

1. 서 론
2. 물리 기반 시뮬레이션 모델 구축
2.1 수치해석
2.2 축소차수모델(ROM) 구축
2.3 Modelica 모델 구축
2.4 통합 시뮬레이션 모델 개발
3. 베이지안 최적화(BO) 기반 모델 보정
3.1 Modelica 모델 파라미터 보정
3.2 가우시안 프로세스 회귀(GPR) 기반 베이지안 최적화(BO) 구축
3.3 대리 모델링 기법
3.4 대리 모델별 최적화 성능 비교
4. 실험 및 결과
4.1 펌프 성능 시험 및 시뮬레이션 결과 비교
4.2 실시간 펌프 시스템 성능 예측 결과 비교
5. 결 론
1. 서 론
최근 에너지 사용 비용 증가, 화석 에너지의 한정성 그리고 환경오염 문제는 지속 가능한 에너지 솔루션의 필요성을 강조하고 있다. 특히 주거 및 상업용 건물의 에너지 사용량이 전 세계 에너지 소비 중 약 40%를 차지하며, 주로 냉난방, 환기 및 공조(HVAC) 시스템에서 발생한다[1,2]. 이에 따라 건물 부문에서의 에너지 소비에 대한 규제가 강화되고 있으며, 효율적인 에너지 관리 및 에너지 소비 해결책이 요구되고 있다.
에너지 소비가 높은 고층 건물에서는 중앙집중식 냉난방 시스템을 통해 공조 에너지 절감을 이루고 있다[3]. 이 시스템은 중앙 장치에서 생성된 냉난방 매체를 순환 펌프를 통해 건물 전체에 제공하는 방식으로 운영된다. 펌프 시스템은 냉매 순환에 필수적이며, 대용량 에너지를 효율적으로 운반하여 시스템의 안정성을 유지한다. 그러나 건물 환경에서의 에너지 수요는 재실자 비중, 날씨 등에 따라 시간별로 변동하며, 이는 펌프 운영의 효율성과 안정성에 영향을 미친다. 불규칙한 에너지 수요와 부하 조건은 펌프 부품의 마모를 증가시키고 시스템의 안정성을 저해한다.
이러한 문제에 대응하기 위해 펌프 시스템에 디지털트윈을 활용한 실시간 성능 모니터링의 필요성이 대두되고 있다. 디지털트윈은 실제 시스템을 가상 공간에 구현함으로써, 변동하는 운영 조건과 실시간 데이터를 반영하여 펌프 시스템의 효율성과 안정성을 향상시키는 데 중요한 역할을 한다. 특히 펌프 시스템의 성능 모니터링 및 최적제어를 위한 디지털트윈 연구에서는 펌프의 물리적 특성과 운영 조건을 반영하는 시뮬레이션이 중요해지고 있다. 하지만 기존의 3차원 CFD (Computational Fluid Dynamics) 기법은 계산 복잡성과 높은 컴퓨팅 자원 요구로 인해 실시간 운영 솔루션에 바로 적용하기 어려운 한계가 있다. 이를 극복하기 위해 축소차수모델(Reduced-order Model, ROM)을 사용하는 접근 방식이 제안되고 있다. 이 방법은 복잡한 CFD 모델 결과를 간략화하여 적은 계산 리소스로 빠르게 근사치를 제공함으로써, 실시간 데이터 분석 및 최적화 전략에 효과적으로 통합할 수 있는 가능성을 제시한다.
원심 펌프의 성능 연구 분야에서도 유동 특성을 빠르고 정확하게 예측하는 것이 중요한 과제로 부상하고 있다. Guo 등[4]은 제트 원심 펌프의 원판 영역에서 발생하는 유동장 변동과 유동 유발 소음을 예측하기 위해 POD(Proper Orthogonal Decomposition) 기법을 활용한 모델을 개발하였으며, Wei 등[5]은 POD-ROM 기법 적용을 통해 속도와 압력 필드의 신속한 예측이 가능하게 하였다. Van der Walt 등[6]은 ROM 기법을 활용하여 이중 흡입 원심 펌프의 흡입 마모 링의 누설 흐름 예측 연구를 수행하였다.
선행 연구들은 시뮬레이션을 통해 펌프 모델의 성능과 작동 특성을 이해하고 예측하는 데 중요한 기여를 했으나, 여러 부품이 상호작용하는 복잡한 시스템의 전체적인 동작을 예측하는 데는 한계가 있다. 실제 운영 환경의 동적인 변화는 펌프의 성능과 특성에 직접적인 영향을 미친다. 예컨대, 운영 조건의 변화나 유체의 특성은 펌프의 효율성, 운영 수명, 그리고 유지보수 요구에 큰 영향을 줄 수 있다. 따라서, 변화하는 운영 환경을 시스템 해석 모델에 통합하는 것은 펌프 시스템의 정확한 모니터링과 최적화를 위해 필수적이다. 이를 위해서는 실시간 데이터의 수집 및 분석이 중요하며, 이를 통해 펌프의 성능을 지속적으로 평가하고 필요에 따라 조정하여 최적 상태를 유지할 수 있다.
본 연구의 주요 목표는 ROM을 활용한 물리 기반 시뮬레이션 모델을 개발하여, 입형 원심 펌프 시스템 테스트베드의 실시간 운전 상태를 정확하게 예측하는 것이다. 이를 위해 수집된 계측 데이터를 바탕으로 베이지안 최적화(Bayesian Optimization, BO) 기법을 적용해 모델의 파라미터를 최적화하여 실제 펌프 시스템의 현재 상태를 반영할 수 있도록 한다. 최종적으로는 계측 데이터와 가상센서 사이의 정확도를 검증하며, 검증된 모델은 향후 펌프 시스템의 효율성 향상 및 제품 수명 연구에 활용될 예정이다.
2. 물리 기반 시뮬레이션 모델 구축
본 연구에서 사용되는 테스트베드는 Fig. 1과 같이 밀폐된 순환 구조로 되어 있으며, 압력 조절용 탱크와 연결된 펌프 흡입관을 통해 유체가 원심 펌프로 흐르고, 토출관을 통해 배출된 후 다시 탱크 상단으로 되돌아간다. 펌프 운전 조건은 전동 밸브를 이용한 유량 조절 및 인버터 제어를 통해 조절되는 3상 유도 전동기의 회전 속도로 관리된다. 본 연구의 핵심 목표는 이러한 테스트베드의 실제 운영 데이터를 반영하는 물리 기반 시뮬레이션 모델을 구축하는 것이다. 이를 구축하기 위한 구체적인 연구 방법은 다음과 같이 수행되었다.

2.1 수치해석
2.1.1 수치해석 영역 및 경계 조건
본 연구에서 사용된 다단 입형 원심 펌프는 인라인 방식으로 구성되며, Fig. 2에서 볼 수 있듯이 2개의 임펄러와 디퓨저로 구성되어 있다. 이 펌프는 수직 축을 중심으로 부싱과 지그를 통해 고정되어 있으며, 입구와 출구 유로가 동일한 방향에 위치한다. 해당 모델은 케이싱, 디퓨저, 흡입 및 토출 유로와 같은 고정 영역과 임펠러와 같은 회전 영역으로 구분된다. 연구에 사용된 모델은 Elements 30,743,817개와 Nodes 11,920,868개의 격자 해상도 가지며, 도메인 및 경계조건은 Fig. 3과 Table 1에 나타내었다. 도메인은 해석의 수렴을 위하여 입, 출구 영역을 각각 배관직경 대비 5배, 10배 이상으로 연장하여 해석에 반영하였으며, 경계조건으로는 입구 측에 압력 조건, 출구 측을 유량 조건으로 설정하였다. 본 펌프 모델의 수치해석은 상용 CFD 코드 ANSYS CFX 2022 R2를 사용하고, 인텔 Xeon(R) Gold 6230R CPU(@ 2.10GHz), 192GB RAM을 탑재한 컴퓨터로 병렬 계산되었다. 각 케이스의 계산에는 대략 8시간 정도 소요되었다.
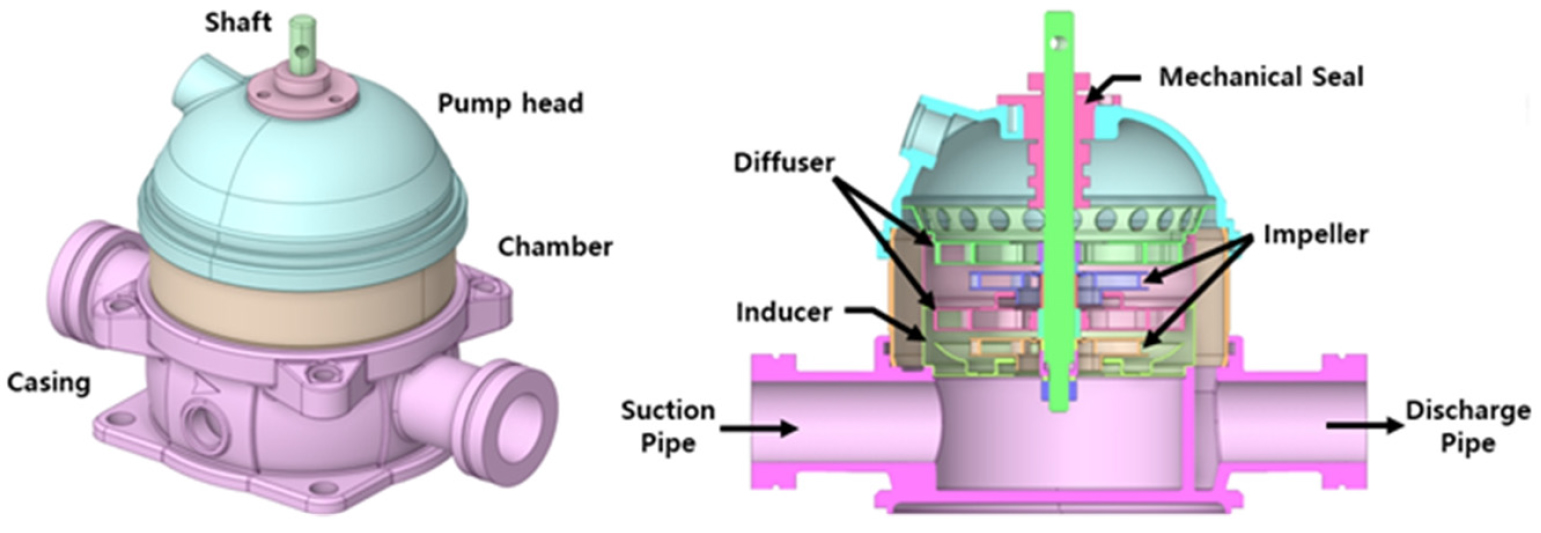
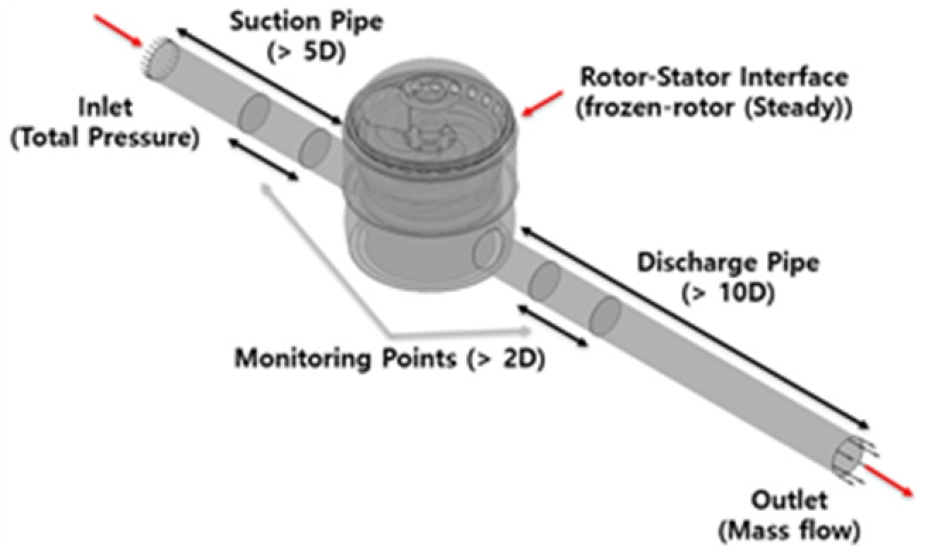
Table 1.
Analysis settings for pump flow in the vertical two-stage centrifugal pump
| Domain Setting | Boundary Setting | ||
| Analyze | Steady State | Suction Pipe | Total Pressure |
| Material | Water at 25℃ | Discharge Pipe | Mass flow rate |
| Turbulence | SST | Impeller | Rotational Speed |
| Others | No-slip Wall | ||
2.1.2 수치해석 결과 검증
본 연구에서 수행된 수치해석의 검증을 위해 펌프의 정격 회전수 조건에서의 다양한 질량 유량에 대한 양정 결과 비교를 수행하였다. Fig. 4에서 보이는 그래프는 펌프의 수치해석 결과와 실제 테스트베드 측정값을 나타내며, 유량에 따른 펌프의 양정은 입구와 출구의 압력 차이로 측정하여 비교하였다.
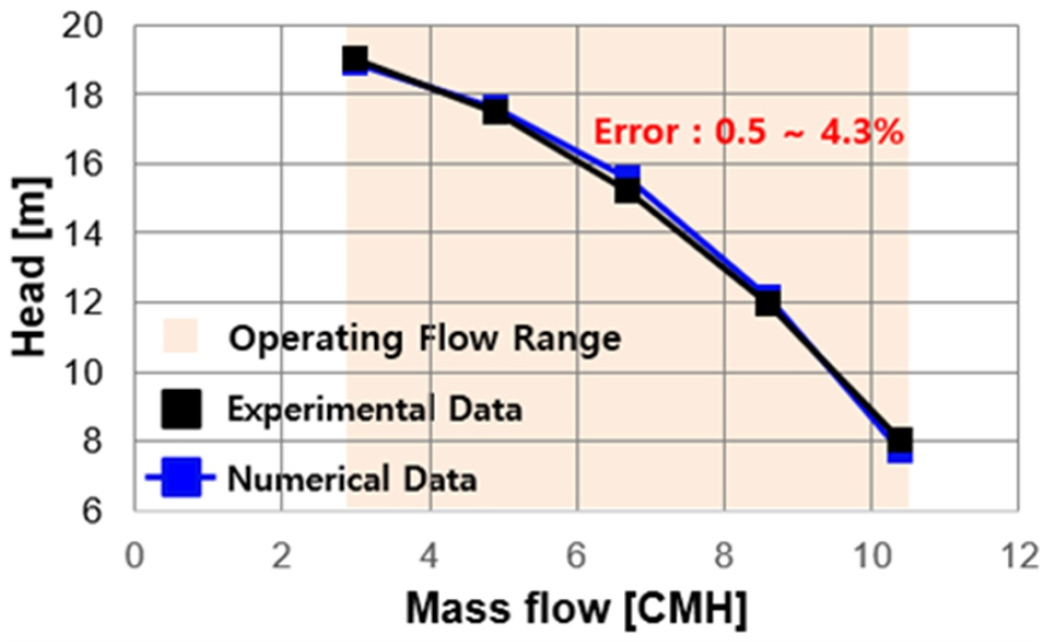
분석 결과, 실험 데이터와 수치해석 데이터 사이에는 최소 0.5%에서 최대 4.3%의 오차 범위가 확인되었다. 이는 펌프의 주요 운영 유량 범위에서 두 데이터 간 높은 일치도를 나타내며, 수치해석 모델이 펌프의 실제 성능을 신뢰성 있게 예측할 수 있음을 의미한다. 이러한 결과는 ROM 구축에 있어서 수치해석 모델의 적용이 타당함을 입증하며, 펌프 시스템의 성능 분석 및 예측을 위한 중요한 데이터를 제공한다.
2.2 축소차수모델(ROM) 구축
ROM의 구축은 Sirovich[7]에 의해 제시된 스냅샷 기법을 활용하여 CFD 결과에서 최적의 기저와 가중치를 추출하는 과정으로 시작된다. 이 기법은 POD 방법론을 사용하여 고차원 공간의 유동장을 새로운 조건에서 재구성할 수 있다. POD 기법은 식 (1)을 통해 벡터장을 선형 중첩하는 방식으로 작동한다.
주어진 행렬 은 행과 열로 구성된 열벡터로 이루어진다. 여기서 는 개의 입력 매개변수와 격자 상에서의 결과를 가지는 열벡터이다. 축소 모델에서는 다음과 같이 벡터장 를 기저벡터 로 선형 중첩하여 근사화한다. 이때 기저벡터는 시간과 공간에 따라 동시 모사가 필요하지만, 수식화를 위해 시간과 공간을 분리하는 방법을 사용한다. POD 기저와 확대 계수 를 결정하기 위해 식 (2)와 같이 특이값 분해(Singular Value Decomposition)를 사용한다. 이를 통해 행렬은 (좌특이 행렬), (우특이 행렬), (대각행렬)로 분해되며, 의 대각성분은 특잇값을 나타낸다. 이 분해된 행렬을 이용하여 저차원으로 근사화된 행렬을 얻을 수 있다.
ROM 구축을 위해서는 다양한 입력 변수에 따른 해석 시나리오를 수립하고 훈련 데이터를 수집하는 과정이 필요하다. 본 연구에서는 펌프의 권장 운영 범위 내에서 19가지 시나리오를 Fig. 5에 따라 설정하고 해석을 수행하였다. 이 중 16 케이스(전체의 약 85%)는 훈련 데이터로 활용되었으며, 나머지 3개 시나리오는 모델의 검증을 위해 사용되었다. 실시간 해석을 위한 ROM의 입, 출력 데이터는 Table 2에 명시되어 있으며, Output Parameter의 EA는 출력 가상센서 개수를 나타낸다.
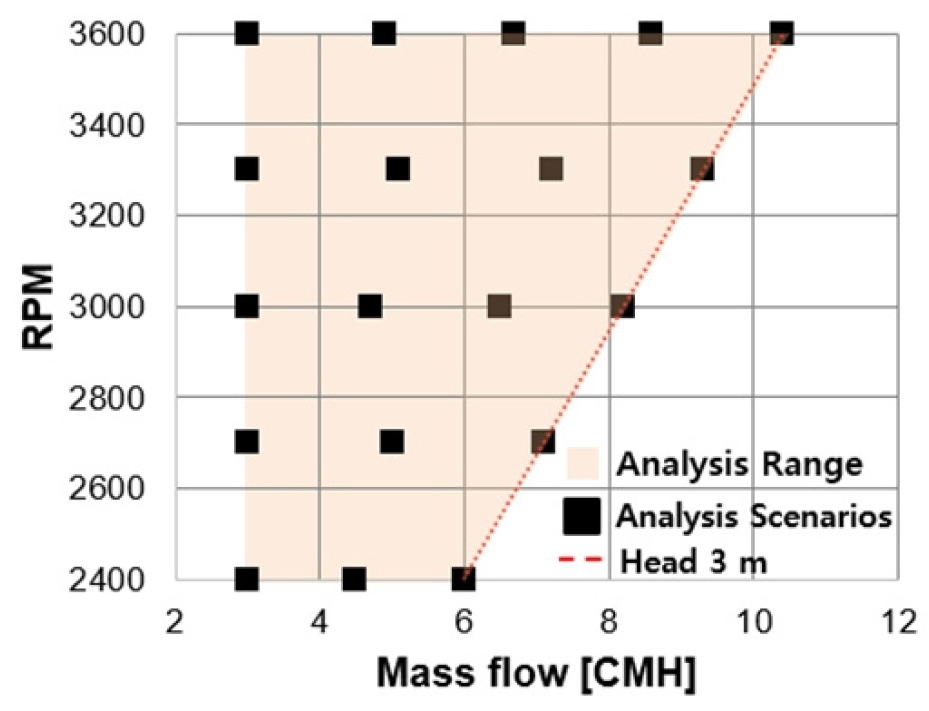
Table 2.
Real-time analysis input & output parameter for ROM
| Input Parameter List | Output Parameter List | ||
| Output | Model | EA | |
| Mass flow rate [CMH] | Head Field | ROM | 11,920,868 |
| Pump RPM [RPM] | Velocity Field | ROM | 11,920,868 |
| Shaft Power | RSM | 1 | |
| Efficiency | RSM | 1 | |
Static ROM 생성은 Fig. 6와 같이 ANSYS Twin Builder 내 ROM Builder를 활용하였으며, 인텔 i7(@ 3.80GHz) 8코어 CPU, 64GB RAM을 탑재한 컴퓨터에서 수행되었다. 훈련 단계(Fig. 6(a))에서는 16개의 케이스를 활용하고 10개의 모드를 설정하여 축소 오차(Reduction RMS Error) 0.18%, Leave One Out RMS Error는 0.55%로 나타났다. 이때 입력 매개변수 은 2(‘RPM’과 ‘Massflow’), 격자의 수 은 11,920,868로 설정되었다. Fig. 7은 검증 단계(Fig. 6(b))에서 나머지 3 케이스에 대하여 Full-order CFD와 ROM의 압력 결과를 비교하여 가장 오차가 큰 케이스에 대한 그림으로, 축소 오차는 최대 0.26%, 평균 오차는 약 1054 Pa로 확인하였다.
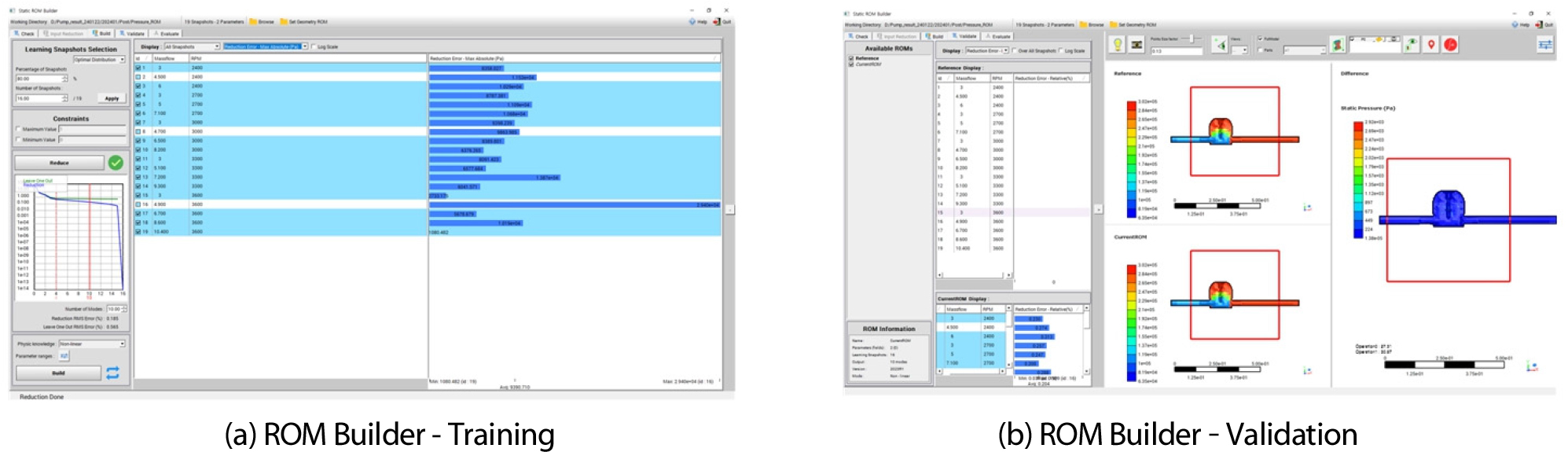
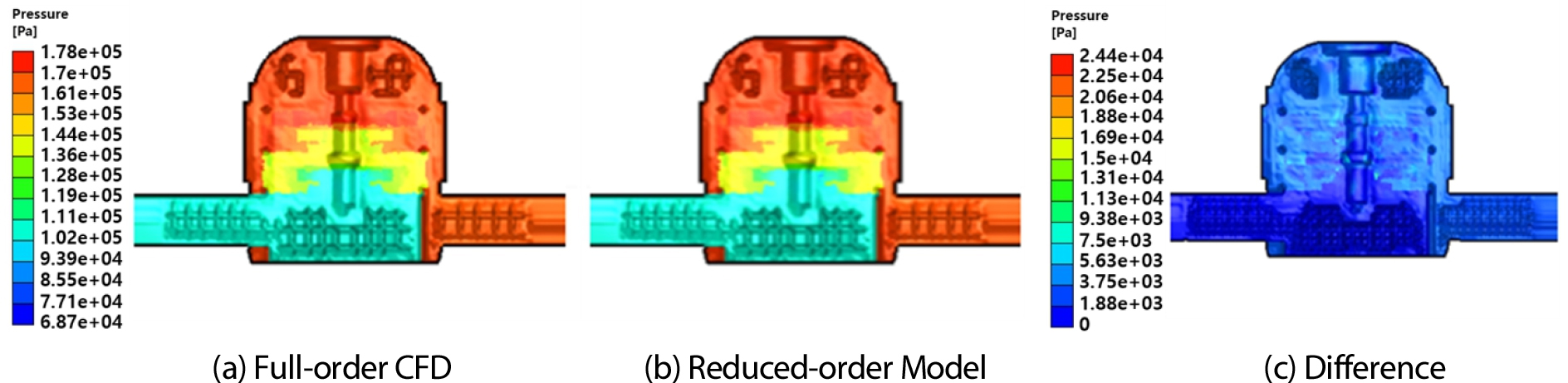
해당 과정은 훈련 데이터 세트를 생성하기 위한 해석 과정에서 상당한 컴퓨팅 리소스를 필요로 한다. 이는 단기적으로는 비용이 발생하지만, 장기적으로 보면 이러한 초기 투자가 다수의 해석 사례에 대한 신속하고 효율적인 시뮬레이션 실행을 가능하게 하는 기반을 마련해준다. Table 3은 수치 해석 방법과 ROM을 사용한 방법 간의 계산 시간과 필요한 자원을 비교한 것으로, ROM이 구축된 이후에는 상대적으로 짧은 시간 안에 대규모 시뮬레이션 작업을 수행할 수 있음을 보여준다. 이는 실시간 해석을 필요로 하는 실제 환경에서 ROM이 신속한 의사결정을 지원하는 데 중요한 역할을 할 수 있는지 입증한다.
Table 3.
Comparison of analysis time and resources by analysis method for a single case
| Method | Analysis Time | Analysis Resource |
| Numerical Simulation(ANSYS CFX) | ~ 8 hour | 120 core -HPC |
| Reduced-order Model(ANSYS Twin Builder) | ~ 1 sec | 8 core -Desktop |
2.3 Modelica 모델 구축
Modelica는 복잡한 시스템을 효과적으로 모델링하기 위해 주로 0차원 또는 1차원 형태로 구현된다[8]. 이러한 접근 방식은 펌프 시스템과 같은 복잡한 구조를 수학적으로 표현하는 데 특히 유용하며, 펌프의 단순한 동작뿐만 아니라 다양한 부품 간의 상호작용도 포괄적으로 고려할 수 있다. 이 연구에서는 계산 부담이 상대적으로 적은 영역을 대상으로 Modelica를 사용하여 Fig. 8에서 보여지는 바와 같이 펌프 시스템 모델을 구축하였다. 이 모델의 입출력 데이터는 Table 4에 정리되어 있으며, 펌프 회전수 및 밸브 개도율에 따른 유량을 계산할 수 있도록 설계되었다. 펌프 시스템 모델에는 Fluid Package 내 펌프와 밸브가 포함되어 있으며, 식 (3)와 같이 특성 곡선이 입력된다.
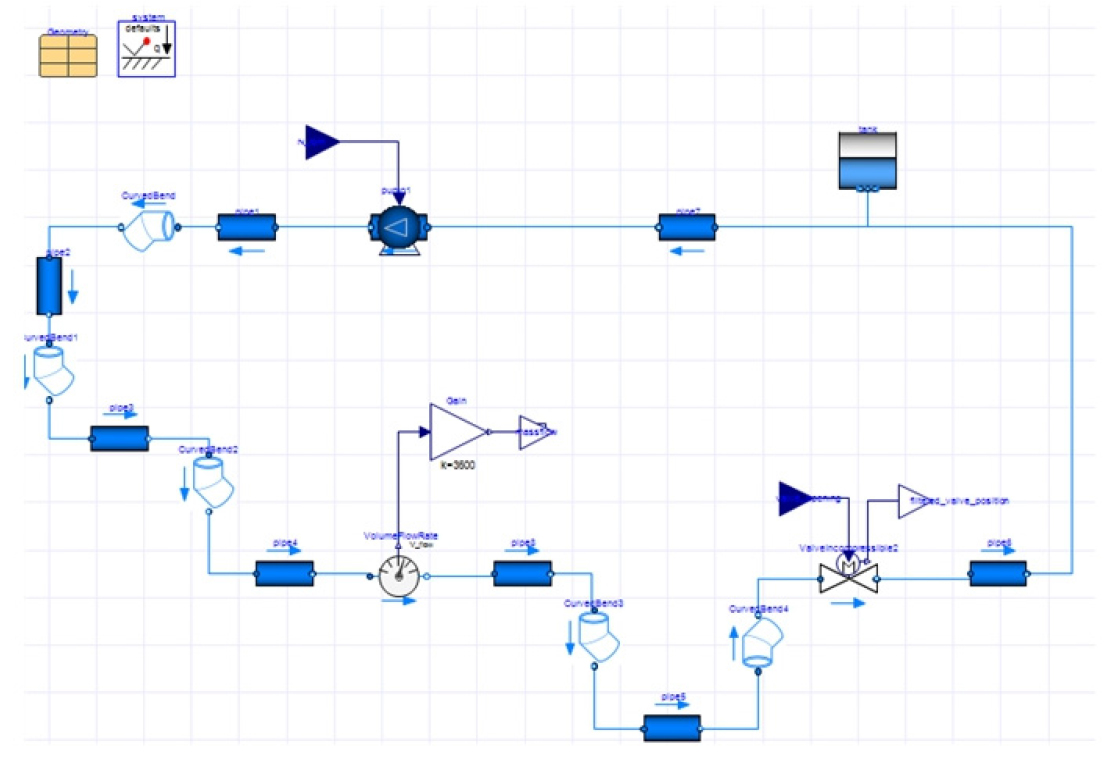
Table 4.
List of input & output parameter for Modelica model
| Input Parameter List | Output Parameter List |
| Valve Opening [%] | Mass flow rate [CMH] |
| Pump RPM [RPM] |
여기서 는 펌프 양정, 와 는 유량 그리고 는 밸브 개도율을 의미한다. 특성 곡선 계수는 부품 제조사에서 제공되는 성능 지표를 기반으로 초기값을 설정하였으며, 이에 대한 자세한 파라미터 정보는 Table 5에 나열되어 있다.
Table 5.
List of characteristic parameters for Modelica model
2.4 통합 시뮬레이션 모델 개발
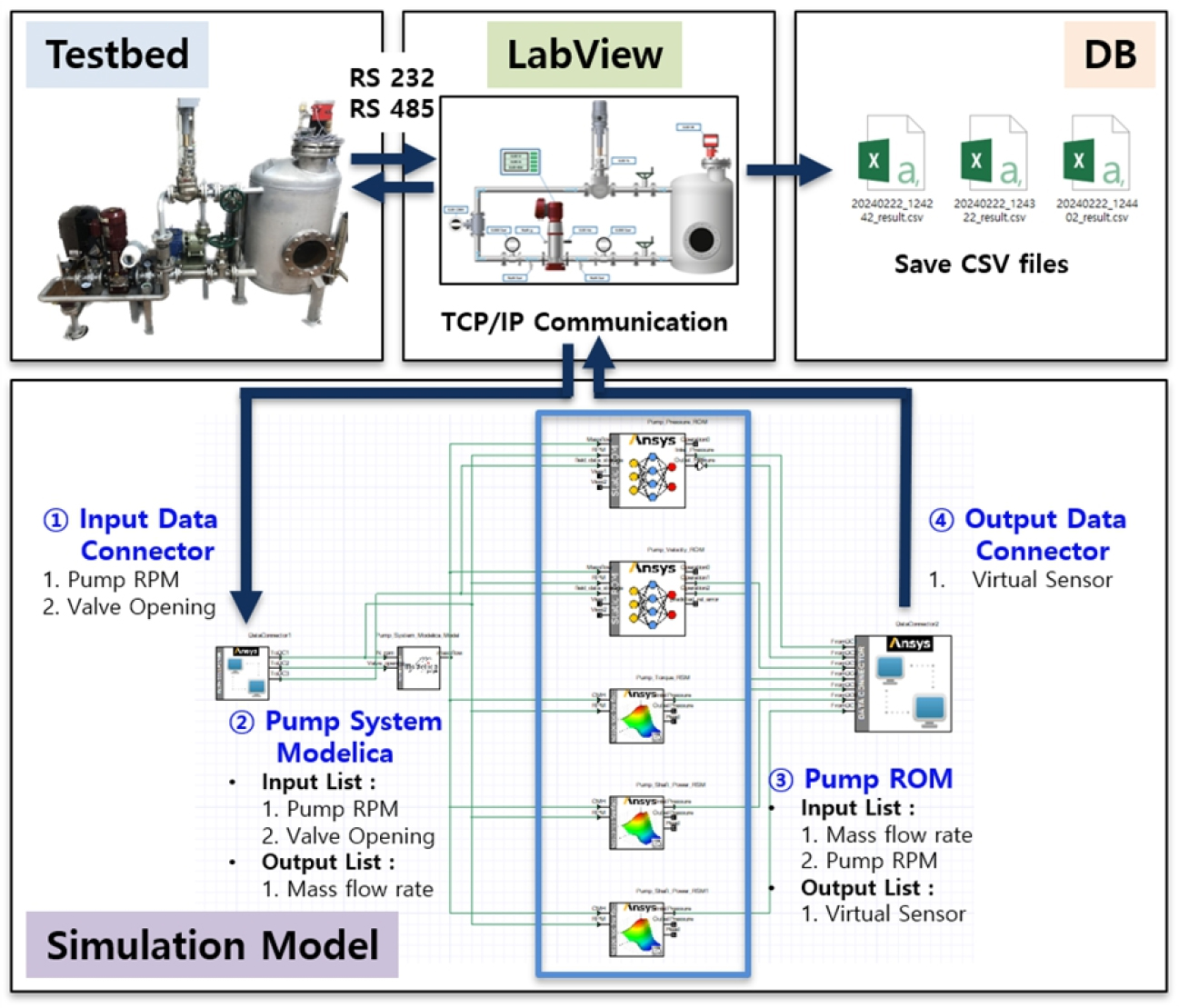
본 연구에서는 Modelica 모델과 ROM을 활용하여 펌프의 디지털트윈을 구축하는 과정을 진행했다. 이를 위해 ANSYS Twin Builder를 사용하여 통합 시뮬레이션 모델을 개발하였다. Fig. 9은 실제 펌프 시스템 테스트베드와 통합된 시뮬레이션 모델의 연결 구성도를 보여준다.
실제 펌프 시스템에서의 운영 데이터는 RS 통신을 통해 LabView로 전송되고, 이는 통합 시뮬레이션 모델의 입력 데이터로 활용된다. 통합 모델은 TCP/IP 통신을 통해 받은 데이터를 기반으로 실시간 해석을 수행하고, 생성된 결과를 다시 LabView로 보낸다. 이 데이터는 데이터베이스에 저장되어 사용자에게 가상센서 결과로 제공되며, 이를 통해 펌프 시스템의 실시간 모니터링과 성능 예측이 가능하게 된다.
3. 베이지안 최적화(BO) 기반 모델 보정
3.1 Modelica 모델 파라미터 보정
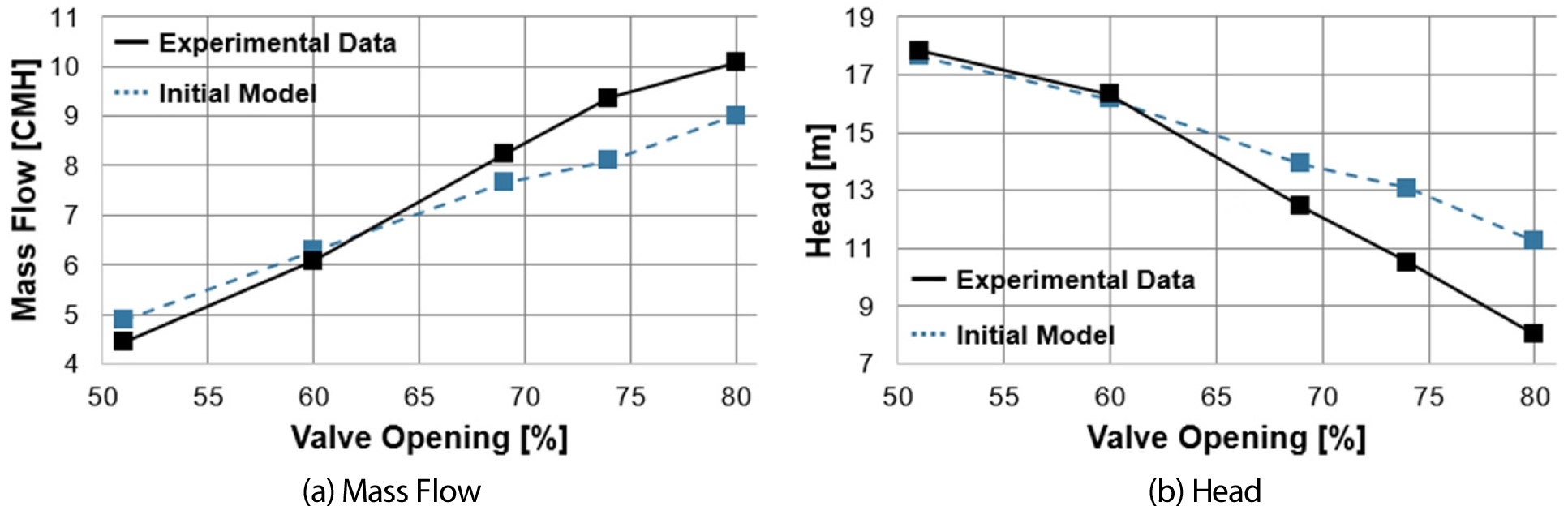
Fig. 10는 동일한 제어 조건(회전수, 밸브 개도율) 하에서 제조사에서 제공한 정격 성능을 적용한 초기 모델과 실제 테스트베드 측정치를 비교한 유량과 양정 그래프를 나타낸다. 정격 회전수에서 관찰된 유량과 양정에서 초기 모델값과 실험값 사이에 뚜렷한 차이가 확인되었으며, 이는 운영 환경 변화, 제품의 사용 기간, 제어 시스템의 정밀도에 의해 발생하게 된다. 이를 정확하게 예측하고 모델링하기 위해서는 실제 환경에서 얻어진 데이터를 바탕으로 광범위한 시뮬레이션을 수행해야 한다. 그러나, 이러한 대규모 시뮬레이션은 실행에 필요한 컴퓨팅 자원과 시간이 많이 소요되므로 상당한 계산 비용을 발생시킨다. 이를 해결하기 위해 본 연구에서는 계산 효율을 향상시키기 위한 방법으로 실제 테스트베드 측정치와 시뮬레이션 결과 간에 오류를 대리 모델로 구현하였다. 이 대리 모델은 오류를 추정하여 최적화 과정에서 필요한 시뮬레이션 횟수를 줄여, 계산 비용을 절감하는 동시에 Modelica 모델의 파라미터를 효과적으로 보정하는데 기여한다. 본 연구에서는 GPR(Gaussian Process Regression) 기반의 대리 모델을 BO를 적용하여 Modelica 모델 파라미터를 보정하였다. 이 방법은 적은 반복으로 수렴하며, 다중 입력에 대한 단일 출력 맵을 효율적으로 학습한다. 최적화 과정은 다양한 입력 변수에 대한 시뮬레이션 수를 줄이는 데 기여하며, 이는 정확도와 효율성을 향상시키는 핵심 요소이다[9]. 본 연구는 Modelica로 구현된 펌프 시스템 모델의 성능 정확도 향상을 목표로, 특히 펌프 회전 속도와 밸브 개도율과 같은 제어 변수에 따른 유량 예측에 중점을 두었다. 이를 위해, 수집된 유량 가상센서와 실제 측정값 사이의 오차를 줄이는 최적화 작업을 진행하였으며, 이는 Table 5에 나열된 핵심 파라미터들에 대한 최적화를 통해 이루어졌다.
본 연구에서 사용된 Modelica 모델의 결과는 로 표현된다. 여기서 파라미터 벡터 에 의해 매개변수화되고, 는 파라미터의 상한과 하한을 포함하는 집합을 나타내며, 는 제어 입력 데이터, 출력 벡터 는 시간 T 동안 시뮬레이션에서 계측된 모든 출력을 포함한다. 이 모델을 적합시키기 위해, 테스트베드의 측정 출력 데이터 를 사용하여 최적의 파라미터 세트 를 찾는 것이 목표이다. 이를 위해 설정한 최적화 문제는 다음과 같다.
여기서 는 모델 오차 함수로, 실제 와 예측 의 제곱 오차 합을 측정한다. 글로벌 최적화는 매개변수 공간 에서 샘플링을 통해 이루어진다. Modelica 모델 을 [0, T] 동안 시뮬레이션하여 를 얻고, 비용 를 계산하여 문제를 해결한다. 그러나 이러한 최적화 문제는 많은 수의 시뮬레이션 샘플이 필요하므로, 높은 차원의 매개변수 공간에서 샘플링 복잡성을 줄이기 위해 BO를 사용한다. 이 방법은 매개변수와 보정 비용 사이의 매핑에 대한 확률적 모델을 구축하여 매개변수 선택의 효율성을 높일 수 있다.
3.2 가우시안 프로세스 회귀(GPR) 기반 베이지안 최적화(BO) 구축
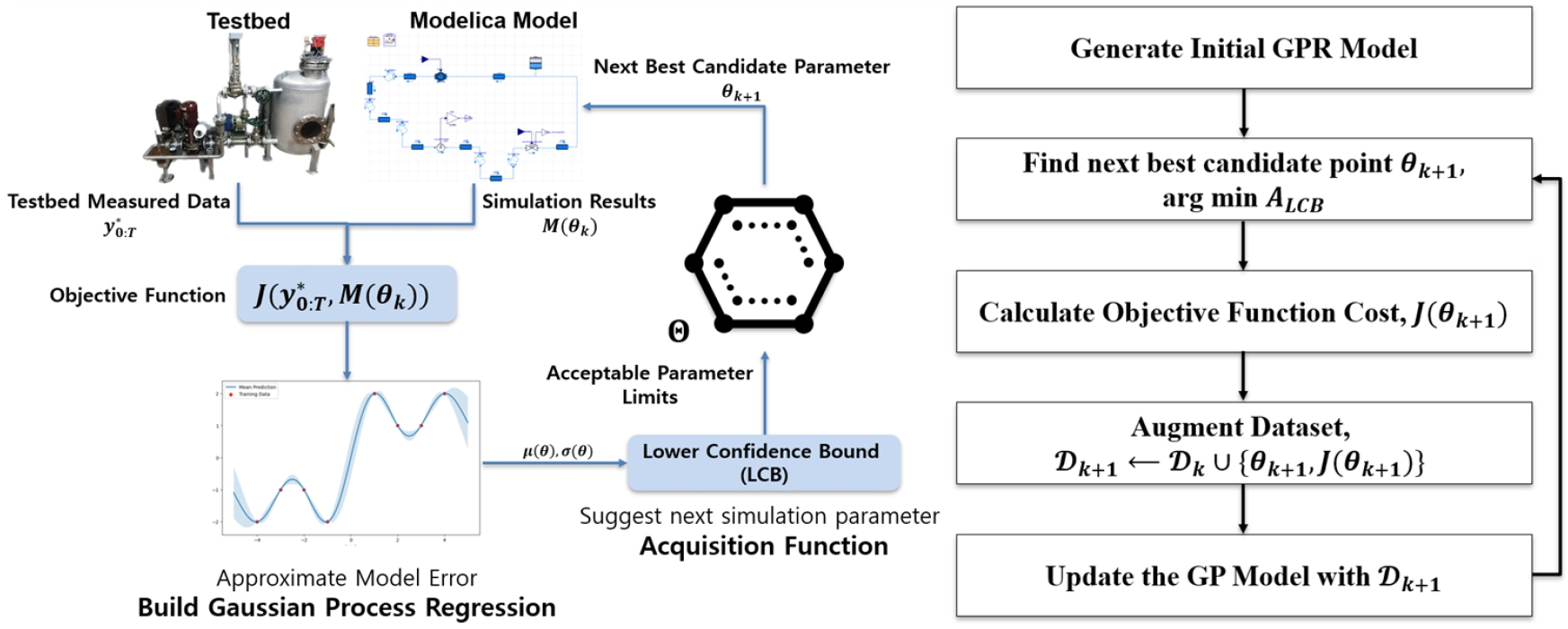
본 연구에서는 Fig. 11과 같이 구성된 물리 기반 모델 결과와 테스트베드 측정 간의 오차를 줄이기 위해 GPR를 활용한 BO 프로세스를 적용한다. GPR을 통해 모델 오차 함수 와 매개변수 𝜃 간의 관계를 학습하고, 이를 기반으로 오차 함수의 확률적 특성을 모델링한다. GPR 모델은 데이터에 가장 잘 부합하는 함수를 찾기 위해 가능한 함수들을 다양하게 고려한다. 가우스 분포를 가정한 상태에서, 함수의 공동 분포를 활용하여 데이터를 가장 잘 설명하는 함수를 추정한다. 이 과정에서 평균 함수와 kernel 함수를 사용하여 불확실성과 변동성을 포괄적으로 모델링할 수 있다. 샘플링된 데이터를 기반으로 최적화 과정을 거쳐 오차 함수 를 추정하며, 이를 통해 모델의 정확도를 개선한다.
여기서, 는 측정 잡음을 나타낸다. 평균 함수 와 공분산 함수 는 다음과 같이 정의한다.
평균 함수 는 0으로 가정하고, 인 Matérn 공분산을 사용하였다. 이 커널은 제곱 지수 커널 대비 현실적인 매끄러움을 제공하며, 비선형적이거나 불규칙한 데이터에 대한 예측력이 우수하여 과적합을 방지하는 데 유리하다. 여기서 는 출력의 분산 매개변수이며, 은 길이 스케일(length scale)로 데이터 포인트 간의 상관관계 변화의 속도를 나타낸다. 하이퍼 파라미터는 식 9의 최대 우도 추정(Maximum Likelihood Estimation)을 통해 최적화된다.
여기서 은 커널 행렬이며, 그 계산은 커널 함수와 하이퍼 파라미터에 의존한다. 우도 함수는 일반적으로 Non-Convex 형태로, 최적화 알고리즘을 통해 하이퍼 파라미터를 조정함으로써 최적의 성능을 달성할 수 있다.
BO 알고리즘에서는 탐색과 활용 사이의 균형을 조절하기 위해 획득 함수(Acquisition Function)가 사용된다[10]. 본 연구에서는 획득 함수로 LCB(Lower Confidence Bound)를 채택하였다.
여기서 로 탐색과 활용 사이의 균형을 관리하는 매개변수이며, 𝜅가 낮을수록 활용을 우선시하게 된다. 최적화 과정 중 탐색에 더 큰 가중치를 부여하기 위해 𝜅=2로 설정하였다. BO에서는 LCB를 최소화하는 지점을 신규 샘플 포인트로 선택하여, 불확실성이 높지만 잠재적으로 높은 성능을 보일 수 있는 지점을 탐색한다. 반복적인 절차를 통해 알고리즘은 보다 정확한 예측 모델을 구축하고, 최종적으로 최적의 해를 찾아낸다.
3.3 대리 모델링 기법
본 연구에서는 앞서 제안된 GPR-BO 접근법과 다른 전통적인 대리 모델링 기법인 MLR(Multidimensional Linear Regression), PRSM(Polynomial Response Surface Model), 그리고 RBF(Radial Basis Function)을 비교함으로써, 최적화 문제에서 GPR-BO의 성능을 평가하고자 한다. 이러한 비교를 통해, 각 모델링 기법의 장단점을 분석하고 복잡한 최적화 문제에 대한 가장 효율적인 접근 방식을 파악할 수 있다.
3.3.1 MLR(Multidimensional Linear Regression)
MLR은 다변량 데이터에서 변수 간의 선형 관계를 모델링할 때 널리 사용되는 기법이다. MLR은 기본적인 선형 회귀 방정식의 확장 형태로, 두 개 이상의 독립 변수를 사용하여 하나의 종속 변수를 예측한다. 이 방법은 데이터 세트 내에서 독립 변수와 종속 변수 사이의 선형적인 상호작용을 탐색하고 이해하는데 유용하다. MLR의 일반적인 수학적 모델은 다음과 같은 형태를 가진다.
는 종속 변수(예측 변수)이고, 은 독립 변수(입력 변수)이다. 은 절편(intercept)을 나타내며, 은 각 독립 변수의 가중치이다.
3.3.2 PRSM(Polynomial Response Surface Model)
PRSM은 복잡한 데이터의 패턴과 관계를 모델링하는 데 널리 사용되는 대리 모델링 기법이다. 이 모델은 선형 모델의 한계를 넘어 비선형 관계를 포착하고, 다변수 데이터에 대해 다항식 함수를 사용하여 종속 변수와 독립 변수 간의 관계를 설명한다. PRSM의 2차 다항식 형태는 다음과 같다.
와 는 각각 독립 변수와 변수들 간의 상호작용에 대한 계수이다.
3.3.3 RBF(Radial Basis Function)
RBF은 복잡한 다변수 데이터의 비선형 패턴을 모델링하는 데 효과적인 기법이다[11]. 이 방법은 중심점을 기반으로 하는 레이디얼 베이시스 함수를 활용하여, 데이터 포인트 간의 거리에 따라 값을 변화시키는 방식으로 작동한다. 이를 통해 매우 유연하며, 데이터의 복잡성과 다양성을 반영할 수 있는 맞춤형 모델을 구축하는 데 유용하다.
여기서 는 각 RBF의 가중치이며, 𝜙는 레이디얼 베이시스 함수로, 일반적으로 linear, Gaussian, multi-quadratic, thin-plane spline 등이 사용된다. 는 입력 벡터 와 중심점 간의 유클리디언 거리이다.
3.4 대리 모델별 최적화 성능 비교
본 연구에서는 펌프 시스템 Modelica 모델에 대하여 무작위로 생성된 입력 데이터를 사용하여 400개의 Training Data Sets를 수집하였다. 비교의 공정성을 위해, GPR-BO, MLR, PRSM 및 RBF 모델을 모두 동일한 훈련 데이터를 기반으로 구축하였고, 이 과정은 Python Library인 Scikit-learn을 활용하였다. 이렇게 구축된 모델은 Fig. 12에 표시된 바와 같이 최적화 과정을 거쳤으며, L-BFGS-B Optimizer을 사용하여 대리 모델의 오차를 최소화하는 지점을 찾는 방식으로 진행되었다. 이 최적 지점에서 시뮬레이션을 수행한 후 오차 함수를 업데이트 하는 절차를 총 200회 반복하였으며, 각 iteration 별 최적화 결과를 Table 6 및 Fig. 13에 나타냈다. Fig. 13에서 에러 함수의 최적화는 GPR-BO 모델이 MLR, PRSM 및 RBF 보다 빠르고, 안정적으로 수행함을 보여준다. 이러한 결과는 GPR-BO의 고도의 유연성과 복잡한 데이터 구조에 대한 강력한 모델링 능력을 통해 오차 최소화와 같은 최적화 문제에 적합할 수 있음을 나타낸다. 최종적으로, GPR-BO 과정을 통해 도출된 최적의 파라미터 추정치는 Table 7에 나타나 있다. 이 최적화된 파라미터들은 펌프 모델의 성능을 크게 향상시키고, 전체 시스템의 운영 효율성을 개선하는 데 기여한다.

Table 6.
Comparison of Optimization Performance by Surrogate Models
| Model | Optimizer | Min Error Result | Best Seen Iteration |
| GPR-BO | L-BFGS-B | 1.49 | 72 |
| MLR | 2.31 | 55 | |
| PRSM | 2.32 | 68 | |
| RBF | 1.59 | 200 |
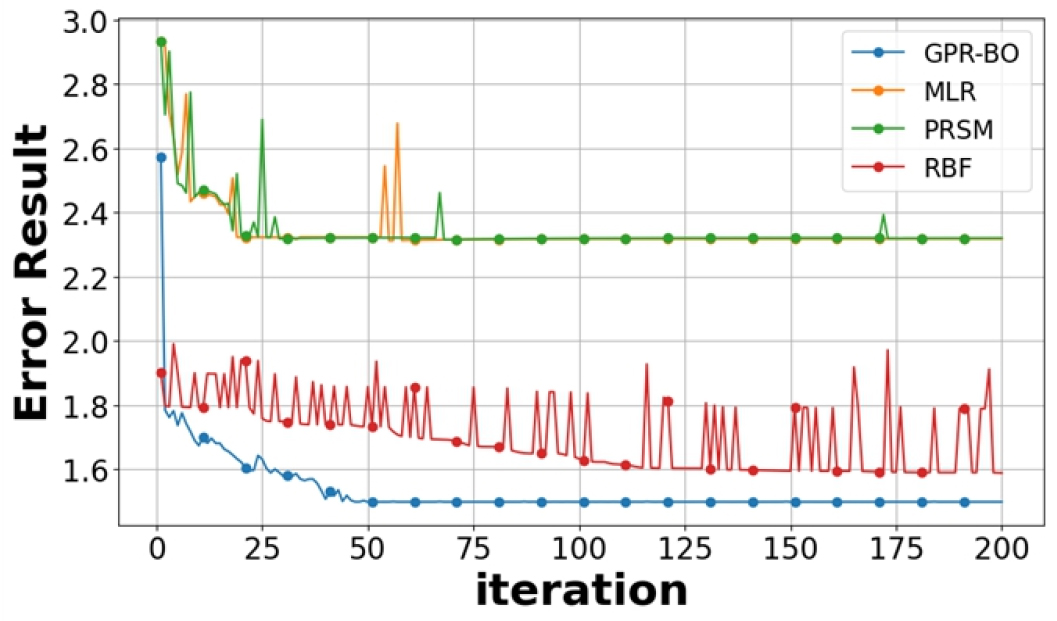
Table 7.
Pump system Modelica model parameter calibration results list based on GPR-BO
4. 실험 및 결과
4.1 펌프 성능 시험 및 시뮬레이션 결과 비교
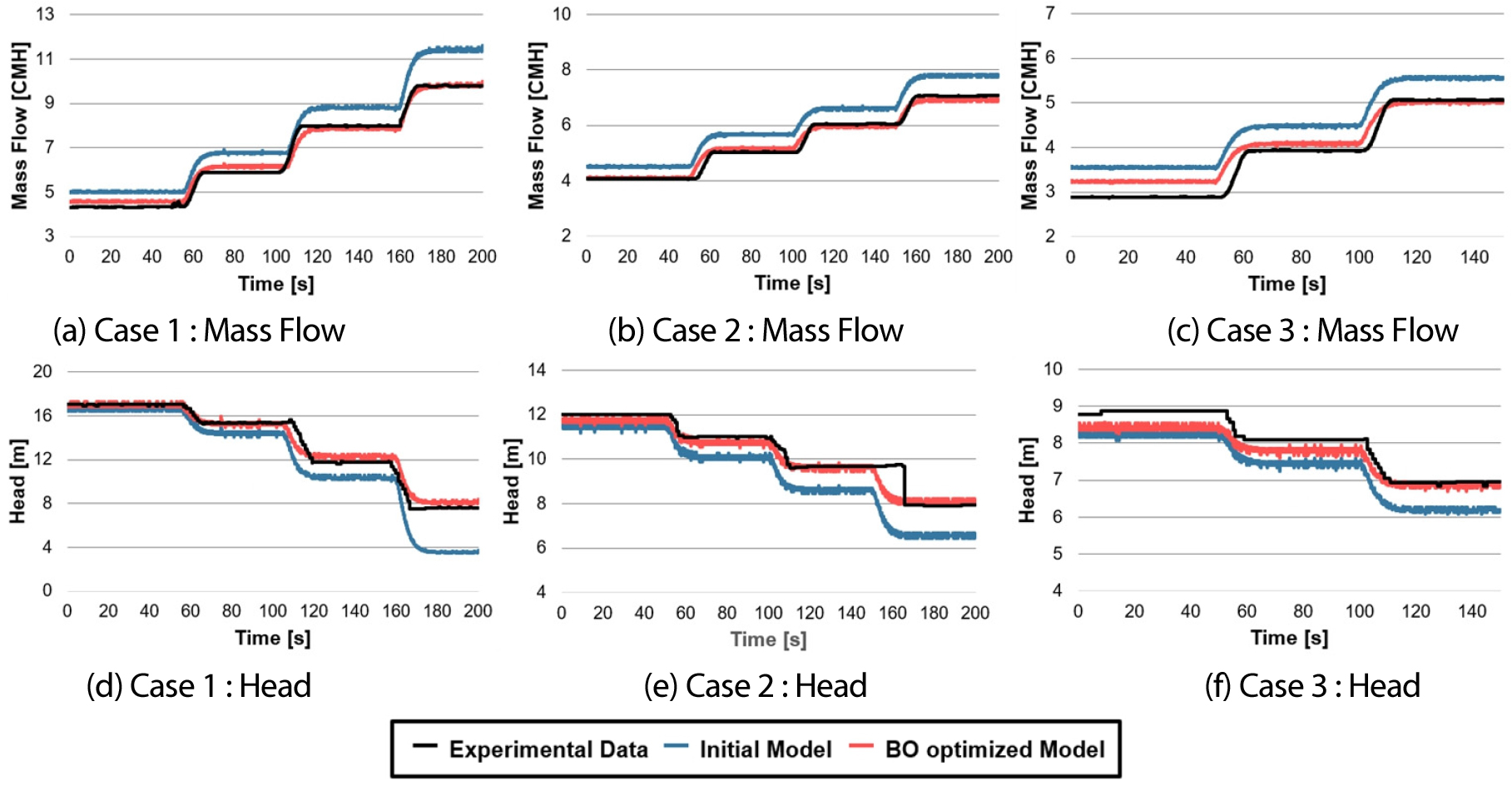
제시된 Fig. 14는 펌프의 유량과 양정에 대한 실험 데이터 및 GPR-BO 기법 적용 전/후 모델의 예측 결과를 비교한 그래프이다. 이를 통해, 펌프의 다양한 밸브 개도율 조건에서의 성능 예측 정확도가 어떻게 향상되었는지 명확히 확인할 수 있다.
유량 그래프에서 GPR-BO를 적용하기 전의 초기 모델(파란색 점선)은 실제 실험 데이터(검은색 실선)와 다른 경향이 나타났음을 보여준다. 이는 모델의 초기 설정이 실제 운영 조건을 완전히 반영하지 못했음을 나타낸다. 그러나 GPR-BO 후의 모델(빨간색 점선)은 실험 데이터에 훨씬 근접한 예측을 제공하며, 평균 오차가 7.74%에서 2.87%로 상당히 감소했음을 나타낸다.
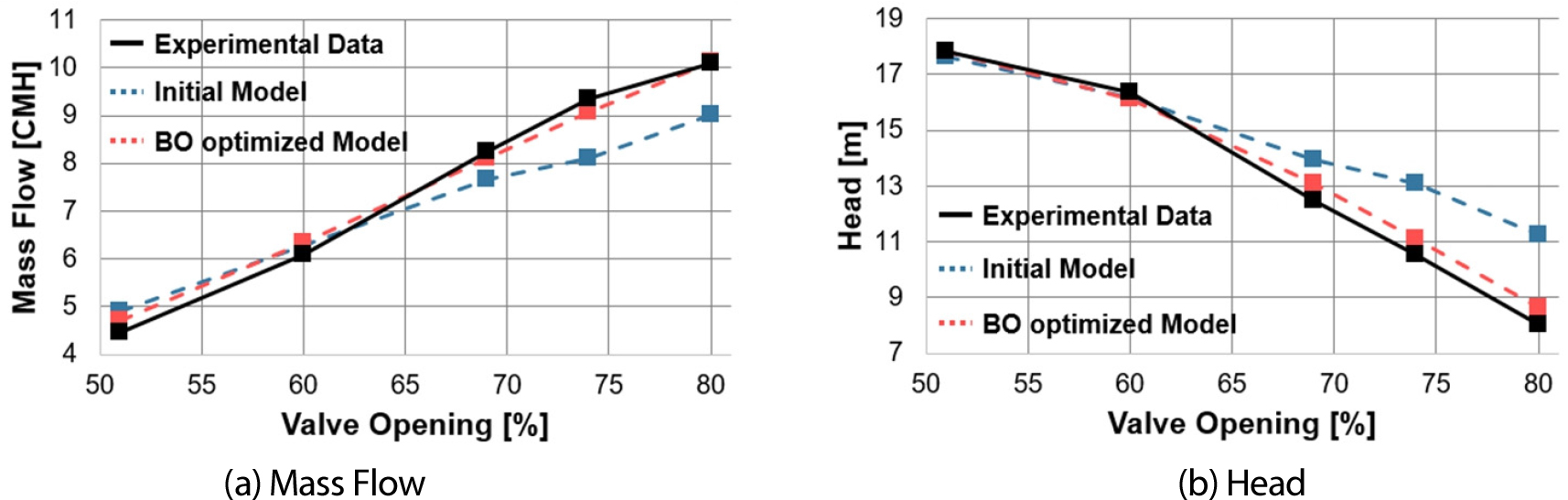
양정 그래프 역시 유사한 형상을 보인다. 최적화 전 모델은 실험 데이터와는 다른 양정 값을 예측했으나, BO 적용 후 모델은 실험값과의 평균 오차를 13.57%에서 3.58%로 줄였다. 이를 통해 GPR-BO 프로세스가 펌프의 수력 성능 예측에 있어 모델의 정확도를 크게 개선하여 실제 펌프 운영 특성을 정확히 반영할 수 있음을 확인시켜 준다.
4.2 실시간 펌프 시스템 성능 예측 결과 비교
Table 8은 BO를 통해 펌프 시스템의 실시간 성능 예측을 얼마나 개선할 수 있는지를 보여준다. 제시된 표는 BO 최적화가 적용되기 전후의 모델 예측 결과와 실제 실험 데이터를 비교하여, 펌프의 양정 예측에 있어서 BO의 효과를 정량적으로 평가한다.
Table 8.
Experimental conditions and head predictions comparison
실험 조건은 세 가지로 구분되며, 각각 다른 회전수(RPM)와 밸브 개도율로 설정되었다. 이 조건들 아래에서 실시간으로 수행된 시뮬레이션은 펌프의 현재 성능 상태를 예측하는 데 활용되었다. 실험 계측값과 GPR-BO 전후의 결과를 비교함으로써, BO가 모델의 예측 능력을 얼마나 향상시킬 수 있는지를 명확하게 확인할 수 있다.
GPR-BO 적용 전의 초기 모델은 실험 데이터에 비해 상당한 오차를 보였으나, BO를 적용한 후의 모델은 모든 실험 케이스에서 오차가 크게 감소하였다. 오차율은 BO 적용 전 최대 평균 14.80%에서 BO 적용 후 3.48%로, 양정 예측에 있어서 특히 두드러진 개선을 보였다. 이러한 개선은 GPR-BO가 모델의 정확성을 크게 향상시킴으로써, 다양한 운영 조건에서의 신뢰할 수 있는 예측을 가능하게 했다는 것을 의미한다.
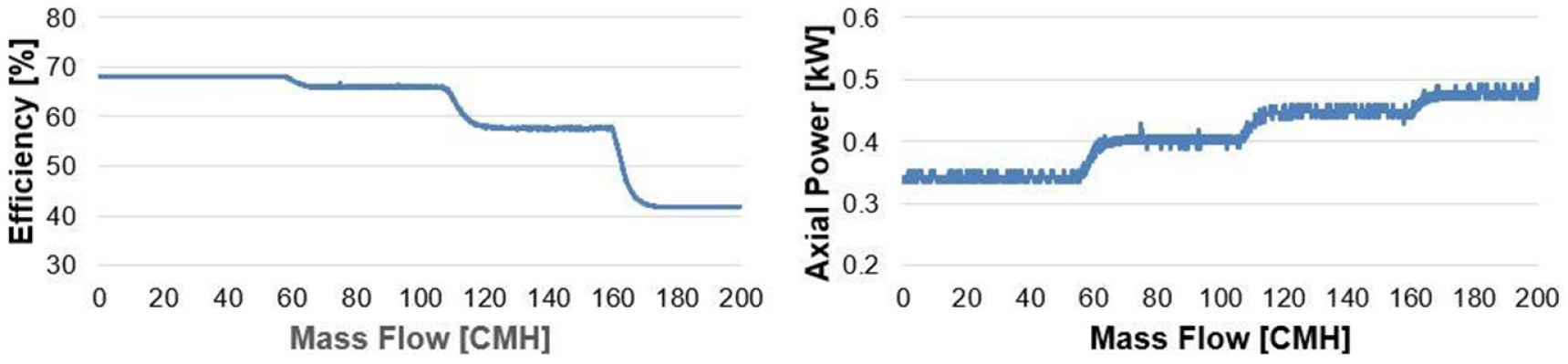
본 연구에서 제시된 Fig. 15와 Fig. 16은 펌프 성능 모델의 실시간 예측 능력을 입증한다. Fig. 15에서는 회전수와 밸브 개도율의 변화에 따른 펌프의 반응을 분석하였으며, BO을 적용한 모델(빨간색 실선)이 초기 모델(파란색 실선)에 비해 실험 데이터(검은색 실선)와 상당한 일치를 보임으로써, 다양한 운영 조건에서의 예측 정확도가 향상되었음을 나타낸다. 더불어, Fig. 16은 Case 1의 효율과 축동력과 같은 펌프의 핵심 성능 지표가 실시간으로 어떻게 변화하는지를 계산하여 보여주고 있다. 이 결과들은 BO를 통해 최적화된 모델이 운영 환경의 동적 변화에 효과적으로 대응할 수 있으며, 정확하고 신뢰할 수 있는 성능 예측을 제공할 수 있음을 나타낸다.
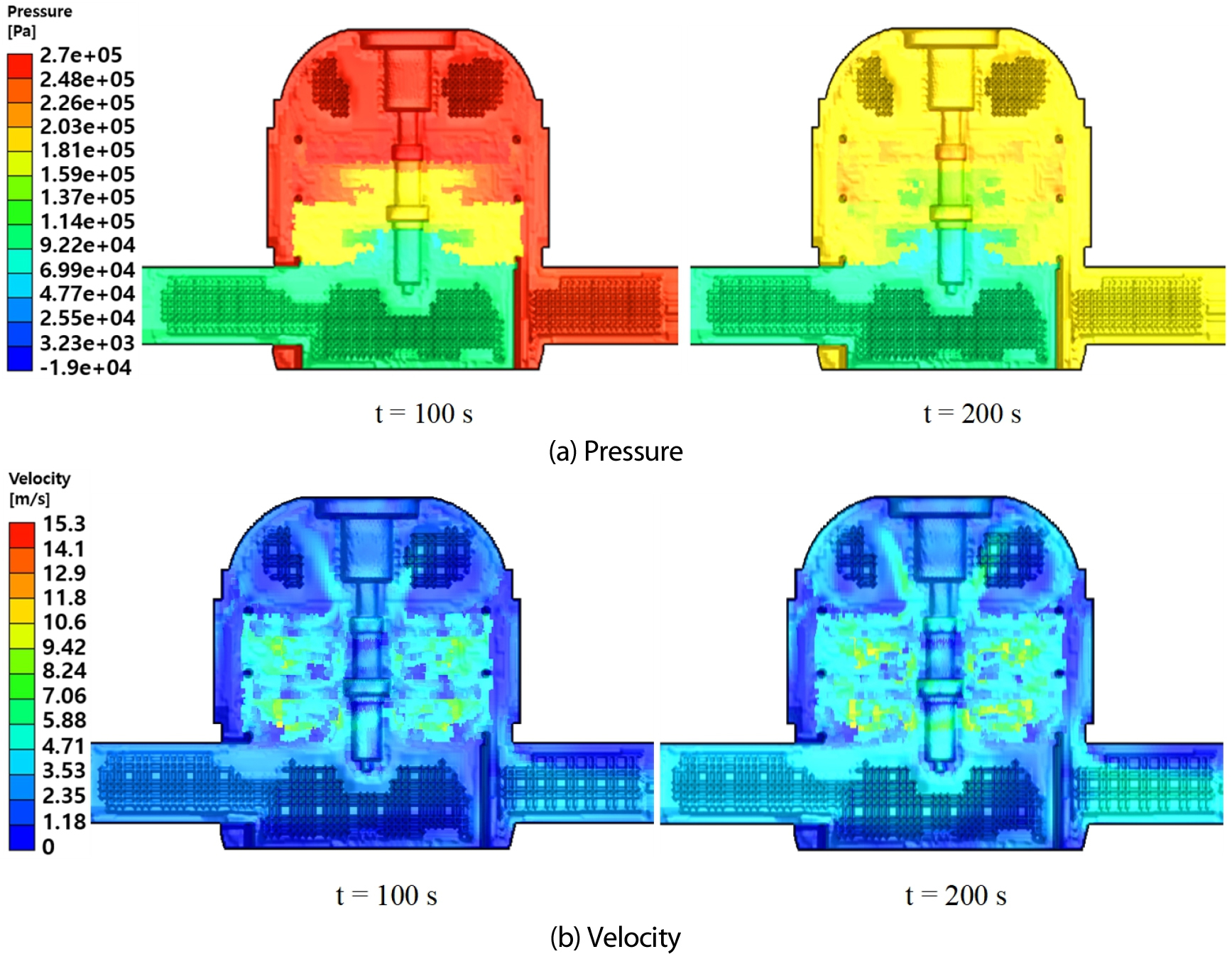
이 연구에서 개발된 물리 기반 시뮬레이션 모델은 ROM을 활용하여, Fig. 17와 같이 펌프 내부의 압력 및 속도 분포 가상센서 데이터를 시각화한다. 이 모델은 실시간 데이터를 통해 성능 지표를 모니터링하고, 운영의 효율성을 크게 향상시킬 수 있는 중요한 정보를 제공한다. 이 연구 결과를 바탕으로, 성능 최적화와 운영 전략을 더욱 정교하게 개발할 수 있으며, 이는 펌프 시스템의 에너지 효율성을 증진시키고 운영 비용을 절감하는 데 중요한 기여를 할 것으로 기대된다.
5. 결 론
본 연구는 물리 기반 시뮬레이션을 통해 원심 펌프 시스템의 실시간 성능 분석을 가능하게 하는 모델을 구축하는 것을 목표로 하였다. 이를 위해 Modelica와 ROM을 활용하여 시뮬레이션 모델을 개발하고, GPR 기반의 데이터 보정 방법을 통해 매개변수 최적화를 수행하여 예측 정확도를 향상시켰다. 주요 결과는 다음과 같다.
1.펌프 내부의 수치해석을 진행하였으며, 실제 양정 계측값과 비교하여 최대 4.3%의 오차 내에서 일치하는 결과를 확인하였다. 이러한 수치해석 결과를 바탕으로, 19개의 케이스 중 16개를 사용하여 ROM을 구축하고, 나머지 3개 케이스로 검증을 수행하였다. ROM 검증 결과, 축소 오차는 최대 0.26%, 평균 오차는 약 1054 Pa로 확인되었으며, 압력, 속도 분포, 효율 및 축동력과 같은 핵심 성능 지표를 예측할 수 있는 ROM/RSM 구축하였다.
2.Modelica와 ROM을 통합한 물리 기반 시뮬레이션 모델을 활용해 BO 기반의 매개변수 보정을 실시했다. 이 과정을 통해, 시뮬레이션 모델의 유량 및 양정 예측 최대 평균 오차를 각 2.87%, 3.58%로 감소시켰다. 이러한 정확도 향상은 모델이 실제 운영 데이터를 더 잘 반영하게 하여, 펌프 시스템의 성능 예측을 보다 신뢰할 수 있게 만들었다.
이러한 결과는 물리 기반 시뮬레이션을 통해 실시간으로 펌프 시스템의 운영을 보다 효율적으로 관리하기 위한 유용한 정보를 제공한다. 향후 연구에서는 실시간 에너지 수요 충족을 위한 최적 제어 전략과 구성 요소의 수명 예측에 관한 연구를 진행할 예정이다.
