다고 해석할 수 있다.
또한 단일 충격파는 이중 충격파보다 안정성이 낮은 결과를 보였다. Fig. 9, 10과 같이 이중 충격파는 가중치가 생성되는 위치가 단일 충격파 결과 대비 한정적이기 때문에 Multi-16보다 일반화 성능이 낮은 Multi-4가 더 좋은 안정성을 보인 것으로 판단된다. 반면에 단일 충격파는 이중 충격파보다 가중치가 위치가 넓게 생성되기 때문에, 일반화 성능이 가장 좋은 Multi-16이 가장 좋은 결과를 보였다.
6. Conclusion
본 연구에서는 CFD를 통해 획득한 데이터를 이용해 익형의 형상에 따른 충격파의 타입을 예측하는 문제에 어텐션 기반의 신경망 모델을 적용하였다. 어텐션이 적용된 신경망을 통해 입력(익형 형상)에 대한 출력(충격파 타입)의 상대적 중요성을 산출할 수 있었다. 결과적으로 익형 상단의 전반부와 중반부에 가중치가 분포되는 것을 확인하였으며 이는 공기역학적 배경지식과 일치하는 것을 알 수 있었다. 또한 어텐션의 설명성을 개선하기 위해 어텐션 헤드를 병렬로 배치하는 멀티 헤드 어텐션 기법을 사용했다. 개선 정도를 확인하기 위해 어텐션의 설명성을 정량적으로 평가할 수 있는 충실도와 안정성 지표를 제시하였다. 이를 통해 멀티 헤드 어텐션의 적용은 어텐션 분포의 분산도를 감소시켜 충실도를 개선할 수 있고 일반화를 통해 안정성을 개선시킬 수 있다는 것을 확인하였다. 본 연구에서는 XAI 결과를 용이하게 해석하기 위해 공기역학적 문제로 익형의 충격파를 다루었지만, 현재의 접근 방식을 복잡한 흐름 문제에 적용하면 더 많은 논의가 가능할 것이 기대된다.
