

1. 서 론
2. 배경 이론
2.1 Explainable Artificial Intelligence
2.2 Counterfactual Explanations
3. 데이터 준비
3.1 문제정의 및 익형 생성
3.2 유동 해석
4. 모델, 학습 방법 및 평가 방법
4.1 모델링 및 학습방법 선정
4.2 평가 지표
5. 결과 및 분석
5.1 반사실적 설명 생성 결과
5.2 정량적 평가 및 방법론 특성 분석
5.3 물리적 분석
6. 결 론
1. 서 론
현대 공학 설계에서는 성능, 비용, 안전성 등 다목적 요구사항을 동시에 만족시켜야 하며, 이를 위해 유동 특성을 정밀하게 예측하는 CFD 시뮬레이션이 설계 평가의 핵심 도구로 활용된다. 그러나 CFD는 상당한 계산 자원과 시간이 요구되기 때문에 방대한 설계공간을 전역적으로 탐색하는 것이 매우 어렵다. 이를 극복하기 위해 CFD를 대체하는 대리 모델(surrogate model) 기반 설계 기법이 활발히 연구되어 왔다. 전통적인 대리 모델(예: 반응표면법(Response Surface Method, RSM), 크리깅(Kriging))은 계산 효율성을 높이는 데 기여하였으나, 설계변수 간의 복잡한 비선형 관계를 충분히 표현하는 데 한계가 있었다[1,2]. 이러한 맥락에서 최근에는 딥러닝 기반 근사 모델이 주목받고 있으며, 다층 신경망 구조를 통해 고차원·비선형 설계공간을 보다 정밀하게 근사할 수 있다는 장점으로 인해 CFD 대리 모델로서의 활용이 빠르게 확산되고 있다[3].
그러나 딥러닝 기반 설계는 근본적으로 블랙박스(black-box) 문제를 내포하고 있다. 모델이 특정 설계를 최적해로 제시하더라도, “왜 이 설계가 좋은지”, “어떤 설계변수가 성능에 지배적인 영향을 미치는지”에 대한 인사이트를 얻기 어렵다. 이러한 해석가능성 부족은 실무 설계 과정에서 중요한 한계로 작용한다. 설계자는 모델이 제시한 결과를 신뢰하기 어렵고 예상치 못한 설계 실패에 대응하기 어렵다. 한편 기존의 최적설계 방식은 명시적으로 수식화된 성능 목표와 기하학적 제약만을 반영하여 전역 최적해를 탐색하는 데 초점을 맞추어 왔다. 그러나 실무적 관점에서 최적설계는 제조 가능성, 유지보수성, 기존 시스템과의 호환성 등 다양한 암묵적 제약이 존재하며, 베이스라인 설계에는 이미 이러한 암묵적 제약들이 반영되어 있는 경우가 많다. 명시적 제약만을 기반으로 한 전역 탐색은 베이스라인으로부터 크게 벗어난 설계안을 도출하는 경향이 있어, 겉보기에는 최적이더라도 실제 적용 과정에서 예측하지 못한 문제를 야기할 수 있다. 따라서 전역 최적해를 찾기보다는, 기존 설계를 크게 벗어나지 않으면서 성능을 점진적으로 개선하는 것이 실질적으로 더 유용한 경우가 많다.
이러한 문제를 해결하기 위해, 본 연구에서는 설명 가능한 인공지능(Explainable AI, XAI) 기법을 설계 탐색 과정에 도입했다. XAI는 모델의 의사결정 과정을 투명하게 만들어 설계적 인사이트를 제공한다[4]. 특히 XAI 기법 중에서도 반사실적 설명(Counterfactual Explanation, CE)은 “원하는 결과를 얻기 위해 어떤 변수를 얼마나 바꿔야 하는가”라는 구체적인 설계 변경 방안을 제시한다는 점에서 주목받고 있다[5]. 이는 베이스라인 설계로부터의 최소 변경을 통해 목표 성능을 달성하는 방식으로, 앞서 언급한 암묵적 제약 보존과 점진적 개선이라는 실무적 니즈와 부합한다. CE를 공학 설계 문제에 적용한 선행 연구로는 Groha et al.[6]의 연구가 있다. 이들은 자전거 설계에 CE를 적용하여, 현재 자전거 형상과 텍스트로 표현된 설계 목표를 동시에 고려함으로써 다양한 설계 대안을 생성하였다.
본 연구에서는 이러한 CE를 천음속 익형의 공력 특성 설계 문제에 적용하고자 한다. 천음속 영역은 익형 형상의 미세한 변화만으로 충격파가 생성될 수 있기 때문에 형상 설계가 매우 중요한 영역이다. 이렇게 형성된 충격파는 항력을 급격히 증가시킬 뿐만 아니라, 천음속 버페팅과 같은 비정상 유동 특성을 유발하여 하중 분포와 모멘트를 불안정하게 만들고, 특히 충격파 이후에 천이가 발생하면 양력 및 항력의 변동이 더욱 심화되어 항공기 제어를 어렵게 한다. 따라서 천음속 익형 설계는 충격파를 원천적으로 회피하거나, 불가피한 경우 뒷전 쪽으로 이동시키며 충격파 강도를 최소화하는 방향으로 진행되어 왔다.
이를 위해 다양한 최적설계 기법이 연구되어 왔다. Li et al.은 머신러닝 기반 공력 형상 최적화 연구를 체계적으로 검토하며, ASO에서 다루는 제약 조건은 두께·면적·체적 등의 기하학적 제약과 양력계수·모멘트계수 등의 공력적 제약 두 종류로 정의되어 있음을 보였다[7]. 그러나 이러한 선행연구들은 양항비 또는 항력계수와 같은 명시적으로 정량화 가능한 성능 지표를 최적화하는 데 초점을 맞추고 있으며, 설계 변경이 가져올 수 있는 구조적 제약, 제조 가능성, 기존 시스템과의 호환성 등 암묵적 제약은 충분히 반영되지 못하는 한계가 있다. 특히 전역 최적해를 탐색하는 과정에서 베이스라인 설계로부터 크게 벗어난 형상이 도출되는 경향이 있어, 실무 적용 관점에서 현실성이 낮은 설계안이 제시될 수 있다. 또한 기존에는 일부 설계변수가 충격파에 민감하다는 직관이 존재했다. 하지만 이러한 직관만으로 복잡한 설계변수 공간에서 각 변수의 상대적 중요도를 정량적으로 파악하기 어렵다는 한계가 있었다.
이러한 배경에서, 최근에는 XAI 기법을 활용하여 천음속 익형의 충격파 발생에 영향을 미치는 주요 설계 변수를 해석하려는 연구들이 수행되었다[8,9]. 그러나 이러한 연구들은 주로 어떤 변수가 중요한지를 식별하는 데 초점을 맞추었으며, 구체적인 형상 변경 지침을 제공하는 데는 한계가 있었다. 본 연구는 이러한 한계를 극복하기 위해 CE를 도입하여 “최소한의 형상 변경만으로 충격파를 저감할 수 있는가”라는 질문에 답하고자 하였다. 이를 위해 충격파 저감을 달성하는 구체적인 설계 대안을 도출하였고, 서로 다른 생성된 대안적 입력 데이터 생성 전략이 천음속 익형 설계에 미치는 영향을 정량적, 정성적으로 평가하였다.
2. 배경 이론
2.1 Explainable Artificial Intelligence
딥러닝 모델은 높은 예측 정확도를 보이지만, 내부 구조가 복잡하여 모델이 어떤 근거로 특정 예측을 수행했는지 직관적으로 이해하기 어렵다. 이러한 특성으로 인해 딥러닝은 일종의 블랙박스 모델로 간주되며, 모델의 예측 결과를 신뢰하기 어렵다는 한계가 존재한다. 이 문제를 해결하기 위해 제안된 접근이 XAI이다. XAI는 모델의 예측 결과를 해석하고, 각 입력 특성이 결과에 미치는 영향을 정량적 또는 시각적으로 설명함으로써 모델의 투명성과 신뢰성을 확보하는 것을 목표로 한다. 대표적인 XAI 기법으로는 LIME(Local Interpretable Model-agnostic Explanations)[10], SHAP(SHapley Additive exPlanations)[11], EBM(Explainable Boosting Machine)[12], LRP(Layer-wise Relevance Propagation)[13], 그리고 CE[5] 등이 있다. 이들 중 대부분의 기법은 “모델이 왜 그렇게 예측했는가”를 설명하는 데 초점을 맞추는 사후적 해석 기법이다. 반면, CE는 “원하는 예측 결과를 얻기 위해 입력을 어떻게 변경해야 하는가”를 제시한다는 점에서, 예측의 해석 가능성뿐 아니라 행동 가능한 지침을 동시에 제공한다. 본 연구에서는 CE의 이러한 특성이 익형 설계 문제에서 “충격파를 저감하기 위해 형상을 어떻게 수정해야 하는가”라는 질문에 직접적으로 답할 수 있다고 판단하였다.
2.2 Counterfactual Explanations
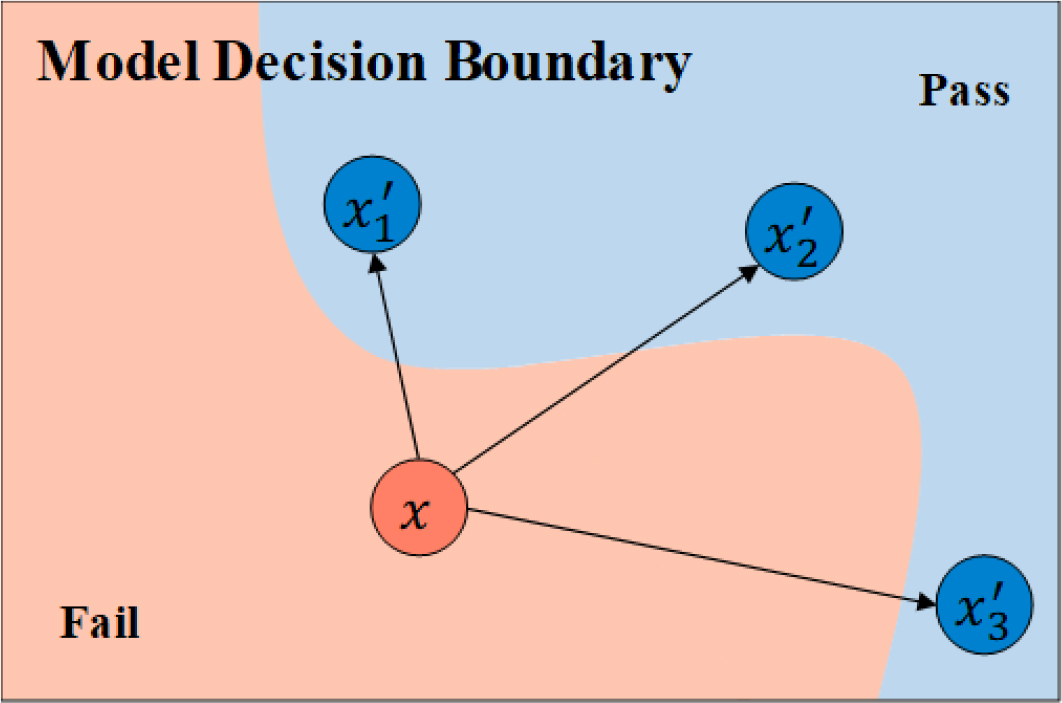
CE는 주어진 입력 (query)가 예측 결과 를 생성할 때, 목표 결과 을 얻기 위해 필요한 대안적 입력 (Counterfactual, CF)를 찾아 제시하는 기법이다. 이는 “만약 입력이 이렇게 달랐다면, 모델의 출력은 어떻게 달라질까”라는 반사실적 사고에 기반한다. Fig. 1은 대리 모델의 의사결정 경계 상에서 CE를 시각화한 것이다. 목표 결과를 달성하지 못한(fail) 영역에 위치한 초기 입력 에 대해, 목표 결과를 달성(pass)하는 영역 내의 대안적 입력들 , , 를 탐색한다. 각 CF는 목표 결과를 달성하기 위해 필요한 입력 변화의 방향과 크기를 나타낸다. 이를 통해 “어떤 입력 변화가 목표를 달성하게 만드는가”에 대한 직관적 설명을 제공한다.
Wachter et al.[5]은 CE를 최적화 문제의 형태로 정식화하였다. 모델 출력 f(·)에 대해 다음과 같은 목적함수를 최소화함으로써 CE를 정의하였다.
여기서 첫 번째 항은 모델 출력이 목표 예측 에 충분히 근접하도록 보장하며(유효성), 두 번째 항은 원본 입력 와의 거리를 최소화하여 현실적으로 가능한 변경만을 허용한다(근접성). 𝜆는 두 항의 상대적 중요도를 조절하는 가중치이다. 이후 연구들은 Wachter et al.[5]의 기본 틀을 확장하여, 다양성(diversity), 희소성(sparsity), 현실성(realism), 인과성(causality) 등 추가적인 제약 조건을 통합하려는 노력을 지속해왔다. 이러한 발전은 실제 의사결정 상황에서 실행 가능하고 의미 있는 설명을 생성하는 데 기여하고 있다.
본 연구에서는 DiCE(Diverse Counterfactual Explanation) 라이브러리[14]에서 제공하는 네 가지 CF 생성 기법(gradient-based, randomized sampling, k-dimensional tree, genetic algorithm)을 구현하고, 이들의 특성이 천음속 익형 설계라는 물리 기반 문제에서 어떻게 나타나는지 비교·분석한다.
2.2.1 Gradient-based method
Gradient 기반 방법은 모델의 출력이 목표 클래스로 전환되도록 입력 변수를 연속적으로 갱신하는 최적화 접근이다. Mothilal et al.[15]이 제안한 DiCE는 현재 가장 널리 사용되는 CF 생성 알고리즘으로, 단일 해(해당 목표 예측을 만족하는 하나의 )가 아닌 여러 개의 상이한 대안 입력 집합 {}을 생성한다. 이 방법은 Wachter et al.[5]의 기본 최적화식을 확장하여 다양성 항을 추가한 형태로 정의되며, 목적함수는 다음과 같이 표현된다.
여기서 k는 한 번에 생성하려는 CF의 개수이고 , 는 가중치 하이퍼파라미터이다. 는 생성된 CF가 목표 클래스를 만족하는지 측정하는 손실함수로, 본 연구에서는 hinge loss를 사용하였다.
dist(·, ·)는 두 벡터간의 거리를 나타내며, 중앙값 절대편차(MAD, Median Absolute Deviation)로 정규화한 맨해튼 거리를 사용하였다.
여기서 d는 입력 변수의 차원이고, 는 입력 변수 j번째 차원의 중앙값 절대편차이다. 목적함수의 두 번째 항에서는 로, 즉 CF와 원본 입력 간의 거리를 측정하는데 사용된다.
항은 결정적 점 과정(DPP, Determinantal Point Process)[16]을 통해 서로 다른 CF 간 거리가 충분히 벌어지도록 유도한다. 구체적으로, k개의 CF 집합 에 대해 커널 행렬 를 다음과 같이 정의한다.
여기서 는 CF i와 CF j 사이에 적용된다. Diversity loss는 이 행렬의 행렬식으로 정의된다.
두 CF 와 가 유사할수록 가 커져 행렬의 두 행이 선형 종속에 가까워지고, 그 결과 이 0에 수렴한다. 반대로 CF들이 서로 충분히 상이할수록 행렬식이 커지므로, 이를 최대화함으로써 다양한 CF 집합이 생성되도록 유도된다. 이와 같이 여러 후보를 동시에 탐색함으로써 사용자는 모델의 결정을 보다 풍부하게 이해하고, 설계 문제에서는 다양한 대안 형상을 비교할 수 있다. 다만 DiCE는 gradient 기반 최적화에 의존하기 때문에 신경망 형태의 함수나 미분 가능한 모델에 주로 적용되며, 손실함수 가중치 설정에 따라 결과 품질이 민감하게 변한다는 점이 한계로 지적된다.
2.2.2 Randomized sampling method
Random sampling 방법은 기존 입력으로부터 점진적으로 feature(이하 feature와 설계변수는 동일한 의미로 사용됨) 개수를 늘려가며 변형을 가하고, 그 중 목표 예측 y′을 만족하는 입력 x′을 CF로 채택한다. 이 방식은 복잡한 최적화 과정이나 모델의 gradient 정보가 필요 없고, 구현이 직관적이고 계산 비용이 낮다. 또한 feature를 점진적으로 수정하며 원본과 유사한 CF를 유도하고, 충분히 많은 샘플을 생성할 경우 다양한 조합을 탐색할 수 있다는 장점이 있다. 그러나 탐색이 완전히 무작위로 이루어져 품질이 일관되지 않은 CF 집합이 형성될 수 있으며, 원본과의 근접성이나 생성된 서로 다른 CF 간의 다양성을 보장하는 명시적 기준이 없다는 점에서 일반적으로 단순 비교용 혹은 초기 탐색 단계에서 활용된다.
2.2.3 K-dimensional tree method
K-dimensional tree(KD tree) 방법은 학습 데이터를 k차원 트리 구조로 구성하여 기존 입력과 유사하면서 목표 클래스에 속하는 실제 데이터 포인트를 검색하는 방법이다[17]. 이는 프로토타입 기반 설명의 일종으로, 학습 데이터 내 실존하는 인스턴스를 CF로 제시함으로써 데이터 분포를 벗어난 비현실적인 설명을 방지한다. 구체적으로, 목표 클래스에 속하는 데이터로 KD tree를 구축한 후, k-nearest neighbor 알고리즘을 통해 유클리드 거리 기준으로 원본 입력과 가장 가까운 후보들을 검색한다. 검색된 후보들은 거리와 변경된 feature 개수를 결합한 점수로 순위가 매겨진다. 이 방법은 실제 데이터 분포 내에서만 탐색하므로 생성된 CF의 현실성이 보장되며, 평균 검색 복잡도가 O(log N)으로 대규모 데이터셋에서도 효율적이다. 그러나 학습 데이터에 존재하는 샘플만을 CF로 제시하므로 새로운 설계 대안을 탐색하지 못하며, 데이터 밀도를 반영하지 않아 학습 데이터가 희박한 영역의 샘플이 선택될 경우, 상대적으로 실제 발생 가능성이 낮은 CF가 제시될 수 있다는 한계가 있다.
2.2.4 Genetic algorithm based method
Genetic algorithm(GA) 기반 방법은 생물학적 진화 과정을 모방하여, 초기 개체군을 생성한 후 선택, 교배, 돌연변이 과정을 반복하면서 CF를 탐색하는 방법이다. 본 연구에서 GA의 탐색 대상은 천음속 익형의 형상을 정의하는 CST 파라미터 이며, 각 개체는 하나의 익형 설계안에 해당한다. 각 개체의 적합도는 다음과 같이 정의된다.
여기서 는 생성된 CF가 목표 클래스를 만족하는지 측정하는 hinge loss이고, 는 식 (4)와 동일한 거리 함수로 원본 설계와의 근접성을 측정하며, 는 변경된 설계변수의 비율로 다음과 같이 정의된다.
, 는 각 항의 가중치 하이퍼파라미터이며, I[·]는 조건이 참이면 1을 반환하는 지시 함수이다. 적합도 평가 시 CFD 해석은 직접 수행되지 않으며, 사전 학습된 딥러닝 대리모델 f(·)을 통해 각 개체의 목표 클래스 달성 여부를 예측한다. 이를 통해 매 세대의 적합도 평가에 소요되는 계산 비용을 대폭 절감할 수 있다. 상위 적합도를 가진 개체들이 선택되어 교배를 통해 다음 세대를 생성하며, 다양성은 별도의 손실항 없이 교배와 돌연변이 연산을 통해 자연스럽게 확보된다. 본 연구에서는 KD tree 기반 초기화를 적용하여, 훈련 데이터에서 목표 클래스에 속하면서 원본 설계와 유사한 샘플들을 k-nearest neighbor 검색으로 추출하여 초기 개체군으로 설정하였다. 이는 무작위 초기화 대비 탐색 공간을 효과적으로 축소하여 수렴 속도를 향상시킨다. 이 방법은 교배와 돌연변이를 통해 학습 데이터에 존재하지 않는 새로운 CF를 생성할 수 있어 설계 공간 탐색 측면에서 유리하다. 다만 적합도 함수의 가중치 설정에 따라 결과가 민감하게 변할 수 있으며, 초기 개체군의 품질에 따라 최종 결과의 다양성이 제한될 수 있다. Table 1은 각 방법론의 주요 특성을 요약한 것이다.
Table 1.
Comparison of counterfactual explanation methods
3. 데이터 준비
3.1 문제정의 및 익형 생성
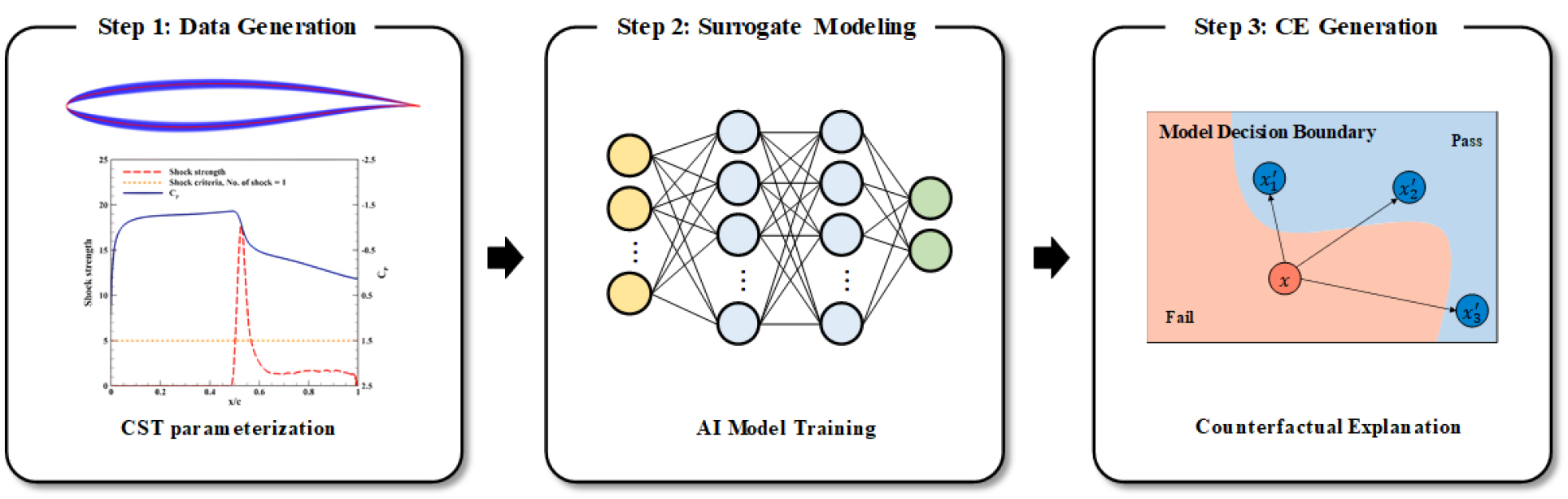
본 연구에서는 CE를 활용하여 천음속 익형의 충격파 저감 설계에 필요한 형상 변경 방향을 도출하고자 한다. Fig. 2는 연구의 전체 흐름을 보여주는 flowchart이다. Step 1에서는 천음속 익형 형상 설계를 위한 데이터셋을 구축하기 위해 다양한 익형 형상을 생성하고, CFD 시뮬레이션과 shock sensor를 통해 공력 성능 데이터를 획득한다. Step 2에서는 생성된 익형 형상과 충격파 개수 데이터를 기반으로 대리 모델을 학습시킨다. Step 3에서는 학습된 대리 모델에 CE를 적용한다.
이러한 방법론을 적용하기 위해서는 먼저 천음속 영역에서 충격파 형성에 민감한 기준 익형을 선정해야 한다. RAE2822는 천음속 영역에서 충격파 형성에 민감한 supercritical 익형이므로 본 연구의 기준 익형으로 선정하였다. 기준 익형은 CST(Class/Shape-function Transformation) parametrization method[18]를 통해 변형하였으며, 이를 통해 충격파 발생 특성에 대한 형상의 영향을 평가할 수 있는 데이터셋을 구축하였다. CST 방법에서 익형의 좌표는 다음과 같이 표현된다.
class function 는 익형의 기본 기하학적 특성을 결정하며 다음과 같이 정의된다.
익형의 경우 로 설정된다. Shape function 는 기준 형상을 변형하는 scaling function의 역할을 하며, n차 Bernstein polynomial로 다음과 같이 정의된다.
여기서 는 형상 계수(shape coefficient), 은 i번째 n차 Bernstein polynomial basis function이다. 각 계수의 조절을 통해 형상을 변형할 수 있고, Bernstein polynomial의 차수 n 선택을 통해 익형 매개변수의 자유도를 조절할 수 있다. 본 연구에서는 익형 상단부와 하단부 모두 3차 Bernstein polynomial을 사용하였으며, 이에 따른 형상 변수는 각각 4개씩 총 8개이다. 각 형상 변수가 익형에 미치는 영향에 대한 예시는 Fig. 3에 제시하였다.
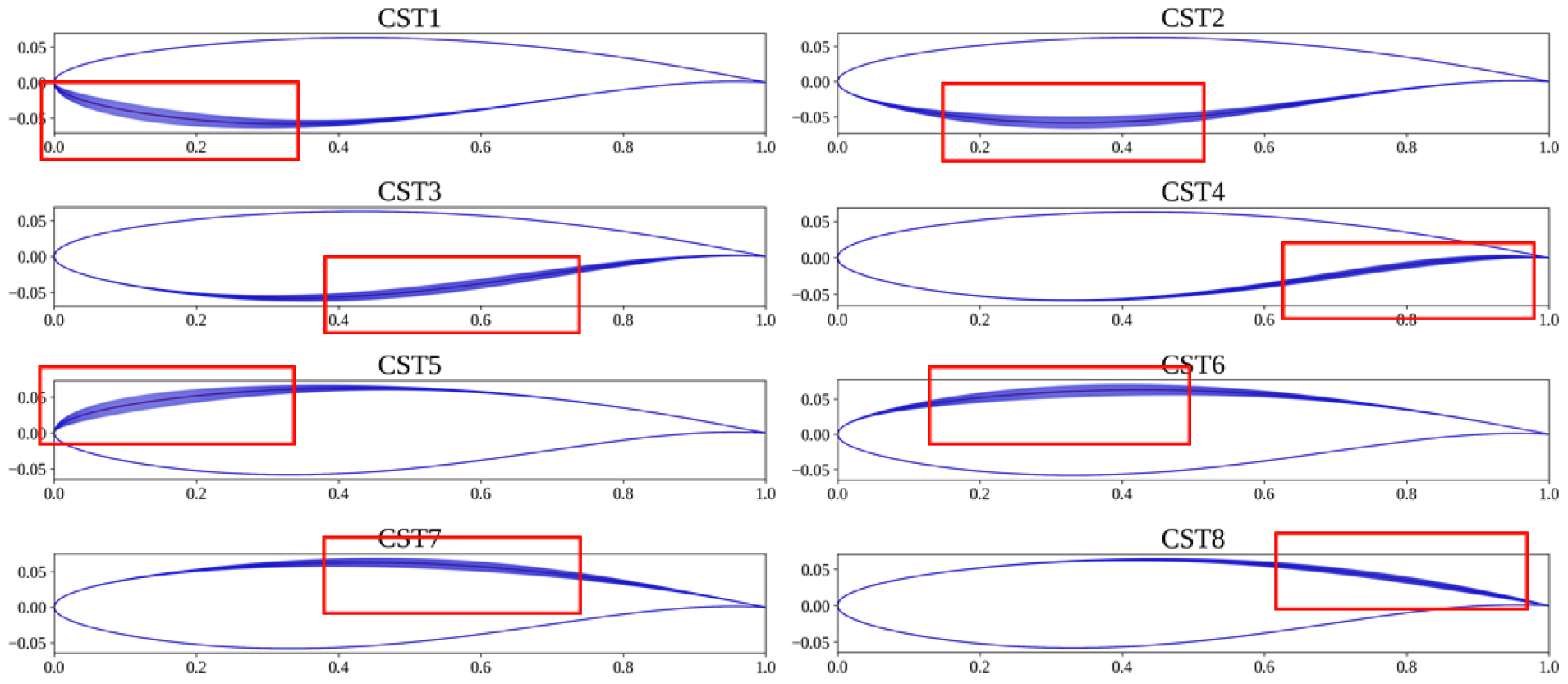
각 형상 변수의 범위는 RAE2822 기준 익형으로부터 ±0.05로 설정하였고, 해당 범위 내에서 Latin hypercube sampling을 통해 총 5,000개의 익형 샘플을 획득하였다. Fig. 4는 이렇게 얻어진 익형 데이터셋을 시각화하여 나타낸 것으로, 빨간색 선은 기준 익형 RAE2822에 해당한다. 이후 유동해석을 진행하여 각 익형의 충격파 발생 여부를 판별하고, 이를 기반으로 CE를 적용하기 위한 데이터베이스를 구축했다.

3.2 유동 해석
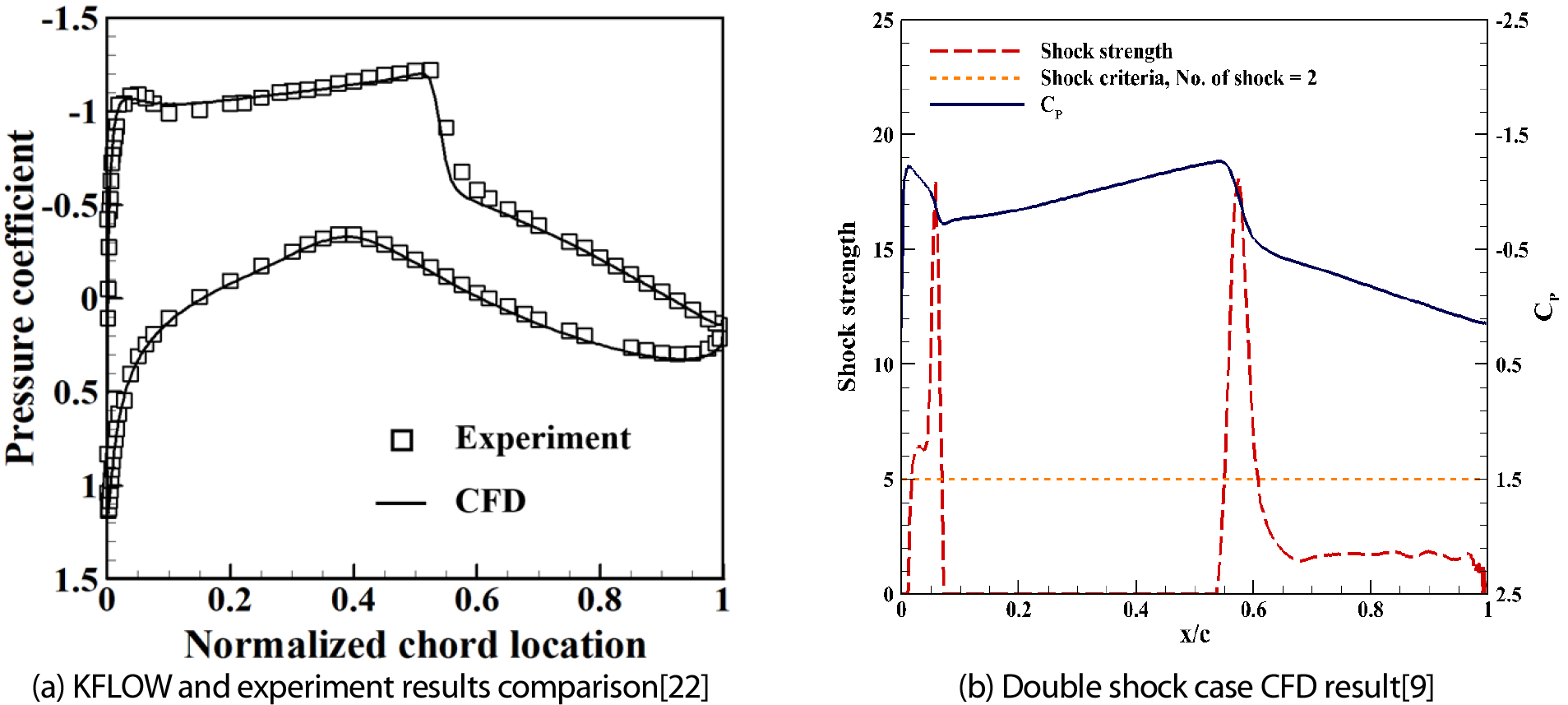
CST 매개변수화 방법을 통해 생성된 5,000개의 익형 샘플에 대해 천음속 유동장을 계산하였다. 해석 조건은 RAE2822 익형의 표준 천음속 실험 조건(Ma = 0.729, Re = 6.2 × 106, AoA = 2.31°)을 따랐으며, 이는 충격파가 명확하게 형성되는 조건으로 알려져 있다. 수치해석에는 RANS 기반 KFLOW[19,20] 솔버를 사용하였으며, AUSMPW+ 기법과 eMLP-VC[19] 제한자를 조합하여 충격파 포착 정확도를 확보하였다. 격자는 O-grid 형태로 구성하였으며(코드 방향 601개, 수직 방향 115개), 벽면 최초 격자 간격을 1.0×10-6로 설정하여 경계층 내 유동을 정밀하게 모사하였다. 완전 난류 조건을 가정하여 Spalart-Allmaras noft2 난류 모델[21]을 적용하였으며, CFL 수 4로 50,000회 반복 계산을 수행하여 정상상태 수렴을 확인하였다. Fig. 5(a)는 RAE2822 기준 익형에 대한 KFLOW 해석 결과와 실험 데이터의 비교를 보여준다. 표면 압력 분포가 실험값과 잘 일치하며, 특히 충격파 위치와 강도가 정확히 예측되어 본 해석 기법의 신뢰성을 확인하였다. 충격파 발생 여부를 판별하기 위해 표면 압력 구배 기반의 shock strength를 도입하였으며, 다음 식 (12)으로 표현된다.
이 지표는 충격파 전후의 급격한 압력 변화를 포착하며, 영역에서 계산하여 뒷전 근처의 기하학적 압력 변화를 배제하였다. Shock strength 값이 5 이상인 경우 충격파로 판정하였으며, 이 기준은 약한 압력 교란과 실제 충격파를 구분하기 위해 설정되었다. 5,000개 샘플 전체에 일관된 기준을 적용함으로써 상대적 비교가 가능하도록 하였다. 해석 결과, 1,337개 익형에서 이중 충격파가, 3,657개에서 단일 충격파가 관찰되었으며, 6개 익형은 충격파가 발생하지 않았다. 이중 충격파 압력 데이터 및 shock strength에 대한 적용 예시는 Fig. 5(b)와 같다.
4. 모델, 학습 방법 및 평가 방법
4.1 모델링 및 학습방법 선정
본 연구의 목적은 CFD 해석 결과를 직접 이용하지 않고, 학습된 대리 모델을 통해 빠르게 CF를 탐색하는 것이다. 이를 위해 충격파 패턴을 예측하는 대리 모델을 학습하고, 이를 기반으로 다양한 CE를 적용하여 설계 대안을 도출하였다.
4.1.1 대리 모델 구조 및 선정
CF를 생성을 위해 입력 변화에 따른 예측 변화를 평가할 수 있는 대리 모델이 필요하다. 본 연구에서는 익형의 형상을 정의하는 8개 CST 파라미터를 입력으로 하고 단일 충격파가 존재하는 경우에는 0, 이중 충격파가 존재하는 경우에는 1을 출력으로 하는 MLP 기반 이진 분류 모델을 구축하였다. 충격파가 발생하지 않은 6개를 제외한 4,994개 데이터를 학습에 사용하였다. 최적의 대리 모델을 선정하기 위해 배치 크기, 은닉층의 개수, 그리고 은닉 노드 수를 다양하게 조합한 12개의 MLP 모델을 구성하였다. 모든 모델은 Table 2에 제시된 동일한 하이퍼파라미터를 적용하였으며, 공정한 성능 비교를 위해 동일한 random seed를 사용하여 초기화 조건을 통제하였다.
Table 2.
Hyperparameters of the surrogate models
Table 3은 각 모델의 구체적인 구조와 성능을 나타낸다. 각 모델을 10회 반복 학습하여 테스트 정확도와 F1 score의 평균값을 산출한 결과, MLP-9 모델이 각각 0.9799와 0.9629로 가장 우수한 성능을 보여 최종 대리 모델로 선정하였다.
Table 3.
Architecture configurations and performance of MLP model candidates
4.1.2 반사실적 설명 생성 조건 및 대상 선정
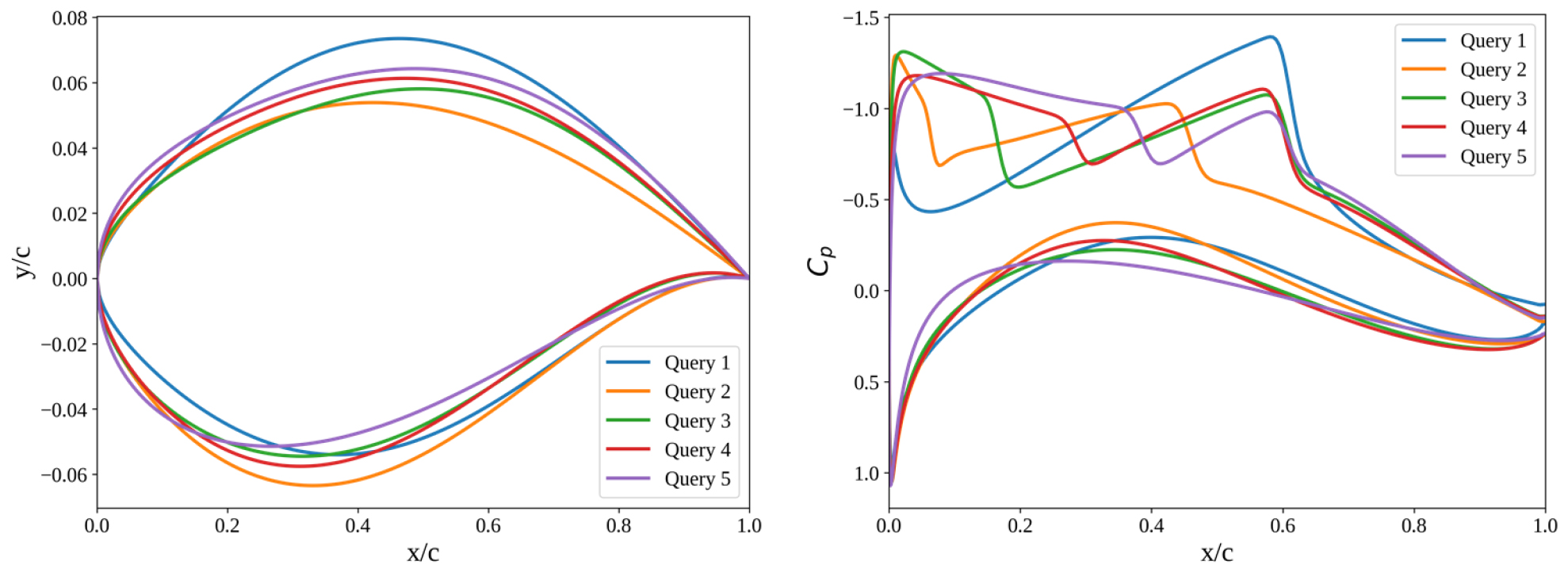
CF를 생성하기 위해서는, 대리 모델의 예측을 기반으로 기준 쿼리를 선정하고, 예측 결과가 변경되도록 입력 특성을 조정해야 한다. 충격파 위치에 따른 설계 변경 효과를 확인하기 위해, Fig. 6과 같이 이중 충격파가 존재하면서 첫 번째 충격파의 발생 위치()가 서로 다른 다섯 개의 익형을 쿼리로 선정하였다. 각 쿼리 익형에 대해 네 가지 CF 생성 방법을 적용하여 쿼리당 다섯 개의 CF 설계안을 생성하였으며 모든 CF는 대리 모델 상에서 단일 충격파로 분류되도록 하였다. 생성된 CF들은 CFD 해석을 통해 검증하여 실제 충격파 패턴 변화를 검증하였다.
4.2 평가 지표
생성된 CF는 단순히 예측 결과를 반전시키는 것뿐 아니라, 물리적으로 타당하고 실제 설계에 활용 가능해야 한다. 좋은 CF란 목표 클래스를 달성하면서도(유효성), 원본 설계에서 크게 벗어나지 않고(근접성), 최소한의 설계변수만 변경하며(희소성), 서로 다양한 대안을 제시해야 한다(다양성). 근접성이 낮은 CF는 원본 설계와 너무 달라 암묵적 설계 제약을 위반할 가능성이 높고, 희소성이 낮은 CF는 지나치게 많은 설계변수를 동시에 변경하여 어떤 변수가 핵심적인 역할을 하는지 파악하기 어렵게 만든다. 근접성이 변경의 크기를 측정한다면, 희소성은 변경된 설계변수의 개수를 측정한다는 점에서 두 지표는 상호 보완적이다. 한편 다양성은 근접성과 trade-off 관계에 있는데, 원본 설계에서 멀리 벗어날수록 CF들이 다양해질 가능성이 높아지지만 그만큼 현실성이 낮아질 수 있다. 따라서 어느 한 지표만으로는 CF의 품질을 충분히 평가할 수 없으며, 네 가지 지표를 종합적으로 고려하는 것이 필요하다.
4.2.1 유효성(Validity)
유효성은 생성된 CF가 목표 클래스로 분류되는지를 나타내며, 1에 가까울수록 더 많은 CF가 목표 클래스를 달성함을 의미한다. 수식은 다음과 같이 정의된다.
여기서 f(·)은 대리 모델의 예측 함수, 는 원본 쿼리 익형, 는 생성된 i번째 CF, k는 생성된 CF의 개수이며 I[·]는 조건이 참이면 1을 반환하는 지시 함수이다. 본 연구에서는 생성된 익형 중에서 모델이 충격파 개수가 감소한 것으로 예측한 비율로 유효성을 평가하였다.
4.2.2 근접성(Proximity)
근접성은 CF와 원본 설계 간 유사도를 나타내며, 일반적으로 CF와 원본 입력 간의 평균 거리로 정의되며, 값이 클수록 CF가 원본 설계에 가깝다는 것을 의미한다. 근접성이 낮은 CF는 원본 설계로부터 크게 벗어나 제조 가능성이나 기존 시스템과의 호환성 등 암묵적 설계 제약을 위반할 가능성이 높다. 수식으로 나타내면 다음과 같다.
여기서 k는 생성된 CF의 개수이고, dist(·, ·)는 식 (4)에서 정의한 MAD 정규화 맨해튼 거리이다.
4.2.3 희소성(Sparsity)
희소성은 원본 설계 대비 변경된 설계변수의 비율이 얼마나 적은지를 나타낸다. 희소성이 1에 가까울수록 일부 설계변수만 변경되어 설계자가 어떤 변수가 충격파 발생에 핵심적인 역할을 하는지 명확히 파악할 수 있으며, 0에 가까울수록 거의 모든 설계변수가 변경되어 해석 가능성이 낮아진다. 수식은 다음과 같이 정의된다.
4.2.4 다양성(Diversity)
다양성은 CF들이 서로 다른 설계 대안을 제시하는 정도를 나타내며, 다양성이 높을수록 설계자는 더 넓은 설계 공간을 탐색할 수 있다. 다양성을 다각적으로 평가하기 위해 두 가지 지표를 사용하였다. 식 (16)은 거리 기반(distance-based) 다양성으로 모든 CF 쌍의 평균 유클리드 거리로 계산되며, 식 (17)은 특징 기반(feature-wise) 다양성으로 각 CF 쌍 간 변경된 feature 개수를 기준으로 계산된다. Distance-based diversity가 높을수록 CF들 간의 형상 값의 변화 폭이 넓고, feature-wise diversity가 높을수록 CF들이 서로 다른 설계변수 조합을 변경하여 다양한 설계 전략을 제시함을 의미한다.
5. 결과 및 분석
5.1 반사실적 설명 생성 결과
본 절에서는 다섯 개 쿼리 중 첫 번째 충격파가 익형 중간 영역()에서 발생하는 Fig. 6의 Query3을 대표 사례로 선정하여 상세히 분석한다. Query3은 극단적이지 않은 일반적인 충격파 발생 조건을 대표하며, 네 가지 CF 생성 방법의 특성을 비교하기에 적합하다. Fig. 7은 Query3으로부터 각 방법론 별로 생성된 5개 CF 형상과 압력 계수 분포를 보여준다.
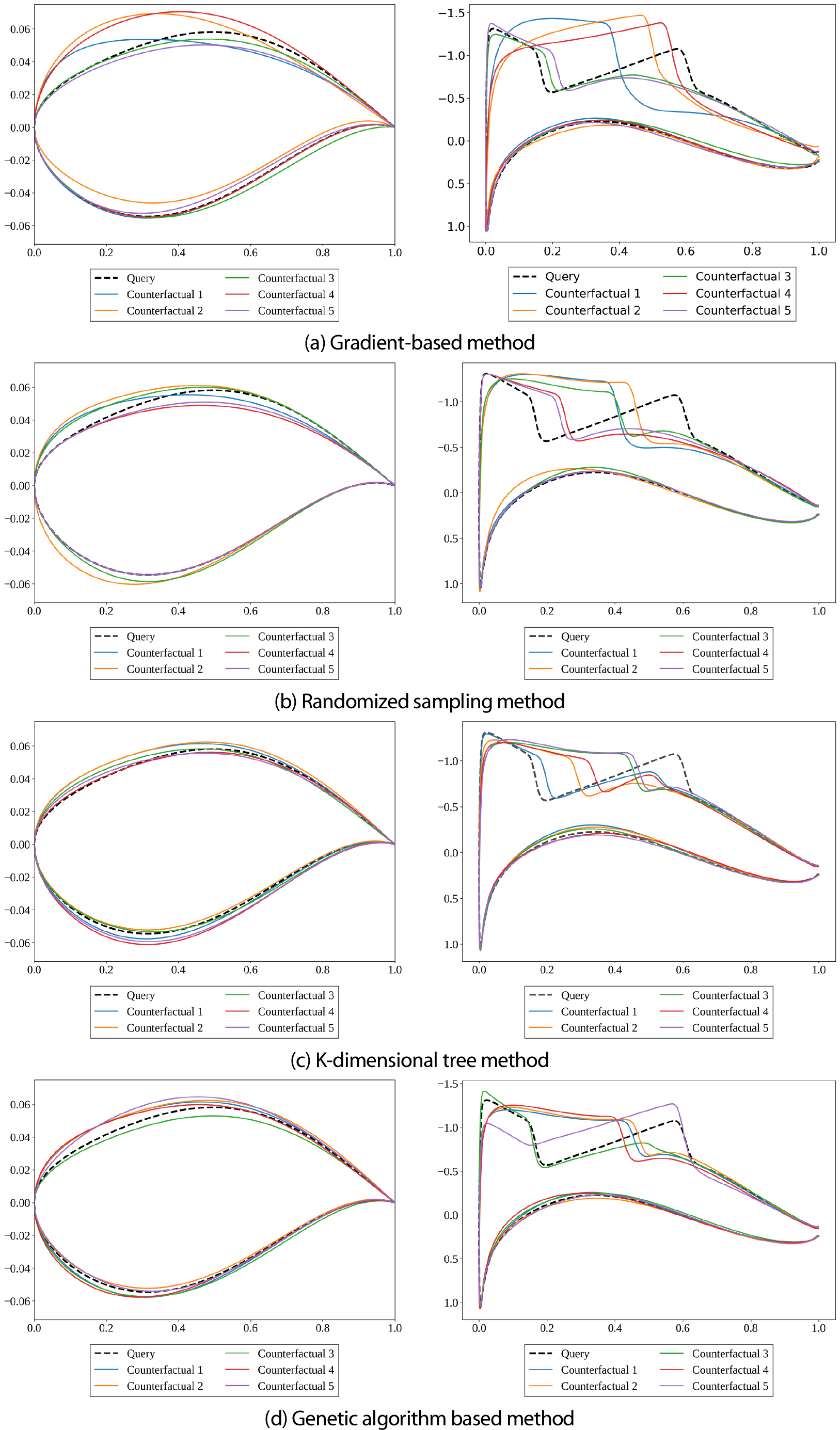
Gradient 방법(Fig. 7a)은 에어포일 윗면을 크게 변형시키며 충격파 위치가 전방부터 후방까지 광범위하게 분포하는 다양한 익형을 생성하였으나, shock strength는 여전히 상당한 크기를 유지했다. Random(Fig. 7b)과 KD tree 방법(Fig. 7c)은 모두 기존 형상과 유사한 익형을 생성하며 충격파 위치를 윗면 후방으로 순차적으로 이동시켰고, KD tree 방법이 Random 방법보다 더 작은 shock strength를 나타냈다. GA 방법(Fig. 7d)은 기존 형상과 유사하면서도 충격파 위치가 전방, 후방, trailing edge 등 다양하게 분포하는 CF들을 생성했다. 이에 대한 정량적 평가와 물리적 분석은 다음 절에서 상세히 다룬다.
5.2 정량적 평가 및 방법론 특성 분석
본 절에서는 다섯 개 쿼리에서 생성된 모든 CF들을 대상으로 4.2절의 평가 지표와 CST 파라미터 변경 패턴을 분석하여 각 방법의 특성을 비교한다. Table 4는 각 방법의 평균과 표준편차를 정리한 결과이다.
Table 4.
Quantitative comparison of counterfactual explanation methods
Fig. 8은 각 CST 파라미터가 원본 쿼리 대비 CF에서 얼마나 변경되었는지를 방법별로 나타낸 것이다. Normalized feature importance는 각 CST 파라미터가 원본 쿼리 대비 CE에서 얼마나 변경되었는지를 정량화한 지표로, 다음과 같이 계산된다.
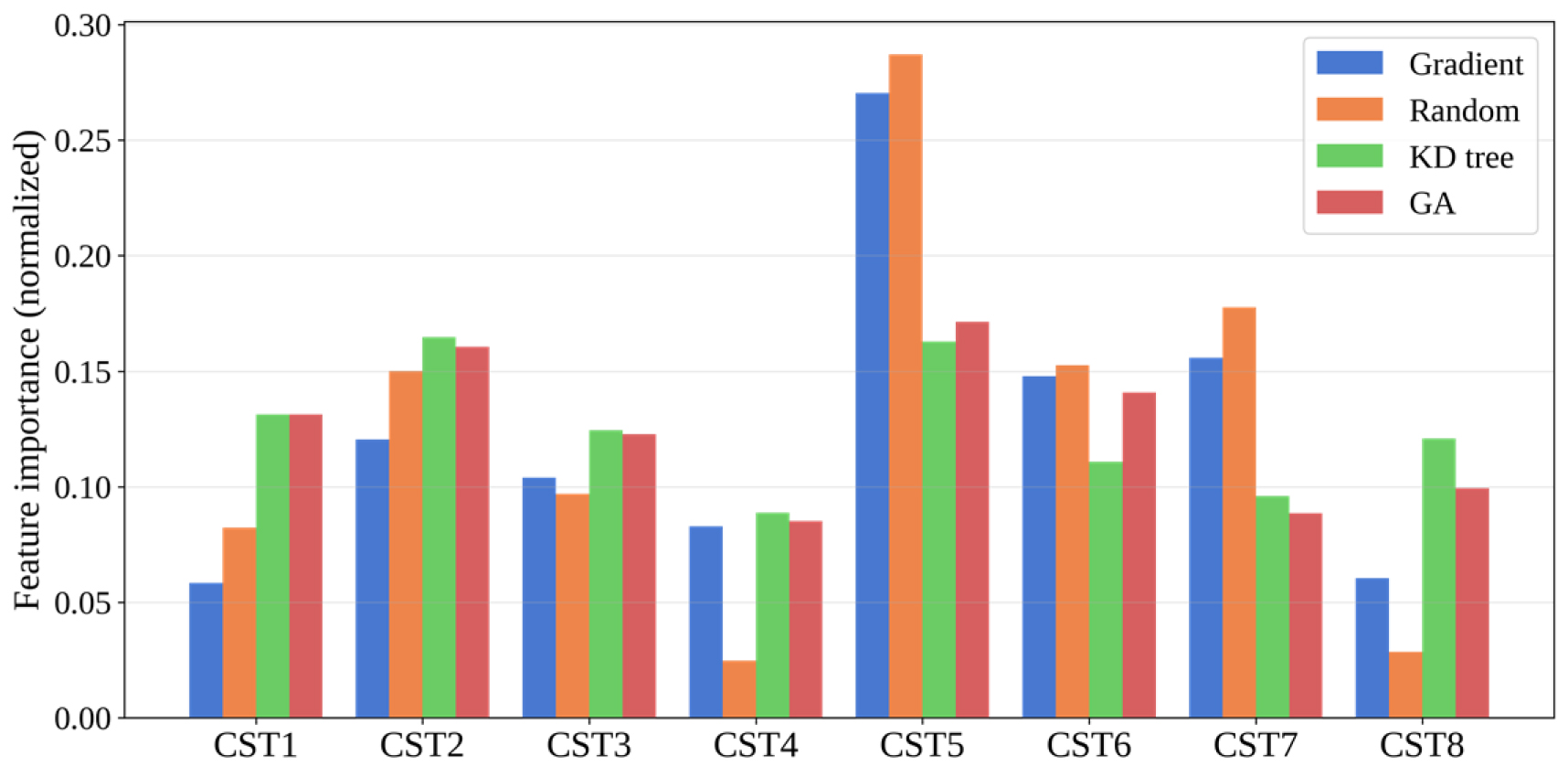
여기서 n은 쿼리 수, m은 각 쿼리 당 생성된 CF 개수, 와 는 각각 원본과 CF의 f번째 CST 파라미터 값을 의미한다.
Gradient 방법은 손실함수를 통해 목표 클래스 확률 최대화, 근접성 최대화, 다양성 최대화를 단일 함수로 동시에 최적화한다. 이 과정에서 결정 경계의 기울기가 가장 큰 방향으로 수렴하므로 충격파 발생에 가장 민감한 CST5(0.270), CST7(0.156), CST6(0.148) 순으로 윗면 파라미터에 집중된 변경이 나타났다. 손실함수 내 다양성 가중치(1.0)가 근접성 가중치(0.5)보다 높게 설정되어 CF들이 서로 멀리 떨어진 방향으로 분산되면서 원본 설계로부터도 멀어지는 경향이 나타나 근접성이 가장 낮고 거리 기반 다양성이 가장 높았으며, Fig. 9(b)와 Fig. 9(c)에서 원본 대비 큰 형상 변화와 CF 간 높은 다양성을 확인할 수 있다. 그러나 여러 항을 단일 손실함수로 동시에 최적화하는 과정에서 각 항 간의 trade-off로 인해 CF가 클래스 경계 근방에 위치하는 경우가 발생할 수 있으며, 경계 근방에서 대리 모델이 실제 CFD 물리를 충분히 모사하지 못할 경우 CFD 유효성 저하로 이어질 수 있다. 실제로 본 연구에서 CFD로 검증한 유효성이 0.960으로 다소 저하되었다.
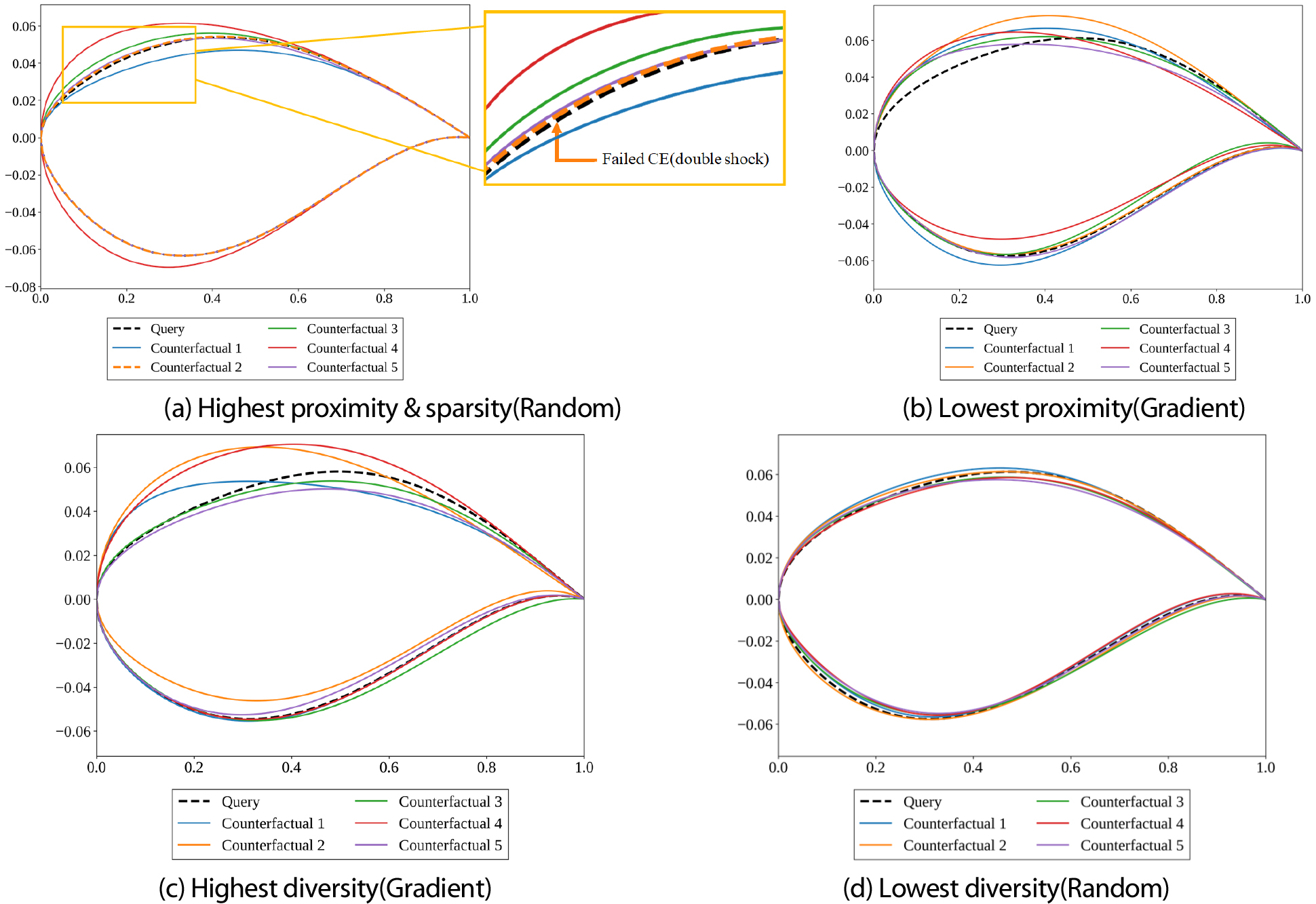
Random 방법은 손실함수 최적화 없이 파라미터를 하나씩 순차적으로 추가 변경하며 대리 모델의 분류 결과를 확인하는 방식으로 탐색한다. 소수의 파라미터 변경만으로 클래스 전환이 가능한 경우 조기에 탐색을 종료하므로 충격파에 민감한 CST5(0.287), CST7(0.178), CST6(0.153) 순의 윗면 집중 패턴과 높은 희소성이 나타났으며, 최소한의 형상 변경으로 근접성이 가장 높았다. Fig. 9(a)는 원본과 유사한 형상을 유지하는 반면 Fig. 9(b)의 Gradient 결과와 대조를 이루며, Fig. 9(d)에서 CF 간 유사한 형상으로 낮은 다양성을 확인할 수 있다. 목표 클래스로 분류되는 즉시 탐색을 종료하는 구조상 CF가 클래스 경계 근방에 위치하기 쉬워 CFD 유효성이 가장 낮았으며, Fig. 9(a)에서 주황색 점선(Counterfactual 2)은 CFD 검증 결과 이중충격파가 발생하여 충격파 저감 목표를 달성하지 못한 경우를 보여준다.
KD tree 방법은 LHS 샘플링 기반 데이터베이스에서 원본과 가장 가까운 포인트를 거리 및 희소성 기준으로 탐색한다. 대리 모델이 단일 충격파로 분류한 데이터베이스 포인트를 대상으로 탐색하므로 CST2(0.165), CST5(0.163) 순으로 윗면과 아랫면 파라미터가 고르게 변경되었다. CFD 유효성이 1.000을 유지하였으며, 변경되는 파라미터 조합이 CF마다 달라져 특징 기반 다양성이 가장 높았다.
GA 방법은 적합도 함수를 통해 목표 클래스 확률과 근접성을 평가하며 교배와 돌연변이를 통한 전역 탐색으로 다양한 파라미터 조합을 시도한다. CST5(0.171), CST2(0.160), CST6(0.141) 순으로 윗면과 아랫면 파라미터가 고르게 변경되었으며, CFD 유효성이 1.000을 달성하였다. 유효성, 근접성, 다양성 측면에서 전반적으로 균형 잡힌 성능을 보였다.
5.3 물리적 분석
본 절에서는 CST 파라미터 변화가 에어포일 형상에 미치는 영향과 그로 인한 충격파 형성 메커니즘을 분석한다. 천음속 조건에서 충격파는 주로 에어포일 윗면에서 발생한다. 윗면 형상이 볼록할수록 유동이 강하게 가속되어 국소 초음속 영역이 형성되고, 이 영역이 종료되는 지점에서 충격파가 발생한다. Fig. 7의 CF들에서 공통적으로 관찰된 경향을 보면, 윗면 전방부가 볼록하되 곡률이 완만한 형상에서는 유동이 서서히 가속되어 초음속 구간이 중후방에서 형성되므로 충격파가 후방에서 발생하고 shock strength가 상대적으로 약하게 나타났다. 반면 윗면 전방부가 볼록하면서 곡률이 급격한 형상에서는 유동이 앞전 근방에서 급격히 가속된 후 바로 충격파가 형성되므로 충격파가 전방에서 발생하고 shock strength도 강하게 나타났다. 이는 윗면 전방부의 곡률 크기가 충격파 발생 위치와 강도를 동시에 결정하는 핵심 인자임을 시사하며, 5.2절에서 모든 방법에 걸쳐 CST5, CST6, CST7의 변경 빈도가 높게 나타난 결과와 일치한다. CST5의 변경 빈도가 가장 높게 나타난 것은 예측 가능한 결과이나, Normalized feature importance 분석을 통해 이들 파라미터 간의 상대적 중요도를 정량적으로 확인할 수 있다는 점에서 의미를 가진다. 반면 전체적으로 후방부를 제어하는 CST4와 CST8은 모든 방법에서 낮은 변경 빈도를 보여 충격파 제어에 미치는 영향이 제한적임을 확인할 수 있었다.
이러한 분석 결과를 종합하면 CF 생성 방법의 선택은 설계 목적과 요구되는 예측 신뢰성 수준에 따라 달라져야 함을 시사한다. 충격파 저감에 결정적인 파라미터를 간결하게 식별하고자 할 경우에는 희소성이 높은 Random 방법이, 형상 변화의 폭이 넓은 다양한 대안을 탐색하고자 할 경우에는 Gradient 방법이 적합하다. 다만 두 방법은 클래스 전환이 달성되는 시점에서 탐색을 종료하는 특성상 CF가 경계 근방에 위치할 가능성이 있어 예측 신뢰성 측면에서 불리할 수 있으며, 신뢰성이 중요한 상황에서는 본 연구에서 CFD 유효성 1.000을 달성한 KD tree 또는 GA 방법이 유리한 선택이 될 수 있다. 나아가 네 가지 방법 모두 대리 모델만으로 CF를 생성한 후 유망한 후보에 대해서만 CFD 검증을 수행하는 순차적 설계 워크플로우에 활용할 수 있으며, 이는 고비용 CFD 시뮬레이션의 수행 횟수를 줄이면서 효율적인 설계 탐색을 가능하게 한다.
6. 결 론
본 연구에서는 CE를 공학적 설계 문제, 특히 익형 형상 설계에 적용하였다. CE를 통해 모델의 예측을 변화시키는 핵심 요인을 식별하고, 이를 바탕으로 실행 가능한 설계 개선 방향을 생성하였다. 생성된 CF를 분석한 결과 익형 윗면의 전반부와 중반부를 조정하는 CST 파라미터가 주로 변경되었으며, 이는 익형의 전·중반부 곡면 특징이 충격파에 민감하게 영향을 미친다는 기존 공기역학적 배경지식과 일치하였다. 이 논문의 기여는 다음과 같다. 첫째, CE를 천음속 익형 설계 문제에 최초로 적용하여, 블랙박스 모델의 해석가능성을 향상시키고 설계자에게 구체적인 형상 개선 방향을 제시하였다. 둘째, 베이스라인 설계로부터의 최소 변경을 추구하는 CE의 특성을 활용하여, 기존 설계 최적화에서 고려하기 어려웠던 암묵적 제약 조건을 반영한 점진적 설계 개선 방법론을 제안하였다. 그러나 본 연구는 충격파 저감에만 초점을 두었으며 양력, 항력, 두께 등 실제 비행 성능과 관련된 공력 특성을 목적함수에 포함하지 않았다. 또한 충격파 발생 여부를 이진 분류로 정의함에 따라 동일 클래스 내에서의 충격파 강도 차이를 구분하지 못하는 한계가 있으며, 대리 모델을 충격파 강도와 같은 연속값 예측 모델로 확장한다면 보다 정밀한 설계 지침을 도출할 수 있을 것이다. 향후 연구에서는 이러한 제약 조건을 통합한 다목적 최적화 프레임워크로 발전시키는 연구를 수행할 예정이다.
