

1. 서 론
우주 왕복선의 지구 귀환이나 화성 탐사선의 착륙 등 여러 미션에서 비행체는 행성 대기로의 재진입 단계를 거친다. 이 과정에서 비행체는 극초음속 유동 환경에 노출되어 충격파, 마찰 및 대기 분자의 화학 반응에 의해 극한의 공력 가열을 경험하게 된다. 이러한 공력 가열은 비행체 구조에 심각한 손상을 초래할 수 있으므로, 성공적인 미션 수행을 위해서는 설계 단계에서 공력, 열적 특성, 궤적, 구조적 성능 등을 다분야 관점에서 분석하고, 다목적 최적화 과정을 통해 최적의 설계를 도출하는 것이 필수적이다[1,2,3,4,5].
전산유체역학(Computational fluid dynamics, CFD) 기반의 비행체 열공력 특성 해석은 다른 방법보다 높은 정확도와 세밀한 데이터를 제공하지만, 분석에 많은 계산 자원과 긴 시간이 소요된다. 개념 설계 단계에서는 다양한 형상과 비행 환경에 대해 열공력 특성을 반복적으로 분석해야 하므로, CFD의 높은 계산 비용이 활용에 제약이 된다. 특히 유전알고리즘과 같은 전역 탐색 최적화 기법을 사용할 경우 수많은 설계안에 대한 평가가 요구되므로 CFD는 더욱 그 활용성이 제한된다. 이를 위해 경험식 기반의 열공력 모델이나, 열공력 데이터를 학습한 대리 모델(surrogate model)로 대체하는 기법을 적용할 수 있다. 대리 모델인 크리깅 모델, 딥러닝 모델 등은 적절한 정확도를 유지하면서도 CFD 대비 계산 속도가 매우 향상되며, 특히 전역 최적화 알고리즘과 결합 시 설계 탐색의 효율을 비약적으로 높일 수 있다.
이러한 효율성 때문에 많은 연구에서 대리 모델 기반의 최적화 기법을 활용하고 있다. Liu 등[6]은 크리깅 모델을 이용하여 극초음속 비행체 날개 형상의 다목적 설계 최적화(Multi-objective Design Optimization)를 수행하였다. 본 논문에서는 극초음속, 천음속 조건에서 비행체 날개의 양항비를 최대화하기 위하여 라틴 하이퍼큐브 샘플링(LHS)을 통해 설계 공간에서 샘플을 추출하고, RANS 해석을 통해 양항비를 계산하여 크리깅 모델을 구성하였다. 이에 유전 알고리즘과 그래디언트 기반 방법이 혼합된 알고리즘을 적용하여 최적점을 탐색하였다. Ma 등[7]은 크리깅 모델을 이용하여 재진입 powered 비행체의 형상의 다학제간 설계 최적화(Multidisciplinary Design Optimization)를 수행하였다. 비행체의 항속거리를 최대화하기 위하여, 형상, 공력, 질량, 추진, 궤적 및 열 보호 시스템(TPS) 모듈을 통합하여 크리깅 모델을 구성하고 그래디언트 기반 알고리즘을 통해 형상을 최적화하였다.
궤적 최적화에서도 대리 모델 기반의 최적화 기법이 많이 사용되고 있다. Shi 등[8]은 딥러닝 모델을 이용하여 극초음속 비행체의 실시간 궤적 최적화를 수행하였다. 비행체의 위치, 속도 등이 포함된 비행 상태 벡터 샘플을 입력으로 하여 최종 속도를 최대화하는 최적 제어 문제에서 최적 받음각을 계산함으로써 훈련 데이터셋을 생성하고, 해당 데이터셋으로 Multi-layer perceptron(MLP) 모델을 훈련하여 대리 모델로 사용하였다. He 등[9]은 여러 대리모델을 이용하여 우주발사체 임무의 전체 궤적 최적화를 수행하였다. 발사, 임무, 재진입에 걸친 전체 궤적에 대한 동역학 모델을 크리깅 모델로 대체하였으며 유전 알고리즘을 통해 총 소요 시간 및 필요 추진량을 최소화, 페이로드 질량을 최대화하였다.
또한, Mohammadi-Amin 등[10]은 최적화 과정에 활용할 수 있도록 대리모델 기반의 재진입 비행체 공력 데이터베이스 생성 프레임워크를 제안하였다. 해당 프레임워크에서는 라틴 하이퍼큐브 샘플링과 CFD 해석, 크리깅 보간을 통해 데이터베이스를 생성하며, CFD 계산 비용을 절감하기 위하여 저충실도 해석 결과와 고충실도 해석 결과를 병용한 코크리깅(co-kriging) 모델을 사용하였다. 제안된 프레임워크는 Apollo-derived Orion 재진입 비행체에 대하여 검증되었다.
본 연구에서는 경험식 기반의 열공력 해석 프로그램을 활용하여 극초음속 비행체의 공력 및 열 환경을 신속하게 평가할 수 있는 분석 기법을 개발하고, 이를 기반으로 크리깅 및 딥러닝 기법을 적용한 대리 모델을 구축함으로써 설계 효율성을 극대화하는 것을 목표로 한다. 대리 모델은 실험적 또는 수치 해석적 방법을 통해 축적된 데이터를 학습하여 설계 변수와 성능 지표 간의 복잡한 관계를 효과적으로 모델링할 수 있는 기법으로, 본 연구에서는 크리깅 모델과 딥러닝 모델을 각각 구현하여 예측 정확도와 계산 비용, 활용성을 종합적으로 비교 분석한다.
대리 모델 생성을 위한 학습 데이터는 반경험적 열모델식을 이용한 신속 열공력 해석 프로그램을 통해 생성되며, 이를 통해 극초음속 비행 환경에서의 열적 및 공력적 응답을 보다 효율적으로 평가할 수 있다. 특히, CFD 해석의 높은 연산 비용과 긴 계산 시간을 고려할 때, 본 연구에서는 신속 열공력 해석 프로그램을 활용하여 전역 최적화 과정에서 발생하는 계산 부담을 줄이고, 보다 실용적인 최적 설계 접근법을 제시하고자 한다. 이러한 대리 모델을 설계 탐색 과정에 적용하기 위해, 유전 알고리즘(Genetic Algorithm, GA) 기반의 최적화 기법과 결합하여 신뢰성 높은 설계 후보를 도출하는 방법론을 제안한다.
2. 연구 방법
2.1 설계 문제 정의
2.1.1 형상 설계 변수
본 연구에서는 최적 설계의 기본 형상으로 blunt nose-cone-flare 형상을 선정하였다. 본 형상은 구조가 단순하여 제작이 용이하며, 제어가 필요하지 않은 무인 탄도 재진입 임무에 적합한 공기역학적 안정성을 제공한다[11]. 다양한 blunt nose-cone-flare 모듈이 개발되었으며 성공적인 비행 실험과 다양한 분석 연구[12,13,15]를 통해 본 형상의 우수성이 입증된 바 있다.
기본 형상은 반구형 노즈, 원뿔형 본체, 플레어로 구분할 수 있으며 각 파트별 설계 변수는 Fig. 1과 같이 노즈의 곡률 반경(), 축 방향 콘형 몸통 부분의 길이(), 플레어 부분의 길이(), 콘형 몸체의 반각(), 및 플레어의 각도()로 정의할 수 있다. 기본 형상의 설계 변수 값은 ISRO의 SRE 캡슐[12] 크기를 사용하였으며 Table 1에 제시되어 있다.
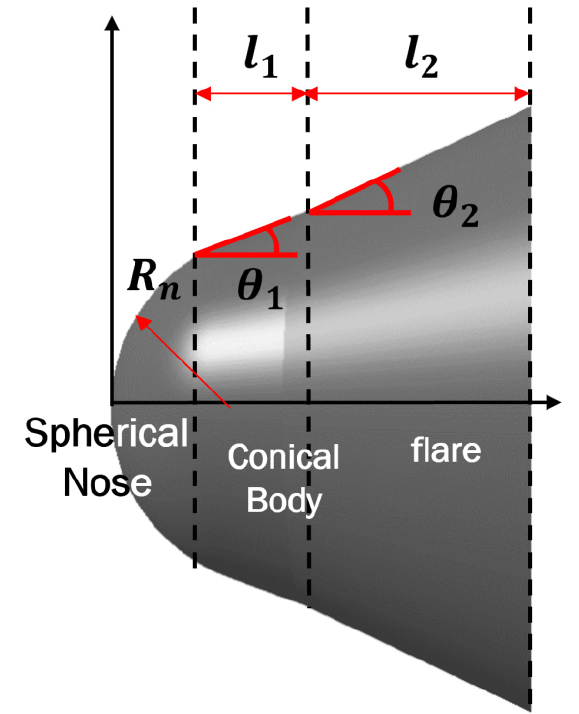
2.1.2 목적함수 및 제약조건
성공적인 임무수행을 위해 형상 설계에서는 다음과 같은 세가지 최적화 목적함수를 고려하였다. 캡슐의 체적 효율()은 비행체의 면적과 부피를 기반으로 표현되며, 다음과 같은 식으로 나타낼 수 있다.
캡슐의 체적 효율은 발사체의 공간 활용 효율성 및 페어링 공간에 크게 영향을 미치며, 이는 발사 비용 절감으로 이어진다. 구에서 체적 효율 값은 1로 최대를 가지며, 형상이 길고 얇아질수록 효율은 감소한다.
두 번째로 재진입 임무 중 캡슐에 가해지는 총 흡수 열량을 고려한다. 캡슐이 흡수하는 누적 열량을 최소화 하는 것은 캡슐 표면의 열 보호막(heat shield)의 성능 최적화 및 경량화를 위한 핵심 요소이다. 캡슐의 총 흡수 열량은 표면적과 열전달률(heat transfer rate)에 대해 식 (2)로 정의된다.
세 번째로 캡슐의 탄도 계수 최소화를 목적함수로 선정하였다. 탄도 계수는 비행체의 공력 효율성을 설명하는 계수로, 재진입 시 높은 항력을 얻고 구조적 하중을 감소시켜 안정적인 재진입을 가능하게 하기 위해서는 캡슐의 탄도계수를 최소화 하여 안전성과 효율성을 최적화 해야한다[16]. 비행체의 탄도계수는 질량을 면적과 항력 계수의 곱으로 나눈 값으로 표현되며 식 (3)과 같이 정의된다.
형상 설계 변수의 제약 조건은 캡슐이 탑재되는 발사체 상단의 내부 면적으로부터 고려된다. 본 연구에서는 기본 형상인 SRE 캡슐이 탑재되었던 PSLV-C7[17] 발사체 상단부의 재원을 고려하였으며, 이로부터 도출된 형상 설계변수의 제약 조건을 Table 2에 제시하였다.
2.2 해석 프로그램
본 연구에서는 구조, 열, 공력, 궤적 등 다분야 해석 모듈로부터 생성된 데이터를 바탕으로 딥러닝 및 크리깅 모델을 학습시켜 최적화 과정에 적용한다. 이렇게 구축된 대리 모델은 최적화 과정에서 반복적으로 수행되는 고비용 해석을 대신함으로써 설계 탐색 속도와 계산 효율성을 동시에 높인다. 각 해석 모듈은 시험 데이터 기반의 반경험적 모델식 또는 해석적으로 도출된 상관 관계식을 활용하여 최적화 전반에서 계산 비용을 절감하도록 설계되었다.
먼저, 다섯 개의 설계 변수 값을 기반으로 구조 해석을 통해 무게를 추정한다. 이때 비행체의 면적, 부피와 열보호 시스템을 포함한 무게가 계산된다. 다음으로 공력 및 궤적 해석을 위한 자동 표면 격자 생성 단계가 수행된다. 구조 해석 시 산출된 질량 및 면적을 바탕으로 재진입 궤적 해석이 수행되며, 이 과정에서 탄도 계수가 계산된다. 마지막으로 재진입 중 비행체에 작용하는 총 흡수 열량이 계산된다. 각 모듈을 포함한 설계 프레임워크는 Fig. 2와 같이 구성된다. 2.2절에서는 최적화 프레임워크에서 사용된 개별 모듈과 그 역할에 대해 자세히 설명한다.
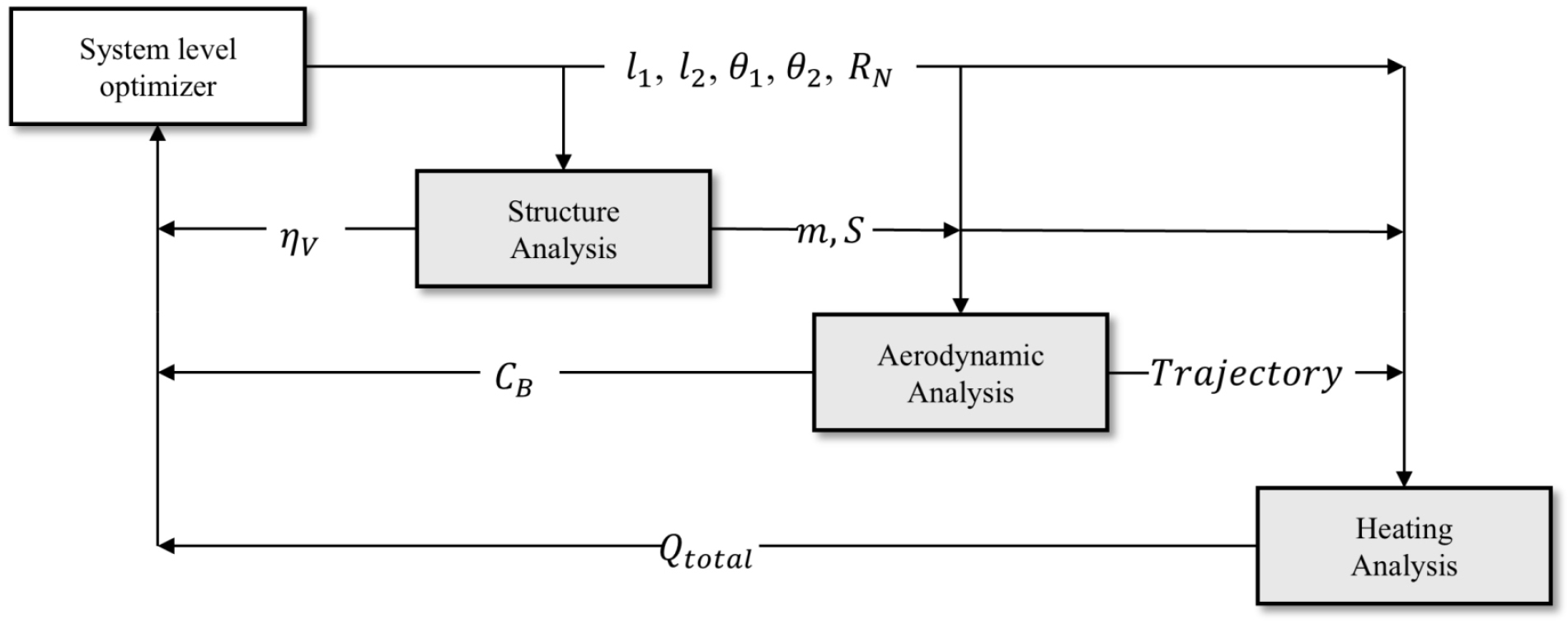
2.2.1 무게 추정 모듈
먼저, 형상 설계변수로부터 면적 및 부피 계산이 수행된다. 전체 표면적은 앞서 정의된 반구형 노즈, 콘형 몸체, 플레어의 면적의 합으로 표현되며 다음과 같이 나타낼 수 있다.
비행체의 질량은 구조체의 질량, 탑재 하중 질량, 그리고 열보호시스템의 질량의 합으로 정의된다. 대기 진입 임무 시 비행체의 노즈 부분은 최대 열 부하를 경험하는 반면, 선두부가 아닌 나머지 영역은 정체점 열전달량의 약 50%만수준의 열부하를 받는다. 이에 따라 비용 효율을 고려하여 노즈와 나머지 부분에 대해 서로 다른 TPS 재료가 적용되는 것이 일반적이다. 따라서 비행체의 총 질량은 다음과 같이 계산된다.
TPS의 질량을 추정하기 위해, 기본 형상인 SRE 캡슐에서 사용된 TPS 물성[18,19]을 참고하였다. 노즈 부분에는 Carbon-Phenolic 재료의 물성을 적용하였으며, 콘형 몸체 및 플레어 부분에는 Silica Tile을 사용하였다. 비행체의 구조 재료는 알루미늄 합금으로 가정하였다.
탑재 하중과 임무장비의 무게는 PSLV 임무에서 SRE 캡슐을 기준으로 설정된 탑재 하중[20] 및 일반적인 우주 미션 캡슐 설계에 적용되는 탑재 하중 밀도[21]를 참고하여 Table 3과 같이 설정하였다.
Table 3.
TPS information for weight prediction
| Part | Material | Density() | Thickness(mm) | |
| TPS for Blunt-nose | Carbon-phenolic | 1400 | 22 | |
| TPS for Other Body | Silica Tiles | 300 | 22 | |
| Structure | Aluminum Alloy | 2700 | 10 | |
| Payload | 50 kg | |||
2.2.2 공력 및 궤적 해석 모듈
비행체의 재진입 궤적 분석은 Survivability Analysis Program for Atmospheric Reentry(SAPAR) 프로그램[22,23]을 활용하였다. SAPAR 프로그램은 3자유도 운동 방정식을 기반으로 비행 궤적을 해석하며, 그림자가 형성되는 영역을 판별 후 비그림자 영역에 대해 Modified Newtonian method를 적용하여 압력 계수를 계산한다. 시간 적분에는 4차 Runge-Kutta 방법을 사용하였다. 재진입 궤적 분석을 위한 프로그램의 초기 입력 변수는 Table 4와 같다. 초기 경도와 위도는 목표 지점에 착륙하도록 trial and error 과정을 거쳐 결정하였다. 또한, 비행 안정성을 고려하여 받음각은 유동 방향과 정렬되도록 0°으로 설정하였다.
Table 4.
Entry initial condition
| Longitude | 140.5°E |
| Latitude | 3.5°N |
| Altitude | 120 km |
| Flight path angle | -1 deg |
탄도 계수는 식 (3)을 이용하여 궤적 전반에 걸쳐 계산할 수 있으며, 본 연구에서는 목적함수로 탄도 계수 최소화를 선정하였기 때문에, 하나의 형상 및 궤적에 대해 도출되는 최대 탄도 계수값을 대표값으로 설정하여 최적화 과정을 수행하였다.
2.2.3 열 해석 모듈
본 연구에서는 열공력 신속 해석 프로그램(Aero-Thermal Rapid Analysis Software, ATRAS)[24]을 이용하여 열 해석을 수행하였다. ATRAS는 공력, 열 해석을 위해 다양한 반 경험식 또는 상관식을 활용하여 비행체의 열공력을 예측하므로 해석 시간을 대폭 절감할 수 있다. 사용자는 원하는 해석 지점과, 해당 지점에서의 기하학적 정보(정체점으로부터의 거리, 곡률 반경, 후퇴각 등), 적용할 열모델 등을 선택하여 해당 지점에서의 열 정보를 빠르게 예측할 수 있다. 본 프로그램은 다양한 유동 조건 및 비행체 형상에 대해 재진입 유동 조건에 대해서 공력 및 열 해석의 정확성이 검증된 바 있으며[24], 이를 활용한 최적 설계 연구[25]에도 활용되었다. 열 해석을 위해 사용된 파트 별 공력 및 열 모델은 Table 5와 같다.
Table 5.
Summary of methods used in the heating analysis
각 파트에 대한 열전달량은 포인트 기반의 지점 별 열전달량으로 산출된다. 지점과 지점 사이마다의 대표면적()과 시간에 대해 적분된 열전달량을 곱하여 전체 면적에 대한 열 부하를 산출할 수 있다. 이때 노즈부에서의 지점별 대표면적()은 구면띠의 면적, 콘과 플레어에서의 지점 별 대표면적()은 원뿔대의 면적으로 계산할 수 있다. 이러한 계산을 재진입 궤적의 모든 지점에 대해 수행하여 비행 시간이 경과함에 따라 누적되는 총 흡수 열량값을 도출하였다.
2.3 기계학습을 통한 열해석 모델 생성
Fig. 3은 기계학습 기반 열해석 모델 생성 과정을 개략적으로 나타낸다. 먼저, 형상 설계 변수 공간에서 실험점을 생성하고, 각 실험점에 대해 2.2절의 다분야 해석 모듈을 통해 성능 지표 값을 계산한다. 생성된 데이터는 학습용 데이터셋으로 구성되며, 이를 기반으로 딥러닝 모델과 크리깅 모델이 각각 학습된다. 딥러닝 모델은 MLP(Multi-layer perceptron) 기반으로 각 목적 함수에 대해 개별적으로 학습한 후 통합 모델로 구성되며, 크리깅 모델은 각 목적 함수별로 통계적 기법을 통해 개별 모델을 생성한다. 학습된 두 모델은 이후 유전 알고리즘 기반의 재진입 비행체 형상 최적 설계에 활용된다.
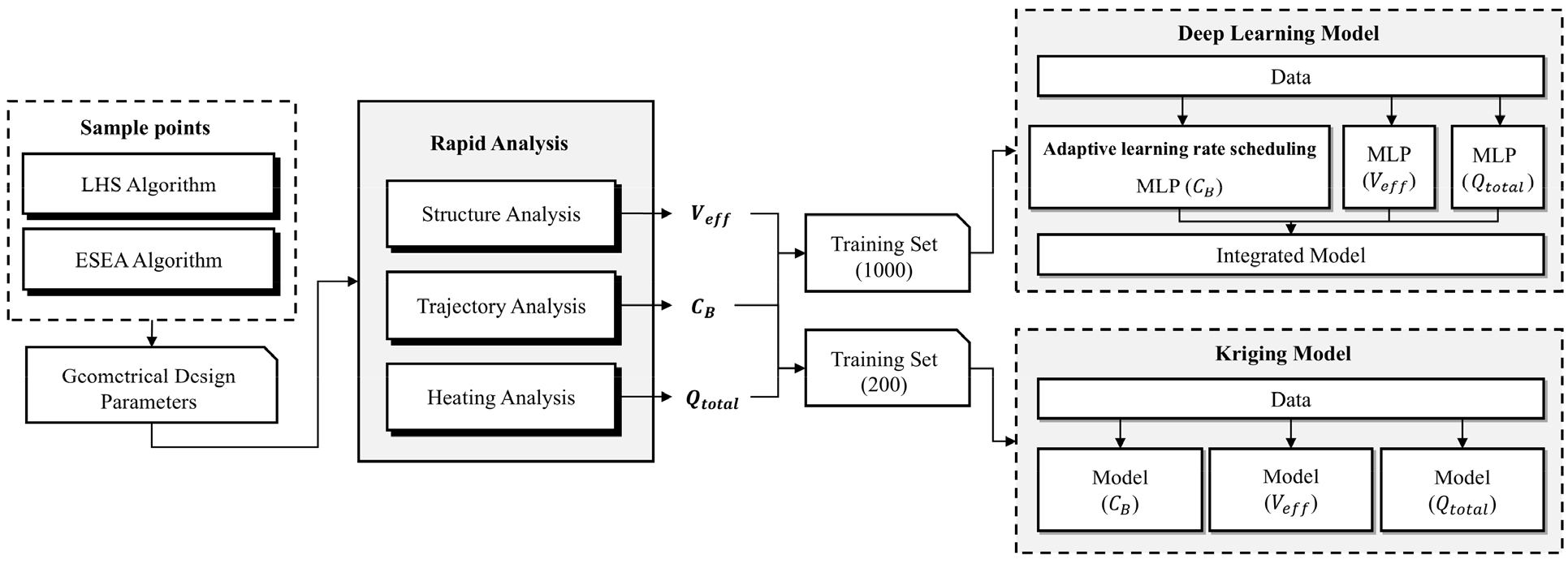
2.3.1 실험점 추출
모델의 정확도와 신뢰도를 확보하는 동시에 효율적인 해석 비용을 위해, 설계 변수 공간 전역을 균등하게 대표할 수 있도록 실험점을 배치해야 한다. 이를 위해 라틴 하이퍼큐브 샘플링(LHS)[26] 방법을 사용하였다. 라틴 하이퍼큐브 샘플링은 각 변수의 전체 구간을 여러 구간으로 나눠 각 구간 당 하나의 실험점만 추출하는 방법으로, 특정 영역에 실험점이 집중되는 현상을 방지할 수 있다는 장점이 있어, 많은 연구에 적용되어왔다[27,28,29,30].
라틴 하이퍼큐브 샘플링의 공간 채움 특성을 최적화하기 위하여 Enhanced Stochastic Evolutionary Algorithm (ESEA)[31]를 적용하였다. ESEA는 기존 라틴 하이퍼큐브 디자인(LHD)을 내부 교환함으로써 다양한 디자인을 생성하며, 이 과정에서 공간 채움 성능이 일정 임계값 이상으로 향상된 경우 최적 디자인을 갱신한다. 성능 향상 임계값은 지속적으로 조정되며 종료 조건이 만족되면 현재의 최적 디자인을 출력한다.
공간 채움 성능을 평가하기 위해 criterion 기법[32]을 이용하였다. 는 라틴 하이퍼큐브 디자인의 공간 균일성을 정량적으로 평가하는 지표로, 해당 값이 작을수록 샘플링의 균일성이 향상됨을 의미한다. 는 식 (7)와 같이 정의된다.
d는 실험점 사이의 유클리드 거리이며, p는 거리 가중치를 조절하는 지수로, 본 연구에서는 50으로 설정하였다. 본 연구에서는 이를 기반으로 최적화 과정에서 디자인의 성능을 평가하였다. ESEA를 적용한 라틴 하이퍼큐브 샘플링에는 SURROGATE TOOLBOX[33]를 이용하였다.
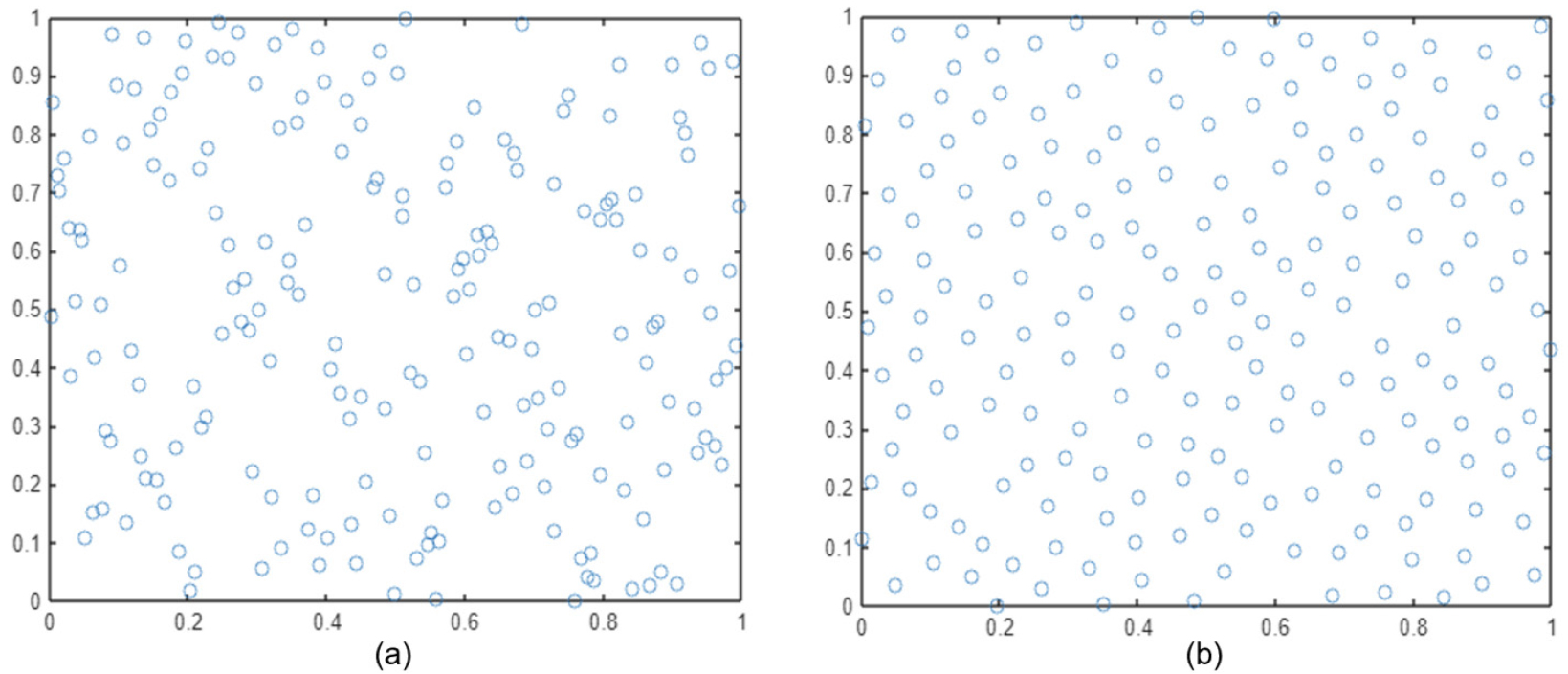
Fig. 4는 2차원 설계 공간에서 ESEA를 적용하지 않은 Matlab의 내장함수(lhsdesign)를 이용한 샘플링과 SURROGATE TOOLBOX의 ESEA를 이용한 샘플링의 비교 결과이다. 이를 통해 ESEA를 이용했을 시 샘플링의 공간 채움 성능이 향상되는 것을 확인할 수 있다. 대리 모델 구성을 위해 Table 2에 제시된 변수 범위에서 ESEA를 적용한 라틴 하이퍼큐브 샘플링을 수행하였다.
Hwang과 Martins[34]은 4차원 입력변수를 사용하는 회귀 문제에서 크리깅 모델이 1000개 이상의 훈련 샘플을 사용할 경우 수렴하지 않는 문제를 보고하였다. 이는 크리깅 모델의 계산 복잡도가 샘플 수와 입력 차원에 따라 급격히 증가함을 시사하며, 본 연구의 5차원 형상 설계 변수 문제에서도 유사한 현상이 관찰되었다. 실제로 크리깅 모델은 1000개 이상의 실험점을 사용했을 때 수렴 불안정과 계산 시간 증가가 발생하였다. 반면, 딥러닝 기반 모델은 데이터 수가 증가하더라도 학습 안정성과 계산 확장성이 상대적으로 뛰어나며, 특히 복잡한 비선형 회귀 문제에서는 충분한 학습 데이터가 주어질 경우 크리깅 모델보다 높은 예측 정확도를 보일 수 있다는 결과가 보고된 바 있다[35,36]. 따라서 본 연구에서는 크리깅 모델에는 200개의 실험점을 제한적으로 사용하고, 딥러닝 모델에는 1000개의 실험점을 적용하여 각 기법의 특성에 부합하도록 설계하였다.
2.3.2 크리깅 모델
크리깅 모델은 실험점의 반응값을 이용하여 임의의 점의 반응값을 예측하는 대리 모델의 일종으로, 비선형성이 강한 문제에 대해서도 높은 근사 성능을 보여 다양한 연구에서 대리 모델로 활용되고 있다[37,38,39,40,41]. 본 연구에서는 일반 크리깅(Universal Kriging) 모델[42]을 사용하였으며, 해당 모델에서 점 x의 반응(response,)은 상수의 전역 모델()과 확률 과정으로 표현되는 국부적 편차()의 합으로 나타난다.
전역 모델은 회귀 함수()들의 선형 결합으로 표현되며 본 연구에서는 전역 모델로 2차 회귀 모델을 사용하였다. 국부적 편차()는 0의 평균을 가지며 두 지점의 사이의 공분산은 식 (9)과 같이 표준 편차(𝜎)와 상관 함수 R로 표현된다. 상관 함수는 Gaussian function을 사용하였으며 이때 는 식 (10)과 같이 표현된다. 𝜃는 길이 의 가중치 벡터이며 는 x의 차원 수이다.
임의의 점에서 예측값은 식 (11)과 같이 계산된다. 은 상관 행렬, 는 회귀 함수로 이루어진 행렬으로 식 (12)로 표현된다. 은 식 (13)으로 표현된다. n은 크리깅 모델 구성에 쓰인 실험점의 개수이다.
는 𝛽의 예측값으로, 모델 구성을 위해서 모델의 파라미터인 , , 𝜃의 값을 추정해야 한다. 추정값들은 likelihood function의 값을 최대화하도록 결정되며, 이 결정되었을 때 ,를 추정한 결과는 다음과 같다.
을 결정하기 위해 𝜃를 추정해야 하므로, 반복적인 탐색을 통해 𝜃를 최적화하는 과정이 필요하다. 본 연구에서는 이러한 크리깅 모델 구성을 위해 SURROGATE TOOLBOX에서 제공하는 함수를 사용하였다. 2.2절에 제시된 다분야 해석 프레임워크를 이용하여 200개의 실험점에서 목적함수 값을 계산하고, 이를 기반으로 세 가지 목적함수 각각에 대한 독립적인 크리깅 모델을 구성하였다. 전체 실험점의 90%를 모델 구성에 사용하였으며 나머지 10%를 모델 검증에 활용하였다. 각 크리깅 모델의 성능은 R2 score와 Normalized Root Mean Square Error(NRMSE)를 계산하여 평가하였다. NRMSE는 RMSE를 정규화한 값으로, 데이터의 스케일이 다른 모델 간의 성능 비교에 용이하며 식 (16)을 통해 계산되었다. 은 데이터의 개수이며, 는 실제값, 은 예측값을 의미하며, Table 6에 각 크리깅 모델의 성능을 평가한 결과를 나타내었다.
2.3.3 딥러닝 모델
본 연구에서는 형상 설계 변수와 열해석 모델의 목적 함수 간 관계를 모델링하기 위해 딥러닝 모델로 MLP(Multi-layer perceptron)[43,44]을 사용하였다. 모델 학습은 경험식 기반 열공력 모델에서 생성한 샘플 데이터를 사용했으며, 목적 함수 간 상호 영향을 배제하기 위해 각 목적 함수별로 독립적인 학습을 수행하였다.
딥러닝 모델의 성능은 초기 데이터셋에서 학습용 데이터셋(Training Set), 검증용 데이터셋(Validation Set), 테스트용 데이터셋(Test Set)을 어떻게 분할하느냐에 따라 일부 변동이 발생할 수 있다. 이에 따라, 모델의 일반화 성능 비교의 신뢰성을 높이기 위해 Monte Carlo Cross- Validation을 통해 성능을 측정하고, 이를 평균내어 비교하였다. 전체 데이터셋을 80%, 10%, 10%으로 나누어 각각 학습용 데이터셋(Training Set), 검증용 데이터셋(Validation Set), 테스트용 데이터셋(Test Set)으로 사용하였다.
ⅰ. 데이터 전처리(Data processing)
본 연구에서는 데이터 정규화를 통해 입력 변수의 스케일을 조정하여 학습 안정성을 향상시키고, 모델의 수렴 속도를 개선하고자 하였다. 정규화 방법으로 Min-Max Normaliztion을 사용하였으며, 이는 각 변수의 값을 0과 1사이의 범위로 조정하는 방식이다. 정규화는 식 (17)과 같은 방법으로 수행되었다.
이러한 정규화 과정은 모든 형상 설계 변수와, 각 목적함수 데이터에 대해 독립적으로 적용되었다. 또한, 정규화된 데이터를 통해 모델이 다양한 범위의 데이터를 더 효과적으로 학습할 수 있도록 하여, 학습 안정성 및 일반화 성능을 향상시키도록 하였다. 각 목적 함수별 딥러닝 모델의 주요 hyperparameter를 도출하기 위해 trial-error 방법을 이용하여 hyperparameter tuning을 진행하였으며 그 결과는 Table 7와 같다.
Table 7.
Hyperparameter of models
| Model | |||
| Learning rate | 0.001 | 0.001 | 0.001 |
| Hidden layer | 4 | 5 | 4 |
| Batch size | 64 | 128 | 128 |
| Epochs | 1000 | 500 | 5000 |
| Optimizer | Adam | Adam | Adam |
ⅱ. 모델 학습
각 목적 함수별 학습을 위한 딥러닝 모델 구조는 Table 8에 제시되어 있으며 Fig. 5는 Table 7의 하이퍼파라미터 및 Table 8의 모델 구조를 적용하여 얻은 Epoch 대비 평균제곱오차(MSE) 손실 그래프를 나타낸다. Fig. 5는 부피 효율성() 모델과 총 가열량() 모델에 비해, 탄도 계수() 모델의 학습이 상대적으로 불안정함을 보여준다.
Table 8.
Model structure
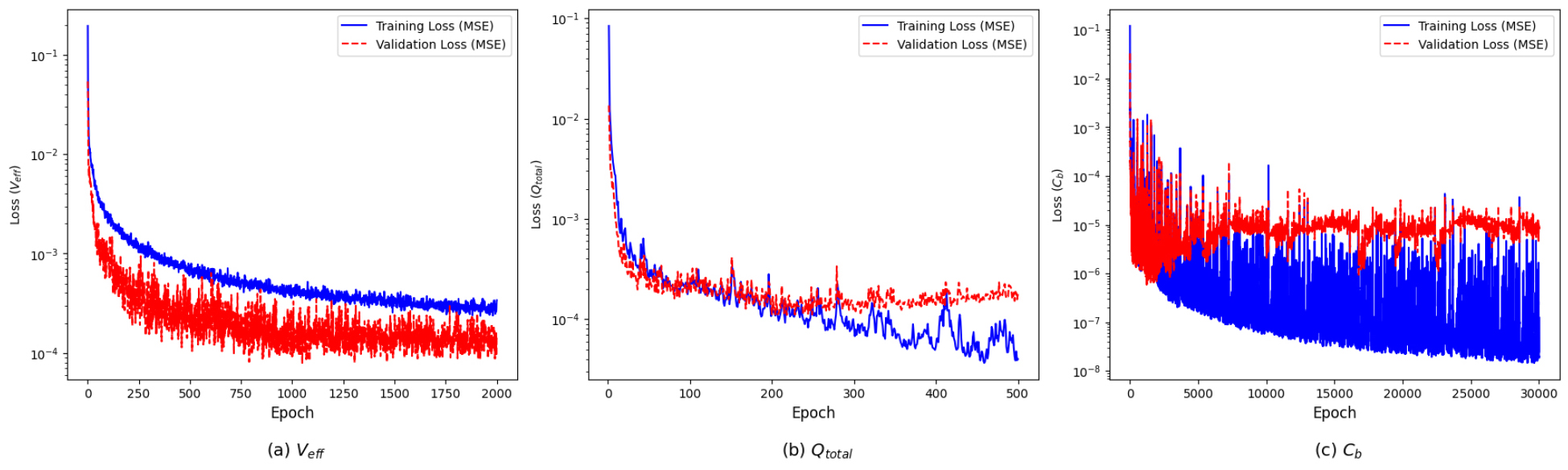
Table 9에는 탄도 계수 모델의 성능 분석 결과를 요약하였다. 부피 효율성 모델은 설계 변수만으로 계산된 단일 값을 학습 대상으로 활용하며, 총 가열량 모델은 비행 궤적 프로파일과 무관하게 전체 구간의 누적 열 부하를 입력으로 사용한다. 이에 비해 탄도 계수 모델은 재진입 궤적상에서 시간·고도별로 변화하는 값을 모두 반영하기 보다는 최대값만을 학습에 적용한다. 탄도 계수 모델은 궤적 전 구간의 물리 정보를 충분히 반영하지 못하여 나머지 두 목적함수처럼 설계 변수와 목적 함수가 명시적으로 도출되지 않아, 상관관계를 완전하게 학습하기 어렵다. 그 결과, 부피 효율성 및 총 가열량 모델은 손실 함수 수렴이 원활하고 예측 정확도가 안정적인 반면, 탄도 계수 모델은 학습 불안정성과 예측 성능 저하가 관찰되었다. 따라서 탄도 계수 모델의 신뢰성과 정확도를 개선하기 위해서는 추가적인 학습 전략이 필요하다.
Table 9.
Performance of model
| score | MAPE | NRSME | |
| 1 | 0.9297 | 3.8132% | 3.8797% |
| 2 | 0.9500 | 3.0067% | 3.2725% |
| 3 | 0.9467 | 3.2845% | 3.3787% |
| 4 | 0.9391 | 4.0592% | 3.6096% |
| 5 | 0.9483 | 3.5191% | 3.3262% |
| Average | 0.9428 | 3.5365% | 3.4933% |
탄도 계수 딥러닝 모델의 학습 안정성과 최적의 학습률 조정을 위해 적응형 학습률(Adaptive learning rate scheduling) 기법 중 Warm-Up[45]와 Cosine Annealing[46]을 적용하였다. Warm-Up와 Cosine Annealing을 통해 짧은 학습 시간 내에도 일반화 성능 향상 및 빠른 수렴을 달성할 수 있으며, 다양한 연구에서 효과가 입증되었다[47,48]. Warm-Up 방법은 식 (18)와 같으며, 본 연구에서는 초기 학습률을 =10-5로 설정하였다. Warm-Up 지속 기간동안에는 목표 학습률 까지 선형적으로 증가시키도록 하였다. Warm-up Epochs는 =50으로 설정하였다.
Warm-Up 이후에는 학습률을 점진적으로 감소시키기 위해 Cosine Annealing 학습률 스케쥴링을 적용하였다. Cosine Annealing 방법은 식 (19)과 같다.
본 연구에서는 학습 안정성과 예측 성능을 평가하기 위해 score, NRSME, MAPE를 회귀 평가 지표로 사용하였다. Fig. 6은 적응형 학습률 기법을 적용하기 전후의 Epoch 대비 loss 변화를 나타내며 Table 10은 탄도 계수 모델에 적응형 학습률 기법을 적용한 후, 각 목적 함수별 딥러닝 모델의 최종 학습 결과를 정리한 것이다. Fig. 6 및 Table 10의 결과를 통해 적응형 학습률 기법을 적용 시 학습 안정성이 향상되고, 탄도 계수()의 예측 성능이 개선됨을 확인하였다. 또한, 모든 목적함수에 대해 신뢰할 수 있는 수준의 목표 성능이 달성되었음을 검증하였다. 적응형 학습률 기법 적용 후에도 validation loss가 training loss보다 높게 나타난 것은 제한된 학습 데이터(1000개)와 모델 복잡도로 인한 과적합 때문으로 보인다.
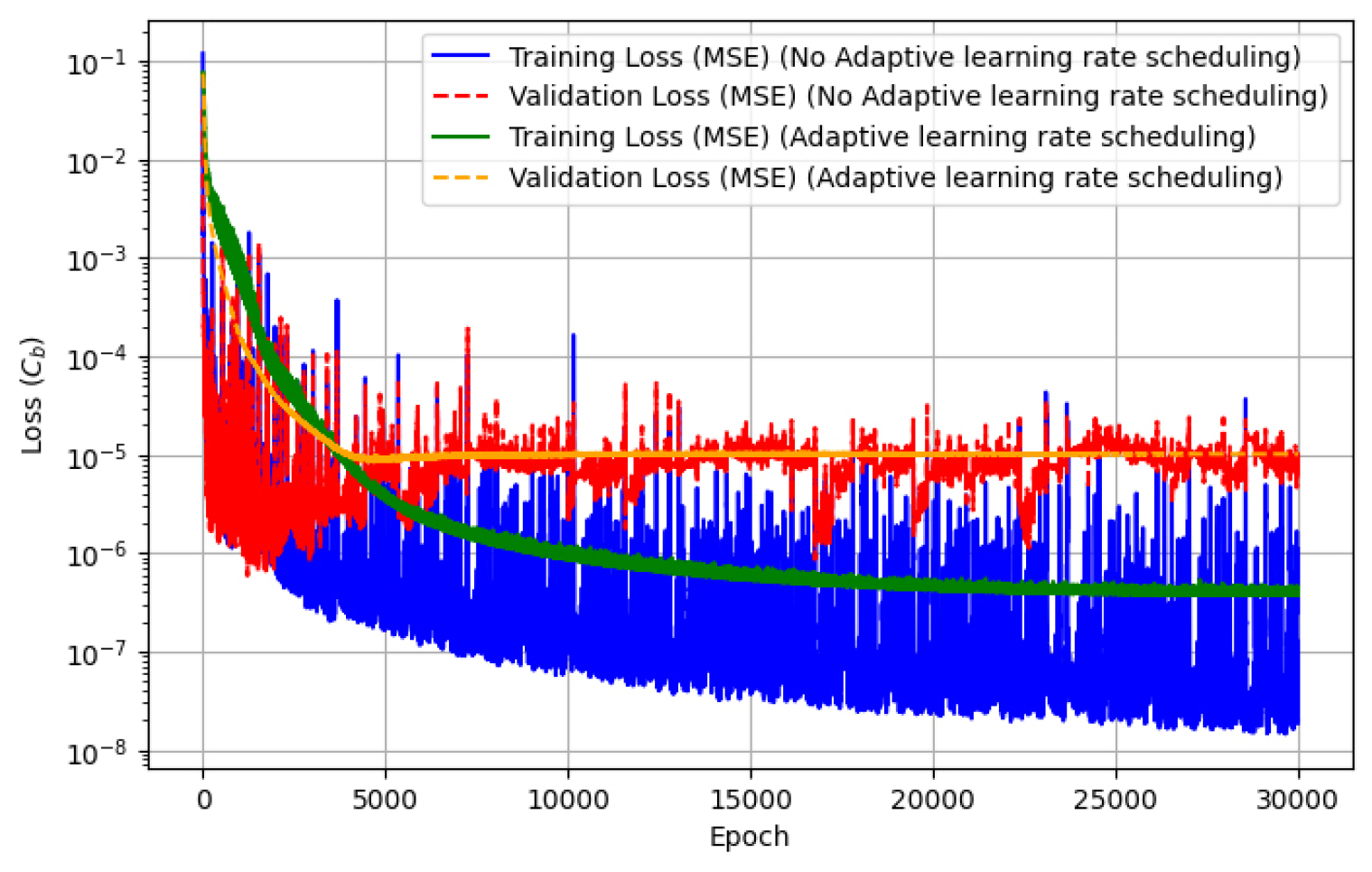
Table 10.
Performance of MLP models
2.4 다목적 최적 설계
2.4.1 최적 설계 프레임워크
다목적 최적 설계를 위해 대리 모델(크리깅 모델과 딥러닝 모델)을 활용하였으며, 자연 선택과 유전의 원리를 모방한 다목적 최적화 알고리즘인 NSGA-Ⅲ[49,50]을 구현하여 최적 설계를 위한 프레임워크를 구축하였다. 프레임워크의 흐름도는 Fig. 7과 같다. 프레임워크는 유전 알고리즘의 각 세대에서 생성된 개체들의 목적 함수 값을 대리 모델을 사용하여 성능을 예측하고 진화시켜 최적해를 찾는 방식으로 구성된다.
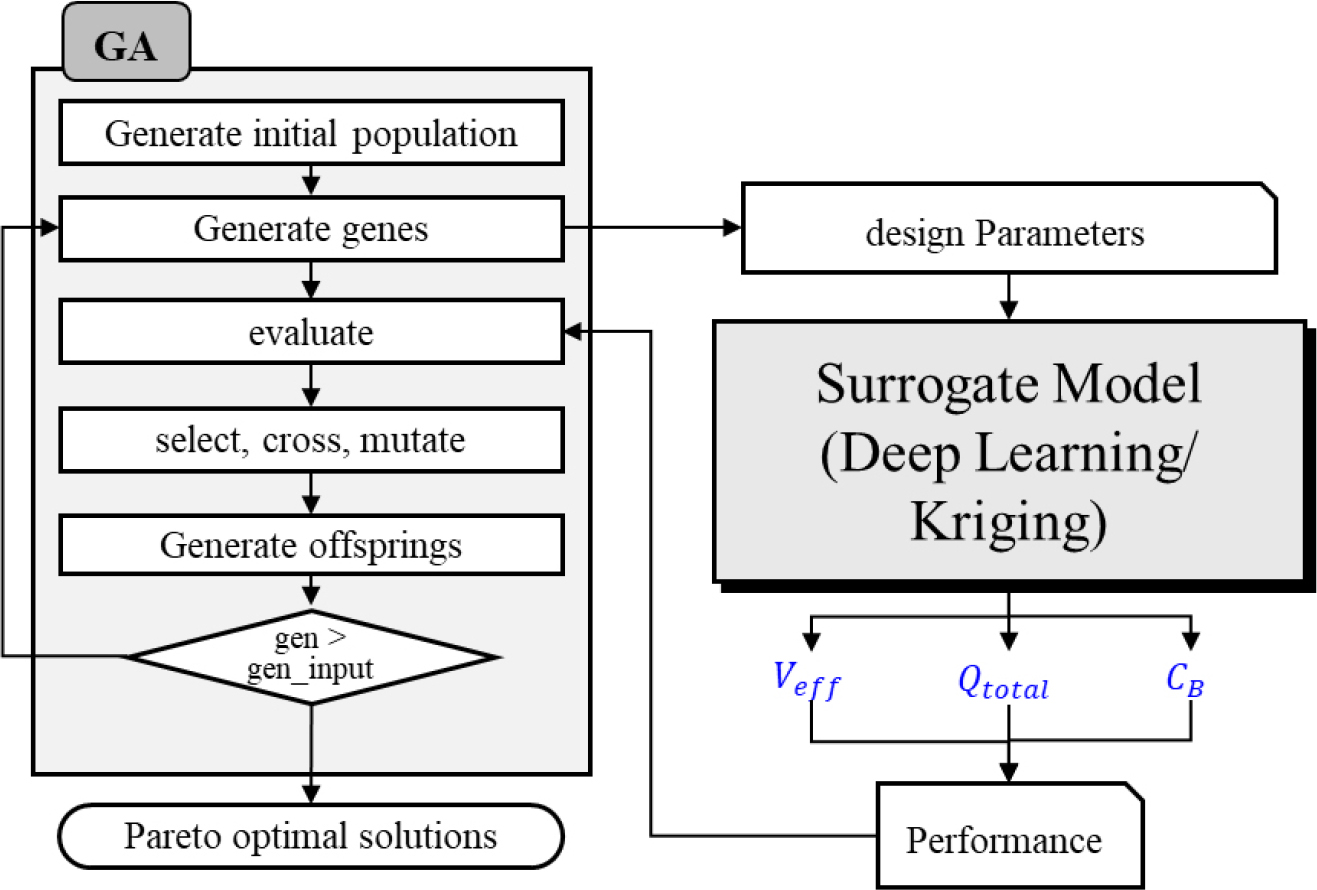
크리깅 모델과 딥러닝 모델은 각각 다른 환경에서 구축되었으므로 두 모델 간의 연산 구조 및 데이터 처리 방식에 차이가 존재하였다. 따라서 각 모델 특성에 최적화된 연산 성능을 유지하고, 프레임워크와의 연결성을 고려하여 동일한 NSGA-III 방법에 대해 각각 다른 최적화 도구를 적용하였다. 크리깅 모델을 활용한 다목적 최적화에는 Heris의 MATLAB NSGA-III 라이브러리[51]를 이용하였으며, 딥러닝 모델을 활용한 다목적 최적화는 Python의 Pymoo 라이브러리[52]를 이용하였다. 유전 알고리즘의 입력 파라미터는 두 모델간 동일한 값을 적용하였으며 Table 11과 같다. 유전 알고리즘의 초기 세대는 Table 2의 형상 설계 변수 범위 내에서 랜덤으로 선정하였다.
Table 11.
Genetic algorithm input parameters
| Input | Value |
| Generation | 500 |
| Population | 100 |
| Crossover probability | 1.0 |
| Mutation probability | 0.3 |
2.4.2 최적 설계 결과
대리 모델을 활용한 다목적 최적 설계 결과 도출된 크리깅 모델의 파레토 프론트와 딥러닝 모델로 도출된 파레토 프론트를 각 목적 함수에 대해 제시하였으며 Fig. 8과 같다. Fig. 8에 나타난 바와 같이, 딥러닝과 크리깅 기반 대리 모델을 통해 도출된 파레토 프론트는 형태와 분포 면에서 차이를 보이며, 이러한 차이는 각 모델이 목적함수 사이의 상관관계를 학습하고 반영하는 방식의 차이에서 기인한다. 딥러닝 모델이 목적함수 간 상관관계를 비선형적으로 학습 및 반영하여 연속적이고 균일한 해 분포를 제공하는 반면, 크리깅 기반 모델은 주어진 일부 데이터 분포에만 의존하므로 특정 구간에서 예측 불안정 및 분포 분절 현상이 관찰되었다. 이러한 결과는 대규모 CFD 데이터를 활용한 딥러닝 서러게이트가 크리깅보다 고차원 설계 공간에서도 고품질 해를 생성한다는 Keane & Voutchkov[53]의 보고와, 제한된 샘플에서 크리깅이 허위 최적해에 수렴할 수 있음을 지적한 Jin[54]의 분석을 모두 뒷받침한다. 본 연구를 통해서도, 다목적, 다분야 최적 설계 문제 및 전역최적화 문제에 두 서러게이트 모델을 적용 했을 때 딥러닝 모델은 복잡한 설계 변수 공간에서 목적함수들 간의 상관관계를 더 정확히 반영하며, 크리깅 모델보다 더 신뢰성 높은 파레토 해를 도출할 수 있음을 확인하였다.
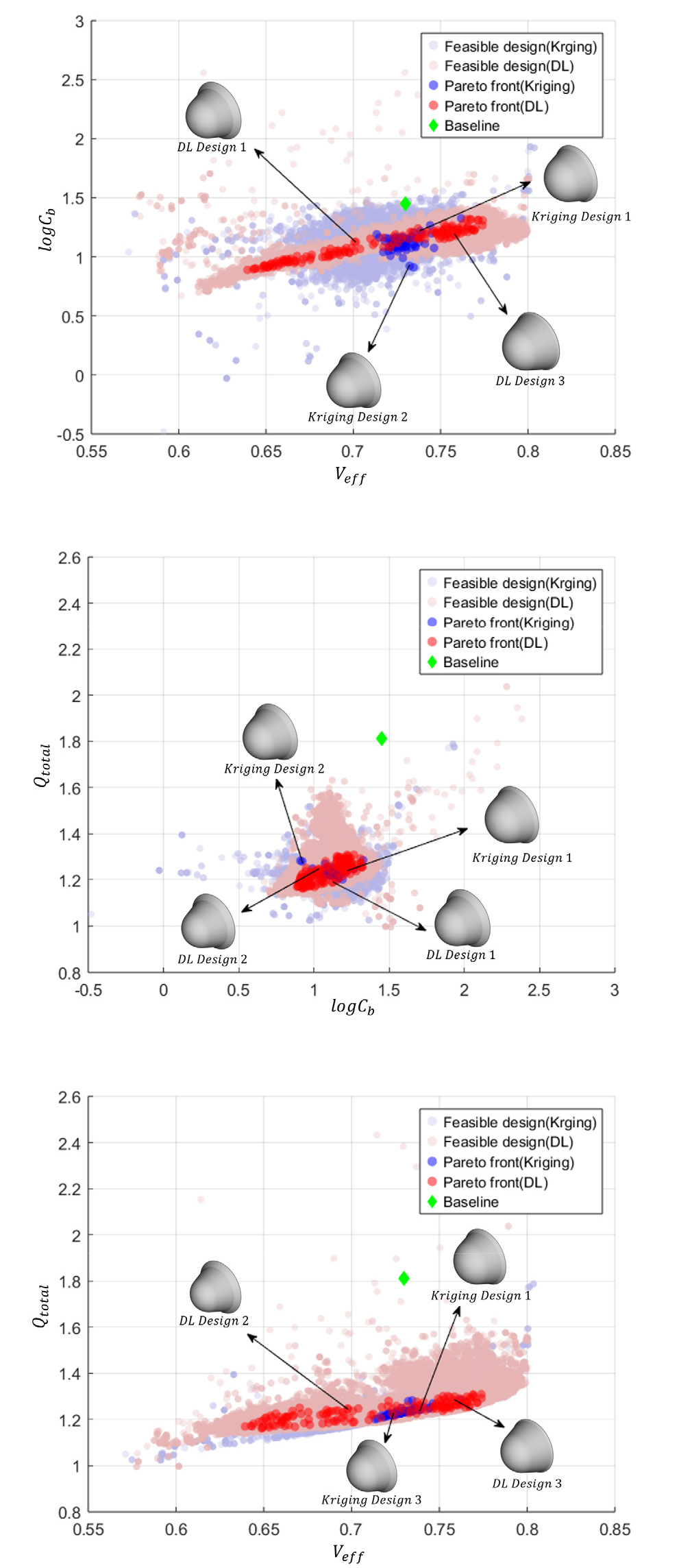
Fig. 8에서 파레토 프론트의 모양으로부터 각 목적 함수간 트레이드 오프 양상을 확인할 수 있다. 부피 효율성과 탄도 계수 간의 분포는 대체로 우상향하는 띠 형태로 수렴하였으며, 이는 부피 효율성이 증가할수록 탄도 계수도 함께 증가하는 경향을 의미한다. 이는 항력 향상을 위해 플레어를 확장할 경우, 부피 대비 면적 비율이 감소하여 부피 효율성이 저하되는 설계 특성에 기인한다. 부피 효율성과 총 가열량 간의 분포 또한 대체로 우상향하는 띠 형태이며, 부피 효율성이 높은 설계는 감속이 부족해 총가열량이 증가하는 경향을 보인다고 해석할 수 있다. 이는 플레어를 줄여 얻은 높은 부피 효율성이 감속 성능 저하로 이어져 재진입 비행체의 속도가 높게 유지되고, 이로 인해 열 부하가 집중되는 구조로 해석된다. 반면 총 가열량과 탄도 계수 간 분포는 명확한 상관관계 없이 하나의 군집으로 분산되어 있다.
다목적 최적 설계 결과 중 대표 후보 형상을 선정하기 위해 K-Means 클러스터링 기법[55]을 적용하였다. 클러스터링의 품질을 정량적으로 평가하기 위해 실루엣 점수(Silhouette score)[56]를 도출하였다. 실루엣 점수는 클러스터 내 응집도(cohesion)와 클러스터 간 분리도(separation)를 정량화하여, 클러스터링이 얼마나 잘 구분되었는지를 나타내는 지표이다. 클러스터 개수를 1~5개로 설정하여 실루엣 점수를 계산하였으며 클러스터가 3개일때 딥러닝 대리모델은 0.5645, 크리깅 대리모델은 0.6063으로 0.5 이상의 값을 보여 각 클러스터가 적절히 구분되었음을 확인하였다. 이를 통해 파레토 프론트 해 집단을 3개의 그룹으로 분류한 뒤, 유클리드 거리를 기준으로 각 클러스터의 중심과 가장 가까운 형상을 대표 후보 형상으로 선정하였다.
각 대리모델 별 3개의 후보 형상을 도출하였으며 Fig. 9와 같다. 각 후보 형상의 설계변수 값은 DL(Deep learning), Kriging으로 나누어 Table 12에 제시하였다. 모든 후보 형상이 선두부 곡률 반경이 최대값을 보이며, 이는 선두부의 곡률을 완화시켜 재진입 시 선두부에서 발생하는 열유속을 감소시키는 전략으로 해석된다. 이로 인해 비행체 선두부에서 흡수하는 총 가열량이 기본 형상에 비해 모든 형상에서 유의미하게 감소하는 양상을 보인다. 또한 모든 후보 형상은 기본 형상에 비해 플레어 길이()는 짧아졌으나 플레어 각도()는 더 크게 증가하였다. 의 증가는 형상의 유효 단면적을 증가시켜 항력을 크게 하였으며 탄도 계수를 감소시키는 영향으로 이어졌다. 탄도 계수의 감소로 인한 재진입 비행체의 충분한 감속은 비행체가 흡수하는 총 열량의 감소로 이어졌다. 하지만 높은 를 가진 플레어의 길이() 증가는 부피 효율성 확보에는 불리하게 작용하며, 다목적 최적화에서 상충관계(trade-off)가 존재함을 보여준다.
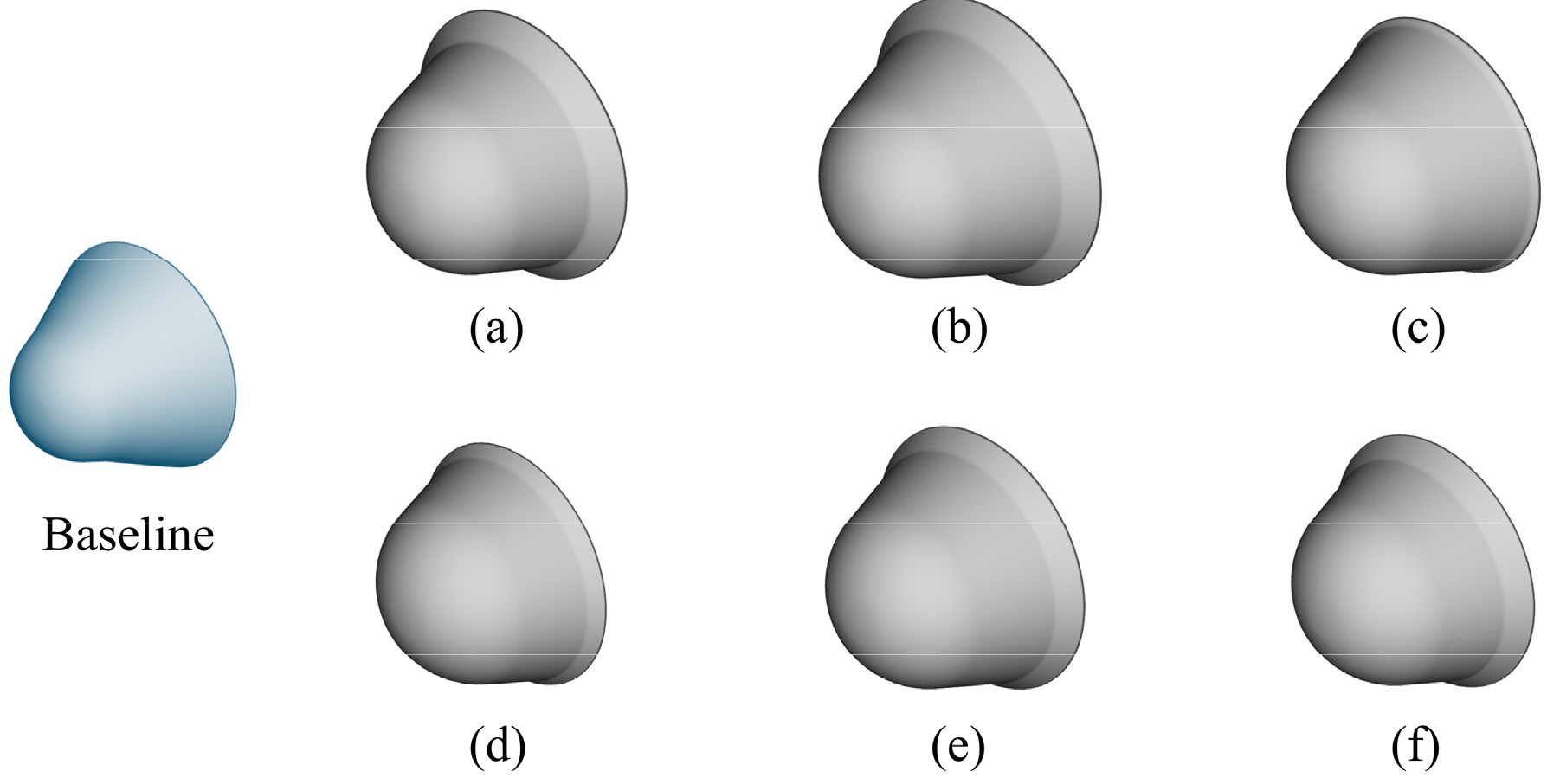
Table 12.
Optimization results using surrogate model
또한 대부분의 최적 설계안에서 은 기본 형상보다 감소하였으며 이는 큰 플레어 각도()로 낮은 탄도계수를 확보했으므로 은 감소시켜 해당 부분의 낮은 유효 단면적으로 총 흡수 열량을 감축하는 전략으로 보인다. 은 대폭 증가하여 기본 형상과는 반대로 이 보다 긴 디자인을 채택하였는데, 이는 탄도계수 감축을 위한 큰 의 영역이 캡슐의 후방부에 위치해야 그 길이를 짧게 하여 부피 효율성을 증가시킬 수 있기 때문으로 보인다. 부피 효율성은 전반적으로 기본 형상과 유사하거나 소폭 감소하는 수준에서 유지되었으나, DL Design 3의 경우, 가 0.072 m로 가장 짧고 는 0.956 m로 가장 크며 이로 인해 가장 큰 부피 효율성을 보인다. 이는 감속 성능 및 열 감소 효과보다는 내부 부피 확보에 유리한 방향으로 진화된 사례라고 해석할 수 있다. Kriging Design 2의 경우, 목적함수들의 균형 관점에서 우수한 설계한 중 하나로 평가된다. 해당 설계는 전체 후보 중 가장 낮은 탄도 계수를 보였으며, 총 가열량 역시 기본 설계 대비 로 감속 성능과 총 가열량 저감 측면에서 높은 효율을 보였다. 부피 효율성 역시 기본 형상과 유사한 수준을 유지하며 부피 활용 측면에서도 실용성을 확보하였다. 형상 변수 측면에서 보면, 플레어 각도는 33.17°로 상당히 증가했으며, 플레어 길이는 0.245 m로 기본 설계 대비 약 72% 감소하였다. 전방부 길이는 0.795 m로 길게 늘어나 유선형 형상을 형성하고 있으며, 선두부 곡률 반경 또한 최대값인 1.0 m로 열유속 감소 전략이 적용되었다. 이처럼 Kriging Design 2는 각 목적함수 간의 상충관계를 효과적으로 조율한 균형적 설계로 판단된다. 결과적으로, 플레어 각도()의 증가는 탄도 계수와 총 가열량 감소에 기여하는 한편, 플레어 길이()의 단축은 부피 확보에는 유리하지만 감속 성능 확보에는 불리하게 작용할 수 있음을 보여준다.
3. 결 론
본 연구에서는 극초음속 환경에서 재진입 비행체의 최적 설계를 목표로, 대리 모델을 활용한 다목적 최적화 기법을 적용하였다. Blunt-cone-flare typed module shape 형상의 비행체를 기준으로 부피 효율성, 총 가열량, 탄도 계수를 목적 함수로 설정하였으며, 경험식 기반 열공력 모델식을 통해 생성된 데이터를 활용하여 크리깅 모델과 딥러닝 모델을 학습하였다. 또한 라틴 하이퍼 큐브 샘플링(LHS)와 ESEA 알고리즘을 활용하여 실험점 분포의 균일성을 확보하고, 대리 모델 학습 데이터를 최적화하여 모델의 정확도와 신뢰도를 높였다. 크리깅 모델의 경우 전역 모델을 2차 모델로 선정하였으며 상관 함수로 Gaussian 함수를 사용하였다. 딥러닝 모델의 기본 구조로 MLP를 사용하였으며, 목적 함수 간의 상호 영향을 제거하기 위해 각 목적 함수를 개별적으로 학습하였다. 나머지 목적 함수에 비해 탄도 계수 모델의 학습 성능이 저하되는 문제를 해결하기 위해 적응형 학습률 기법을 적용하였으며, score 비교 결과에서 성능 향상이 확인되었다.
본 연구에서는 대리 모델 기반의 다목적 최적화 기법을 적용하여 재진입 비행체의 형상 설계를 수행하였다. 유전 알고리즘과 연계된 딥러닝 및 크리깅 모델 기반 대리 모델을 통해 파레토 프론트를 도출하고, K-means 클러스터링 기법을 활용하여 총 6개의 대표 파레토 해를 선정하였다. 최적화 결과, 기본 형상 대비 최대 70.2%의 탄도 계수 감소, 4.1%의 부피 효율성 증가, 34.3%의 총 열 부하 감소가 이루어진 형상이 도출되었으며 이는 다목적 최적 설계를 통해 재진입 성능을 효과적으로 향상시킬 수 있음을 보여준다.
계산 효율성 측면에서도 딥러닝 대리 모델은 NVIDIA의 T4 GPU 계산 환경에서 최적화에 총 102.3009초의 시간이 소요된 반면, 크리깅 모델은 AMD의 Ryzen7 8845hs CPU 계산 환경에서 총 4496.165922초로 약 44배 이상의 시간이 소요되어, 딥러닝 모델의 우수한 계산 효율을 확인할 수 있었다. 클러스터링 결과 또한 실루엣 점수가 0.5 이상으로 군집 간 경계가 명확히 형성되었으며 이는 다양한 설계 해 간의 상충관계를 효과적으로 반영한 결과로 해석된다.
특히 딥러닝 기반 모델은 복잡한 설계 변수 공간에서 목적함수 간의 상관관계를 보다 정밀하게 반영하여, 크리깅 기반 모델에 비해 더 우수한 파레토 프론트 해를 생성하는 것으로 나타났다. 이는 딥러닝 모델이 비선형적이고 복잡한 설계 문제에서도 높은 표현력과 일반화 능력을 바탕으로 효과적인 대리 모델로 활용될 수 있음을 시사한다. 또한 딥러닝 기반 최적화는 GPU 가속 환경에서 매우 짧은 시간 내에 계산이 가능하여 실시간 설계 공간 탐색 및 반복적인 최적화 프로세스에 적합한 장점을 지닌다. 반면, 크리깅 기반 대리 모델은 본 연구에서 고려한 5개의 형상 변수와 같은 고차원의 설계 공간에서는 근사 성능이 상대적으로 저하되며, 크리깅 모델의 한계로 인해 제한된 학습 데이터 수(200개)에서 예측의 불안정성이 증가하는 한계를 보였다. 이러한 이유로 크리깅 모델은 일부 목적함수 영역에서 허위 최적해(false optimum)에 수렴하거나, 파레토 프론트의 다양성과 품질이 저하되는 경향을 나타냈다.
이에 따라 본 연구에서는 CFD 기반 고비용 계산을 수행하지 않고도 효율적인 최적 설계가 가능한 딥러닝 기반 대리 모델을 최적화 설계 프로세스에 도입함으로써 계산 자원과 시간을 크게 절감하면서도 신뢰도 높은 최적 설계안을 도출할 수 있음을 입증하였다. 향후 연구에서는 다양한 비행 조건 및 형상 변수에 대한 연구를 확장하여 설계의 일반성을 높이는 데 기여할 수 있을 것이다.
